I would use the KNIME Workflow Executor for Apache Spark. Is there a example workflow or a description for this usage?
I’ve installed the KNIME Workflow Executor for Apache Spark (Preview). For our hadoop cluster I used the Create Spark Context (Livy) Node, Spark Version 2.3, and HDFS Connection Node, HDFS 3.1.1.
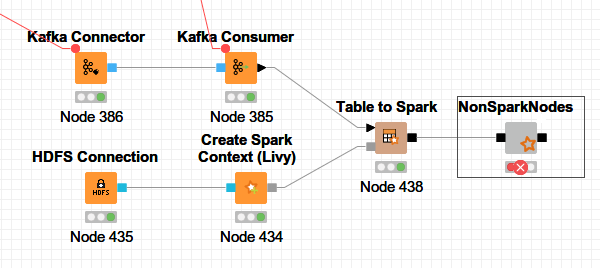
I’ve build a small workflow with Non-Spark-Nodes inside a wrapped Metanode.
Spark Data Ports (in and out).
Inside the Metanode a Spark to Table Node and a Table to Spark Node and some Non_Spark-Nodes.
we are working on documentation for that extension, my apologies for the unclarities. The extension is currently still a preview.
It is rather intentional that spark.knime.knosp.knimeDir is not configurable on a per-node basis but should be done with cluster-wide spark settings. The background is that KNIME Workflow Executor for Apache Spark requires a KNIME installation on every single one of your cluster nodes. The Spark conf setting spark.knime.knosp.knimeDir needs to be pointed to the KNIME folder on your cluster nodes (and it needs to be the same on all nodes).
If you are on Cloudera CDH, we provide a parcel and CSD for Cloudera Manager in order to fully automate the installation (for Hortonworks HDP, we currently do not provide any automation.)
If your cluster does not have internet access you also have to download the correct parcel file. The RHEL 7 (for example) parcel and corresponding sha file can be downloaded here:
By the way: If you just want to try out the extension, you can also use the local big data environment, it also works there. For rapid prototyping of workflows this might be the best approach anyway.