Hi,
I am new using Selenium nodes and I could not find the answer using the search option, so I am asking here.
I am using selenium node to download pdfs from a list of URLs. I tried before using the http and download/upload nodes and could not get it work because the URLs point to the renderer.
In Selenium I managed to do it by including the option in chrome
Chrome Options (object)- prefs (object)- plugins (object) - always_open_pdf_externally( Boolean)-True
Now I would like to change the path to which each file is saved, and if possible also the name of the file.
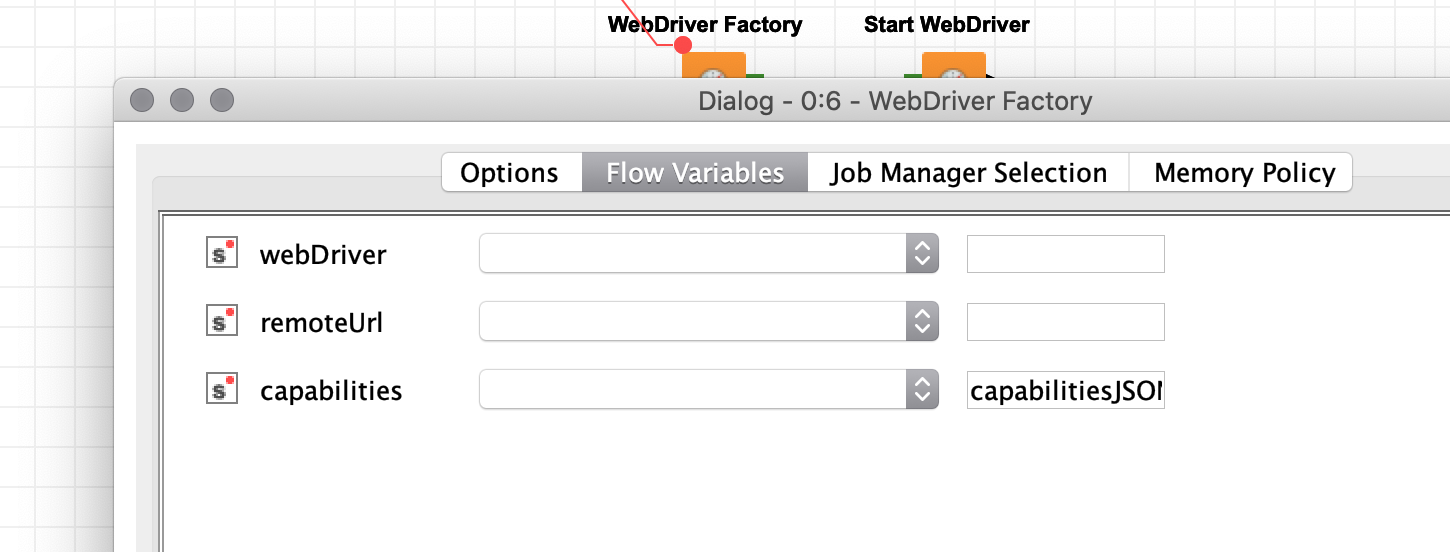
I saw that I can define the capabilities via a Flow Variable. What format must this Flow Variable have?
you can simply pass them as JSON-formatted string (which you can create using a plethora of ways). I’ve uploaded a very simple example workflow to my NodePit Space for you where I simply put the JSON into a Container Input (JSON) node:
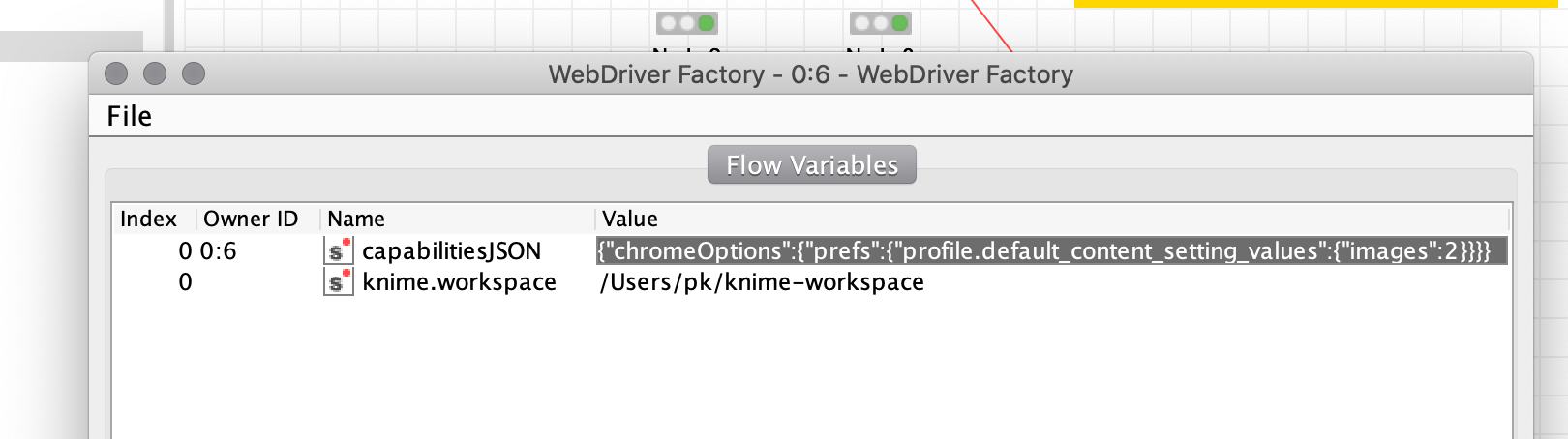
Protip: To get an idea how the stored capabilities look like, you can make the settings in the node as desired, then switch to the “Flow Variables” tab (hey KNIME, this entire tab is a utter UX nightmare!), enter a FW name into the blank input field, run the node and check the output:
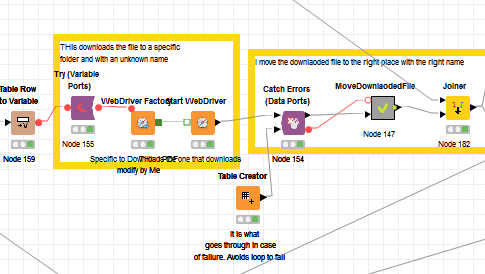
I managed to get it work with your example. Thanks a lot, but one thing that I could not do is how to name the file before downloading. The problem is that the file name is random, so I cannot anticipate it, that´s why I want to name it before downloading. Actually, after reading some posts, I understood it is not possible in Selenium to name the file while downloading? Is that true?
I also tried using the prompt screen of chrome, the idea was to use the alert node to get the info in that screen but the node alert did not seem to pick it up.
I have found a workaround, which is listing the files in the download folder, wait until they are downloaded, etc. etc. and then rename them. The limitation of this is that it does not allow me to download more than one at the time in the same folder.
would you be able to share your workflow so that I can have a look (alternatively via email to mail@seleniumnodes.com)? This would make it easier to give any suggestions here.
(1) Bad news for me: I cannot sell you Selenium Nodes license, as you do not need them here
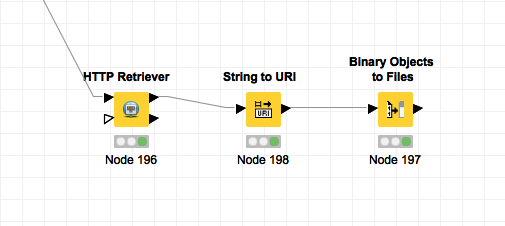
(2) Good news for you: You can easily do this with good ol’ HTTP Retriever from Palladian to download the PDF and a Binary Objects to Files node which writes the downloaded result to the file system. The essence is as follows:
You need the String to URI node to create an URI from the file path where the result file should be written to (see here).
This way to workflow is much, much simpler.
I’ll send you the modified workflow via email (you’ll need to change the file paths again, as I needed to adapt them to my local machine).