Hi, does someone have an idea how to resample time series data to have regular step. I have daily data and when there is no measurement on certain periods of time, I have missing rows. I would like to have a row for each day in the span of 30 years. I have timeseries data for multiple gauging stations so the columns for the stations with missing data are shorter. I would like them to be all of the same length, but with empty cells where there is no data, instead of skipped cells.
Hi @Dalmatino16
Is it possible for you to post here a bit of your data (if not confidential) ? We will try to provide a workflow solution from there.
Best
Ael
Your request is to have a table with daily rows with missing in the days in which you have got no data.
You can generate a time series with the create date&time range appropriately configured then join by the date columns of both, the output column of the time range generator and your table, configuring the left unmatched option in the joiner (supposing that you put the generated column in the left input of the joiner).
At the end you will have a new table as you requested.
I hope to have been of help.
Giuseppe
Hi, my data is river water stages. Filling in the missing data is the next step, which I will probably also need a help ![]()
But, I try to do it one step at the time. First step is to fill only the dates, which are discrete. One row represents one day. So the first column would be days, one by one, without skipping. 30 years period.
It should look like this:
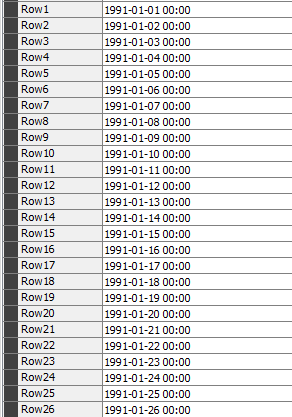
But sometimes I have missing datas which looks like this - take a look at the middle column
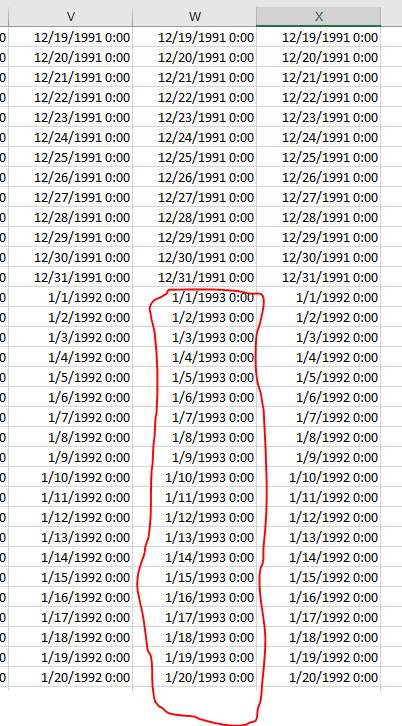
Originally I have gauged water stages with dates. One .csv file for each station.
Attached in my other post you can see example of two files. Station 3012 has all the dates and rows, and station 3155 has missing data so the colum is shorter because its missing the dates as well.
I have 100 files and stations like that. And the final results I need is something which looks like this:
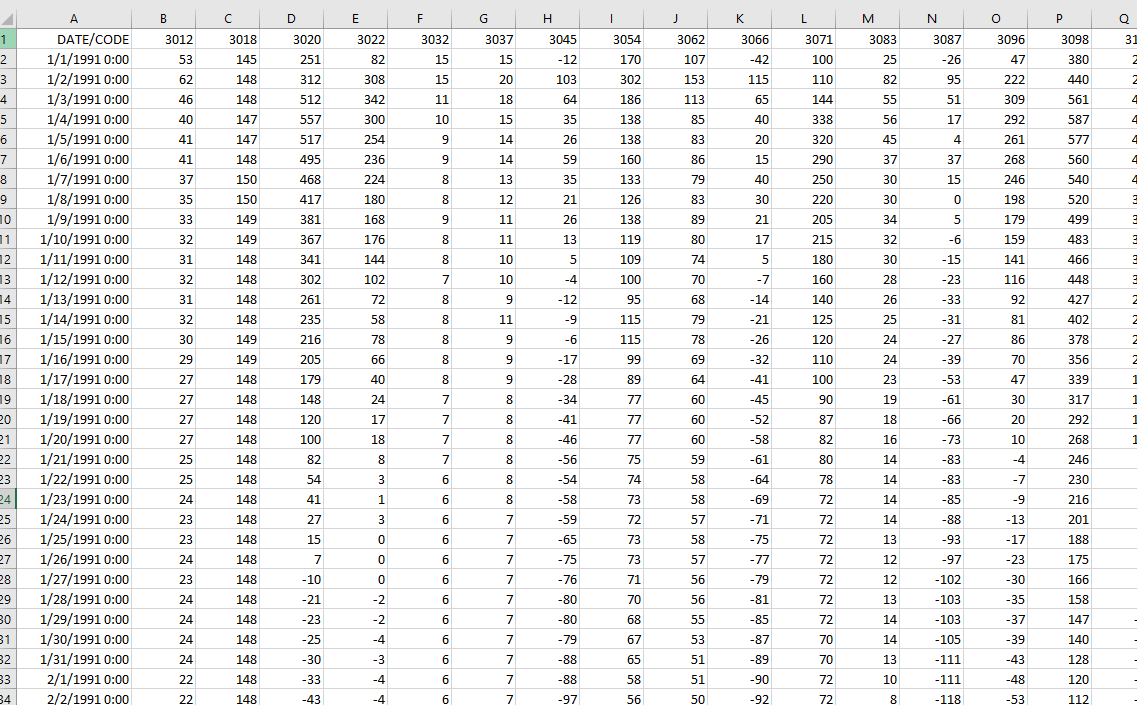
I already did this with knime by using this workflow:
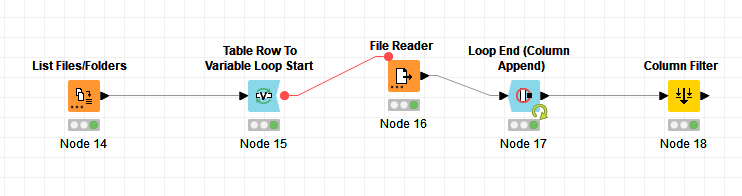
But I din`t get the results I need because not all stations have the same length of columns and therefore the dates in the first column are valid just with the records with the full columns. I hope I was clear what the problem is.
So, wherever there is skipped data, like in file 3155, I need the value cell to be left empty.
Filling in the missing data based on correlation would be the next step, but I need to resolve the first one first. So if you have any tips, I would appritiate it.
Hi Giuseppe. Do you think something like this? I am trying to do it with just one file, one station… Not sure how to proceed.
1 Like
Yes, you are on the right way, but before proceeding you need to convert the date column of the csv file to a Date&Time type column.
You can do it straight in the csv reader node or by using a String to Date node.
Obviously don’t forget to set in the Joiner Settings tab the joining columns of the two tables.
1 Like
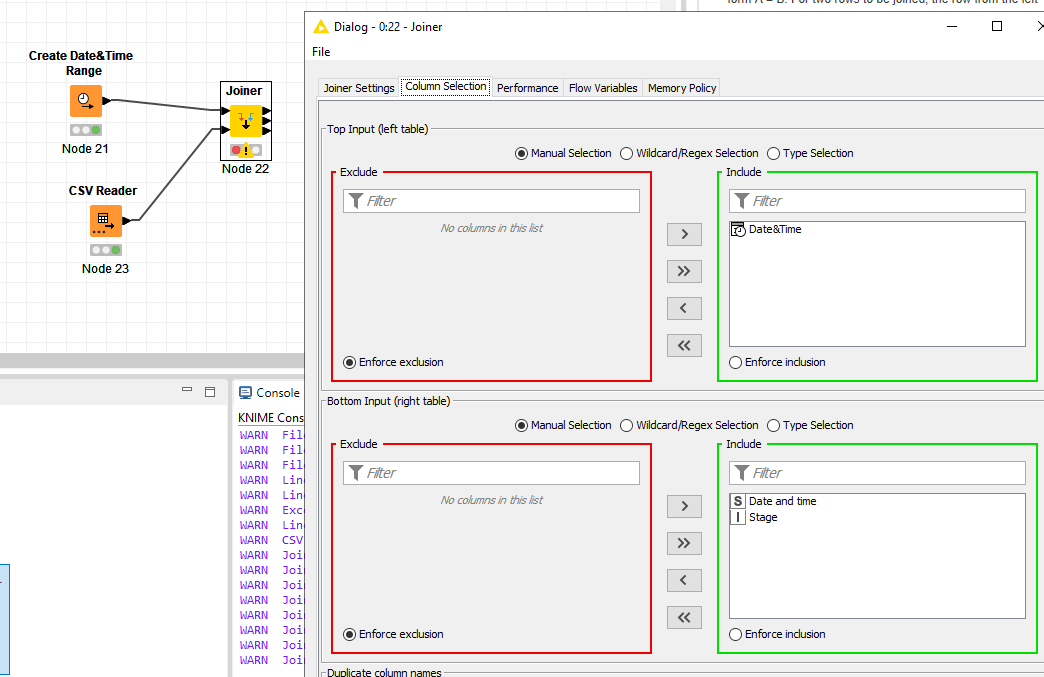
Still the joiner is skipping the rows.
Here is the workflow
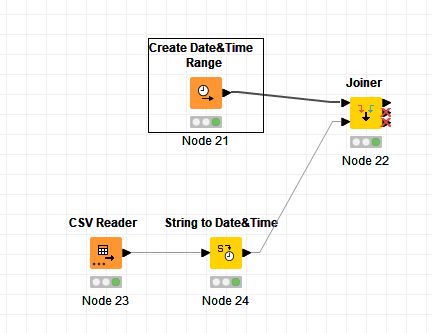
Here is the Node 21 output
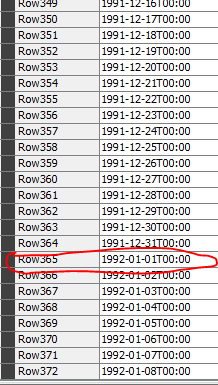
Here is the node 24 output with skipped year 1992
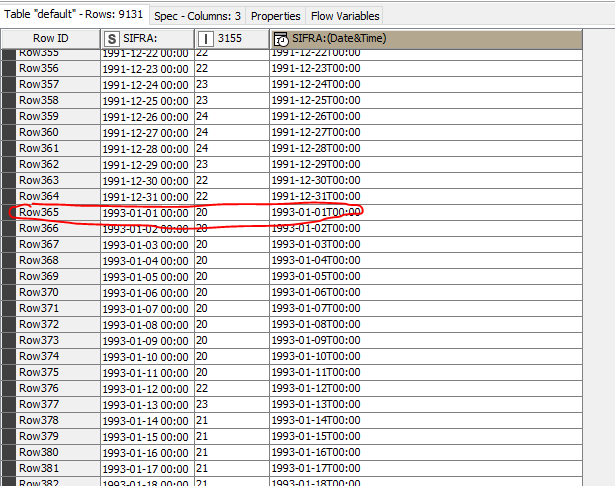
And here is the joiner results which skip the year 1992 as well.
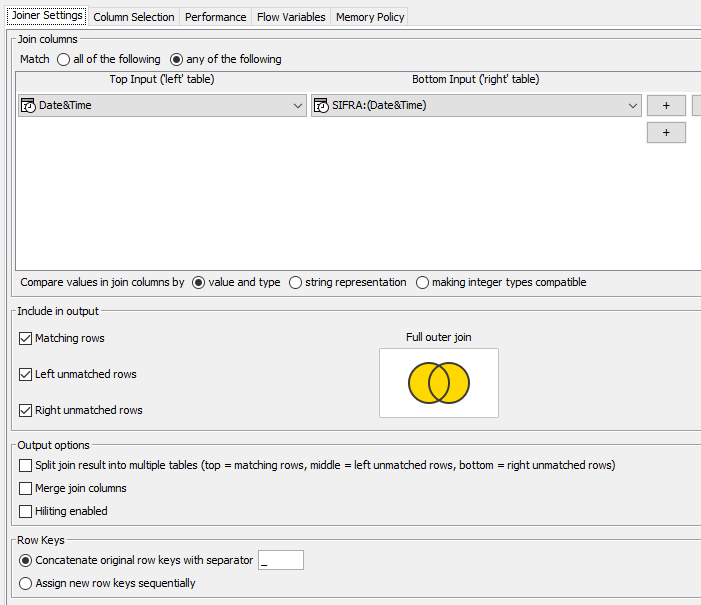
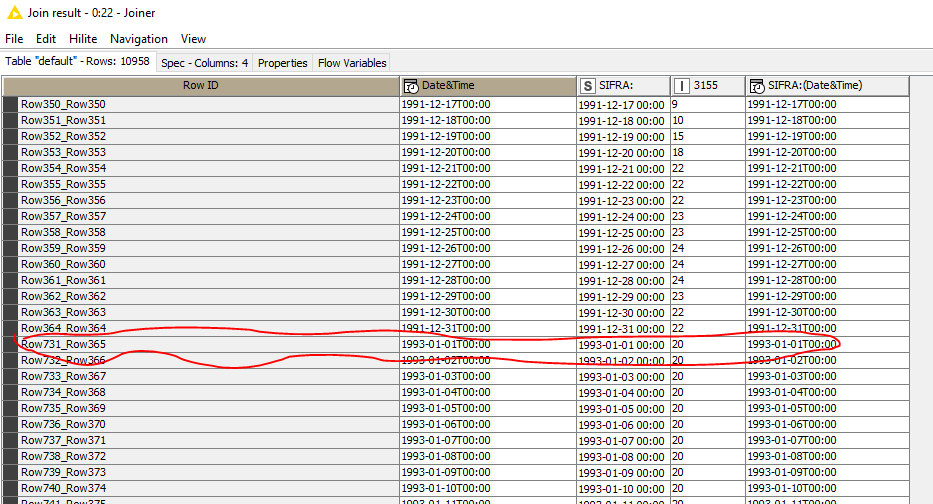
Any guess why?
I see now that unmatched ( year 1992 has been sorted at the end of the column
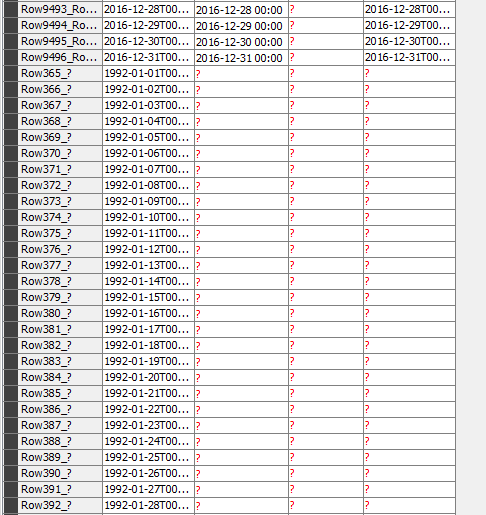
Is it possible to have it where it should be chronollogically?
From the image you posted I see the joiner is wrong configured, you need to set only matching and left unmatching rows (your configuration is for a full-join).
To get the column sorted you can use a sorter after the joiner (sort by date)
1 Like
Great, that worked. Thanks.
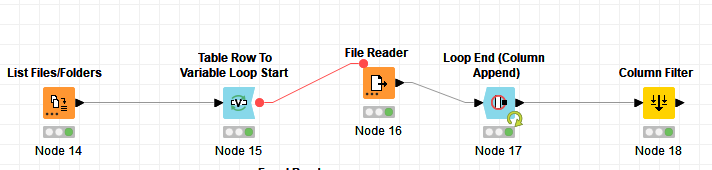
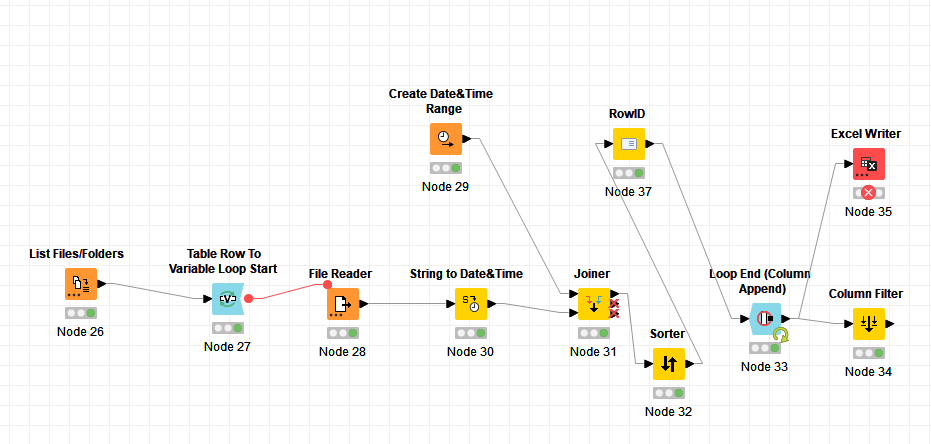
OK, here is the routine I combined
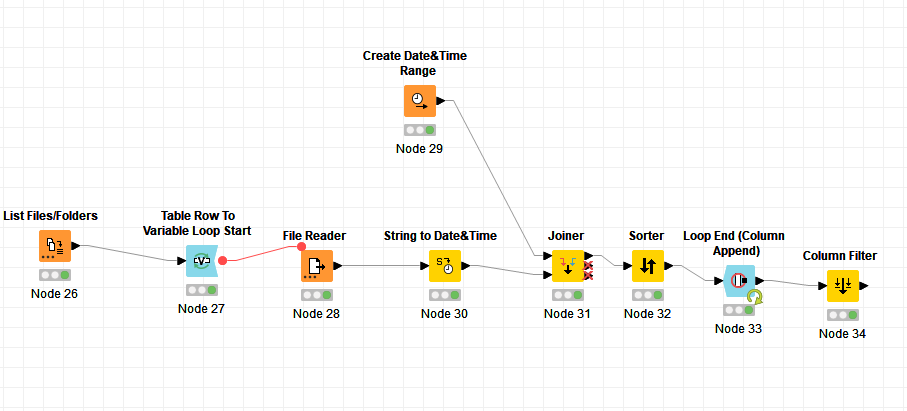
Works OK with one file
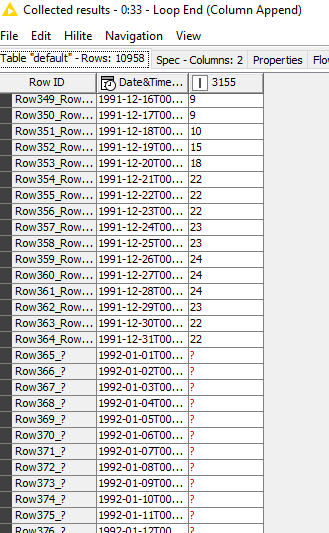
But when there are several files, here is what happens:
Data at 1992 is missing
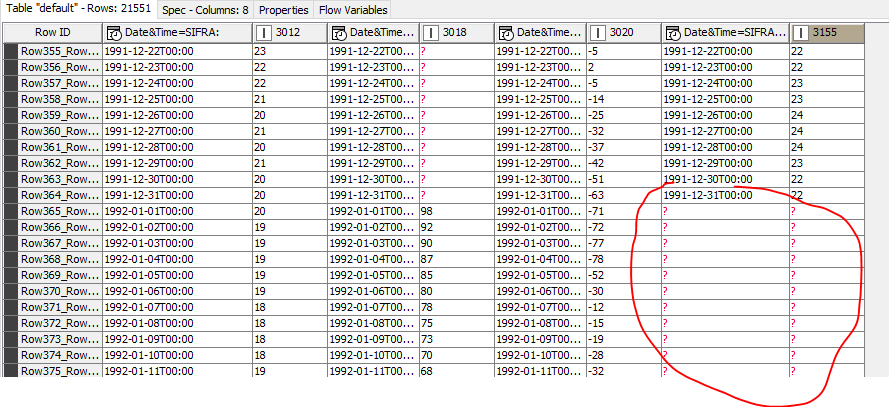
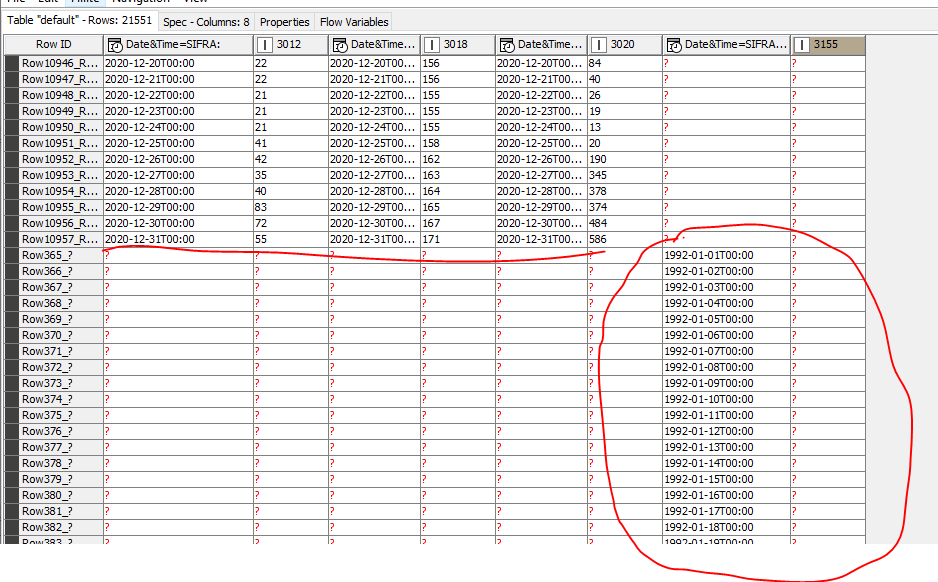
but, all the following years are missing as well and then at the end, after 2020., the remaining data is listed for the station with missing data
This topic was automatically closed 7 days after the last reply. New replies are no longer allowed.