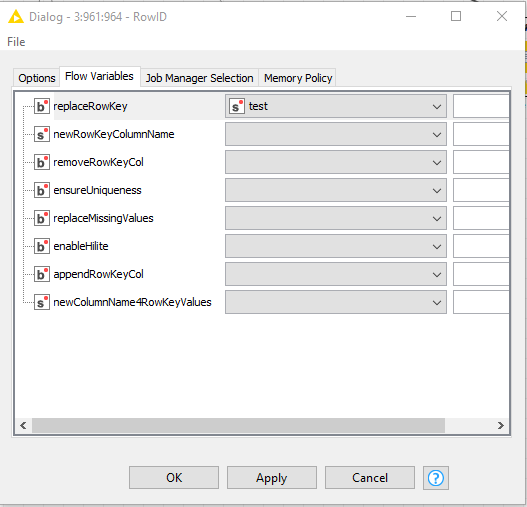
I would like to pass a RowID from one node (‘test’ in the image below) as variable to a RowID node in a parallel branch, to replace the current RowID with the variable value. However the RowID node appears to only accept variables of type ‘b’, whereas the variable is in string format.
Use the newRowKeyColumnName instead, which accepts string values. The replaceRowKey takes a boolean value because it corresponds to the checkbox on the configuration dialog.
Hi @evert.homan_scilifelab.se , the “replaceRowKey” is basically a check box for Yes/No or True/False or Checked/Unchecked, that is why it’s of type [b] for boolean.
Graphically, this tab reflects what’s in the Options tab:
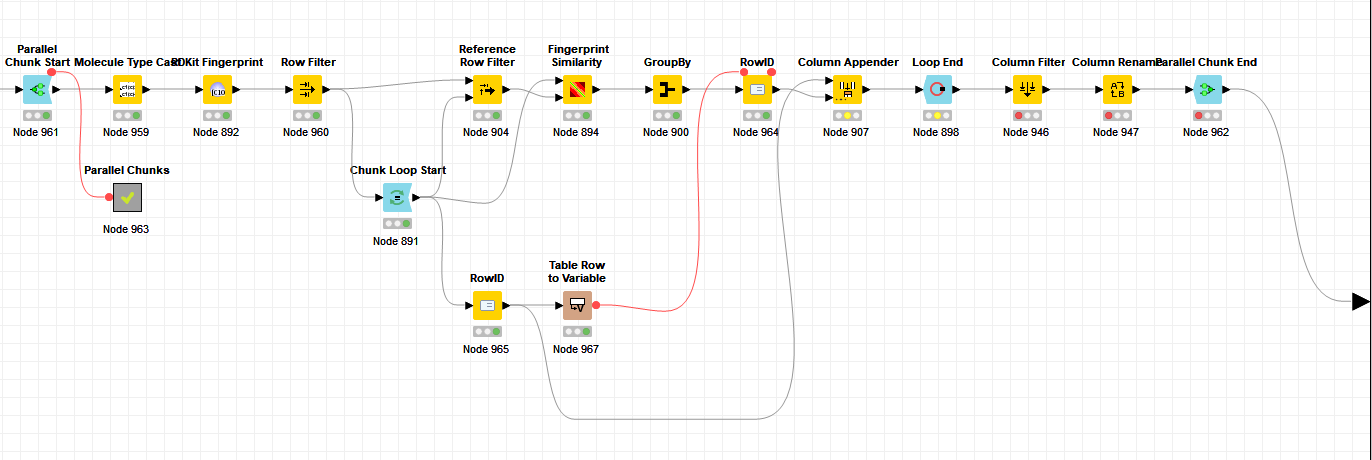
In the workflow I want to calculate the chemical similarity of each structure of 88K structures with the rest. This calculated similarity needs to be appended to the input table based on identical row numbers. This can easily be done by resetting the RowIDs of both incoming streams, however in order to speed up things I would like to wrap the whole workflow in a parallel chunk loop. And this starts to complain when it wants to merge all results from the parallel chunks, because it encounters duplicate RowIDs.
The GroupBy node in the middle identifies the maximum similarity to any other structure for each row but also generates the Row0 ID. So I would like to change the RowID at this point back to make it identical to the RowID of the ChunkLoopStart, since the Parallel Chunk Loop can’t handle duplicate RowIDs.
I got the context of the workflow, but I am not sure I quite got what you are trying to do. Are you trying to relay which rows are which rows after the GroupBy?
Perhaps it’s easier if you could show us what’s the output of Node 965 and Node 900? And also show us what the expected result you want from a sample of the output from these 2 nodes?
Sorry, got stuck in catering etc. I am indeed trying to relay which rows are which after the GroupBy.
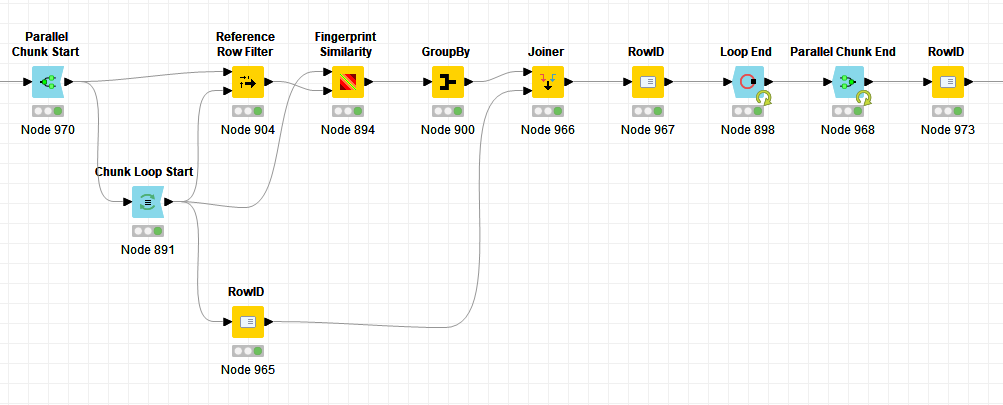
However I managed to get it to work after som refurbishing, using a Joiner and an additional RowID. It also appears to be critical to tick the ‘Add Chunk Index to RowID’ box under the Parallel Chunk End node settings in order to avoid duplicate RowIDs between parallel chunks.
RowID (965) generates a column with the original RowID, which is added by the Joiner (966). RowID (967) then sets the actual RowID back to this original value. After all parallel chunks have been collected the RowIDs have chunk numbers added to them. These are then renumbered to the original RowIDs once more using RowID (973).
It sometimes is a bit of a puzzle to solve (which is a large part of the fun using KNIME) but every time I am amazed with what can be accomplished with KNIME without any programming.
Hi @evert.homan_scilifelab.se , yes you would have to eventually Join to do the relay, but I was trying to understand why you were trying to relay based on the RowID, because a GroupBy would usually aggregate (similar to de-duping with the duplicate node), meaning the “chosen” original RowID for the aggregated item does not reflect the same records from the input data and the GroupBy result - again not easy on my part to determine what the GroupBy is actually doing without seeing the data
But I’m glad to hear that you were able to resolve your issue with the configurations you used and shared
The GroupBy node finds the row with the highest structural similarity, by aggregating on maximum similarity. Since the output has only one row, with RowID 0, I cannot match this with the original RowID of the compound that was searched against.