Hi;
How can I solve the problem in the workflow?
ThanksKNIME_path index 86 error.knwf (78.1 KB)
HttpRetriever / illegal character in path at index 86 ? solution of the problem
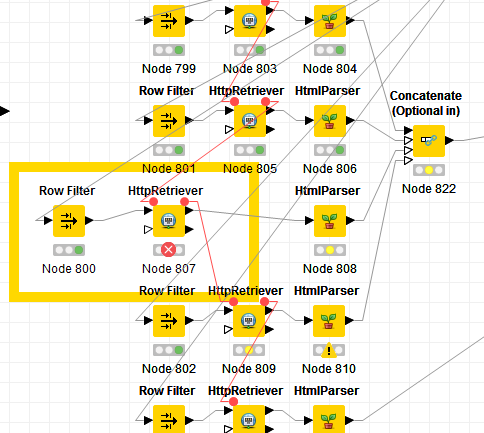
Hi;
How can I solve the problem in the workflow?
ThanksKNIME_path index 86 error.knwf (78.1 KB)
HttpRetriever / illegal character in path at index 86 ? solution of the problem
Hi,
To be honest and clear, the workflow you provided doesn’t make sense to me.
What are you trying to do? Maybe I can help you much better if I know this.
Best,
Armin
Hello Armin;
That’s what I’m trying to do.
The problem is that I receive an error while visiting the sub-page url links.
OK,
There are a few problems with your workflow that must be modified:
1- The get request node was unnecessary and I removed it.
2- The HTMLParser node was reading the initial URL not the result form HttpRetriever and I changed it.
3- When you get the href attribute by XPath node, there may be spaces in the URLs and you have to convert them to “%20” then you can use the URLs. So I added a string manipulation node after XPath node.
The rest of your workflow now works fine.
path error.knwf (75.7 KB)
Best,
Armin
That is a great job  now it might be possible to extract some more information. Tough from a first look @umutcankurt might still have some work to do.
now it might be possible to extract some more information. Tough from a first look @umutcankurt might still have some work to do.
Hi; Armin
Thanks a lot, thanks to people like you, it is very nice to learn and solve problems. Thank you for your hard work again. @armingrudd and @mlauber71
This topic was automatically closed 7 days after the last reply. New replies are no longer allowed.