@bowlinglm I extracted the tables with the help of the camelot-py package and stored them as .parquet files in a sub-folder.
Then I used KNIME to extract the headers and add some information. There are some tables at the end of the PDF that would have different structures - you might have to deal with them separately. At the moment they will just be skipped.
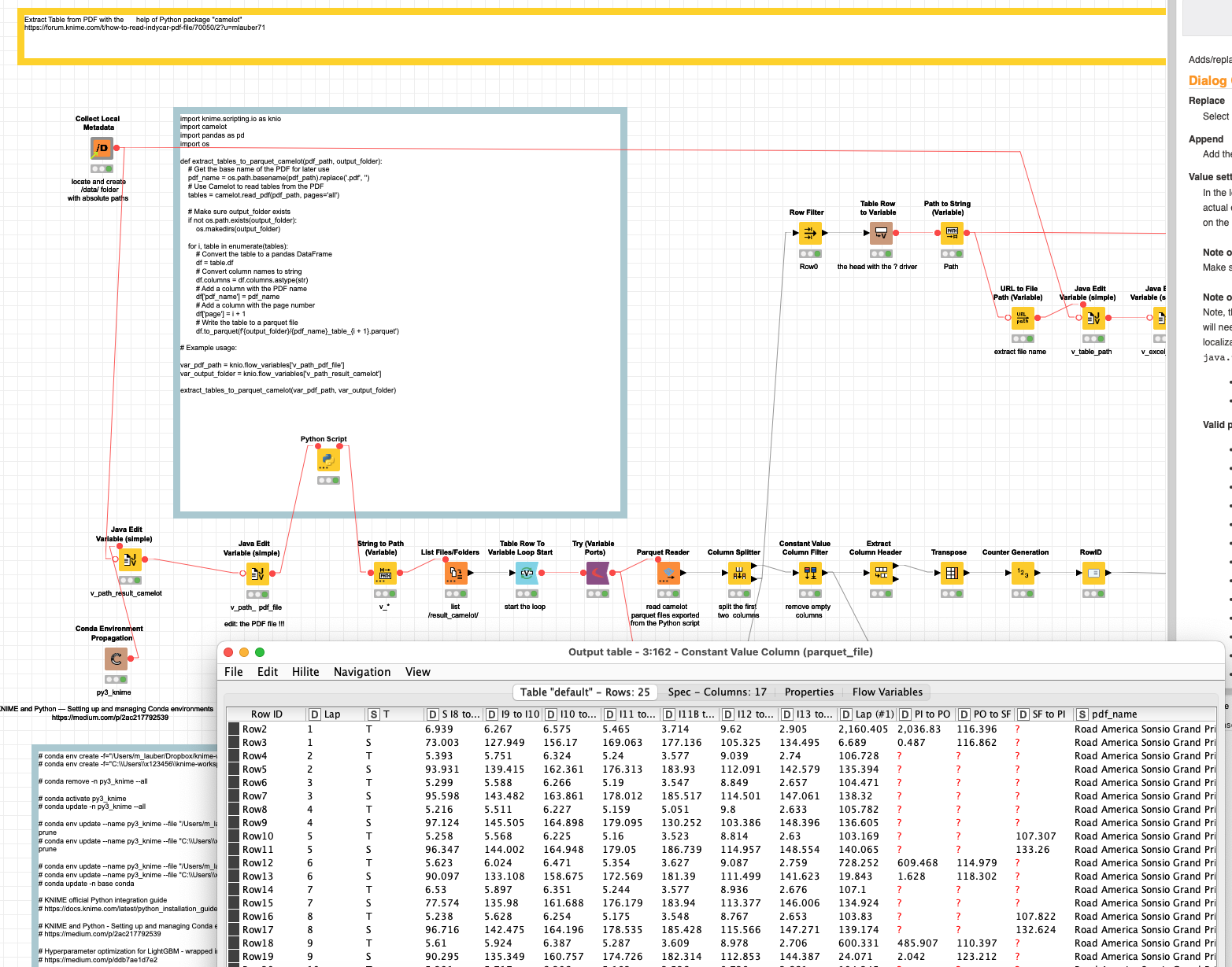
The workflow needs some polishing and currently the Python is done in a Jupyter notebook in the /data/ subfolder. edit I have included that in the workflow:
For other attempts with extracting tables from PDF there was this challenge: