please help me with native nodes
Hi there @chezhiyan ,
I don’t see a really easy way to do it. Here is how I got it:
https://kni.me/w/mJW2SjXOdP5nDuUT
Both approaches use loop. Now chose one you like more 
Br,
Ivan
thanks @ipazin… my table has 1m rows… after i started loop it never stopped running  i was expecting some kinda rule engine/native node/python script, that runs it faster… knime should think about this, a simple index match in excel taking so much time in knime is bad.
i was expecting some kinda rule engine/native node/python script, that runs it faster… knime should think about this, a simple index match in excel taking so much time in knime is bad.
Also is it possible to find the index of the column by min formula and then do a lookup from a column name extracter…? please help
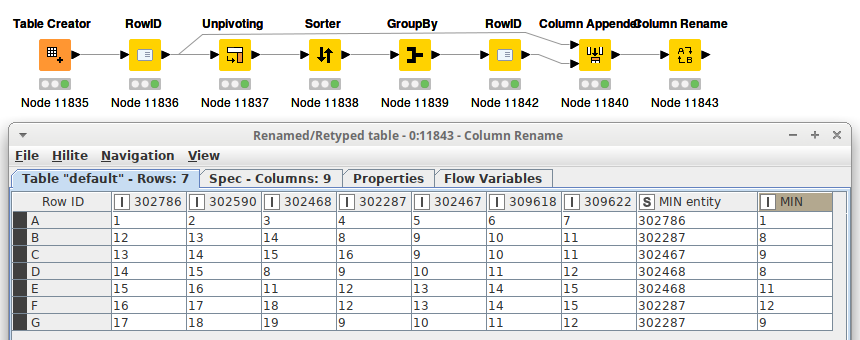
looks perfect can you share the workflow?
…but if your dataset consists of a million rows, it is probably better to do it in chunks.

Here is the workflow:
KNIME_project2.knwf (22.9 KB)
1 Like
Ooops sorry @chezhiyan it seems I forgot to configure the loop correctly. It also turns out you don’t even need the Column Appender if you configure the Unpivot and GroupBy nodes a bit differently. The best workflow is a perfectly horizontal branchfree workflow 

KNIME_project3.knwf (18.2 KB)
3 Likes
Hi @chezhiyan,
approach could be improved a bit but not enough for 1 million rows I afraid.
Br,
Ivan
something is wrong, results are not correct
You say it doesn’t work; do you mean it doesn’t work for the example table in your original post or for your million-row table? On my PC it seems to work fine for the example table. Maybe your million-row table has a combination of different column types that cannot be easily sorted? For example, a mix of string- and numeric columns? That can sometimes happen when importing excel data.
can we do it without sorting? i think that causes an error? is it possible to extract column header seperately? and find column index based on min value and then look up to the table? i think that will work better, but i dont know how to do
@chezhiyan there you go, a solution without sorting.

KNIME_project3.knwf (18.6 KB)
A column index method, as you suggest, may be possible somehow with the Column Expressions node…
Best
Aswin
1 Like
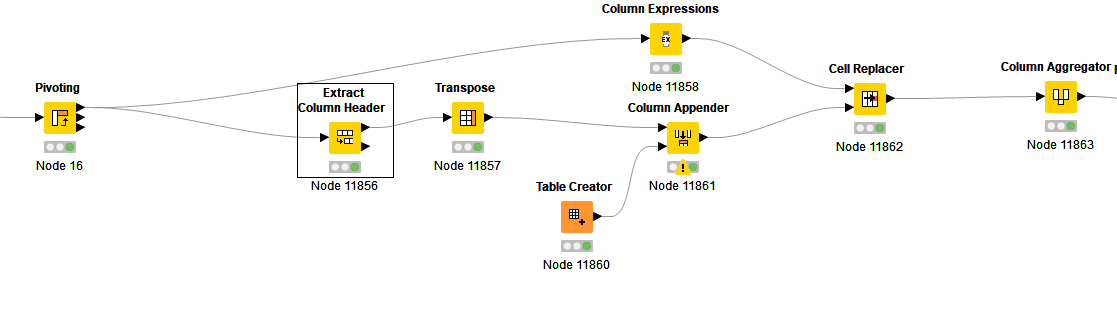
Hi all, haven’t compared for speed but here’s one more example to try. More the merry right?
In the event of 2 columns sharing the max value it grabs the left most column name.
Max column.knwf (8.2 KB)
4 Likes
Awesome @Corey, nice opportunity for me to learn about the Column Expression node, that one is still a bit mysterious to me. I was wondering: do we really need the Column Aggregator? Turns out we don’t 
Max column.knwf (6.7 KB)
Here is yet another method, one that avoids the scary Column Expressions node…
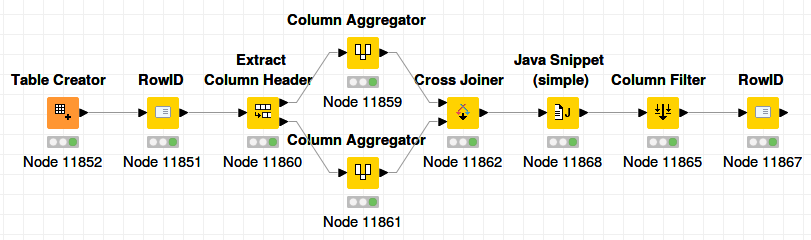
KNIME_project3.knwf (17.3 KB)
3 Likes
You’re correct! We can just use 2 expressions in the column expressions node if desired.
I had done it with the column aggregator to keep “scripting” to a minimum and because I wonder if it might be faster on large data sets.
I say test both if speed is a concern.
2 Likes
This topic was automatically closed 7 days after the last reply. New replies are no longer allowed.