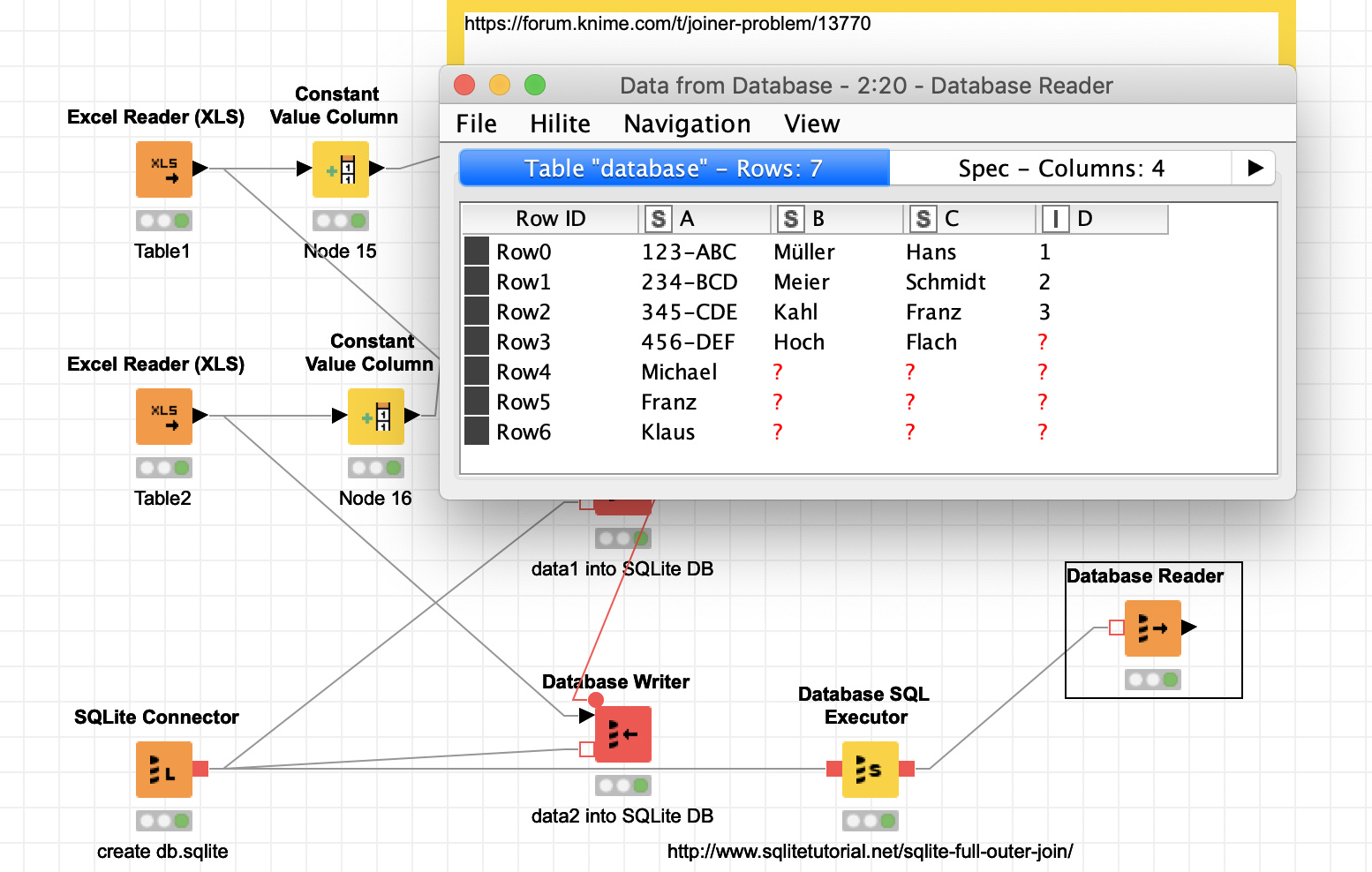
Compare Column A, when you find a match, write column B and C.
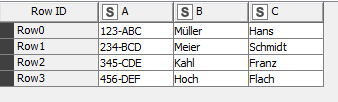
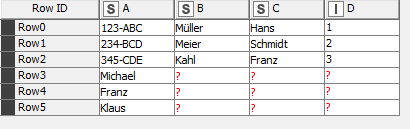
But i have no succes when i compare A, and table 1 has more rows like Table B or B has more than A. Example:
Check Column A with A, when you have a match write: A,B,C
My Problem:
KNIME dont write A when it dont have a Match, but in both Tables are More Rows as only the Matches Rows. I need a mix from join and concatenate.
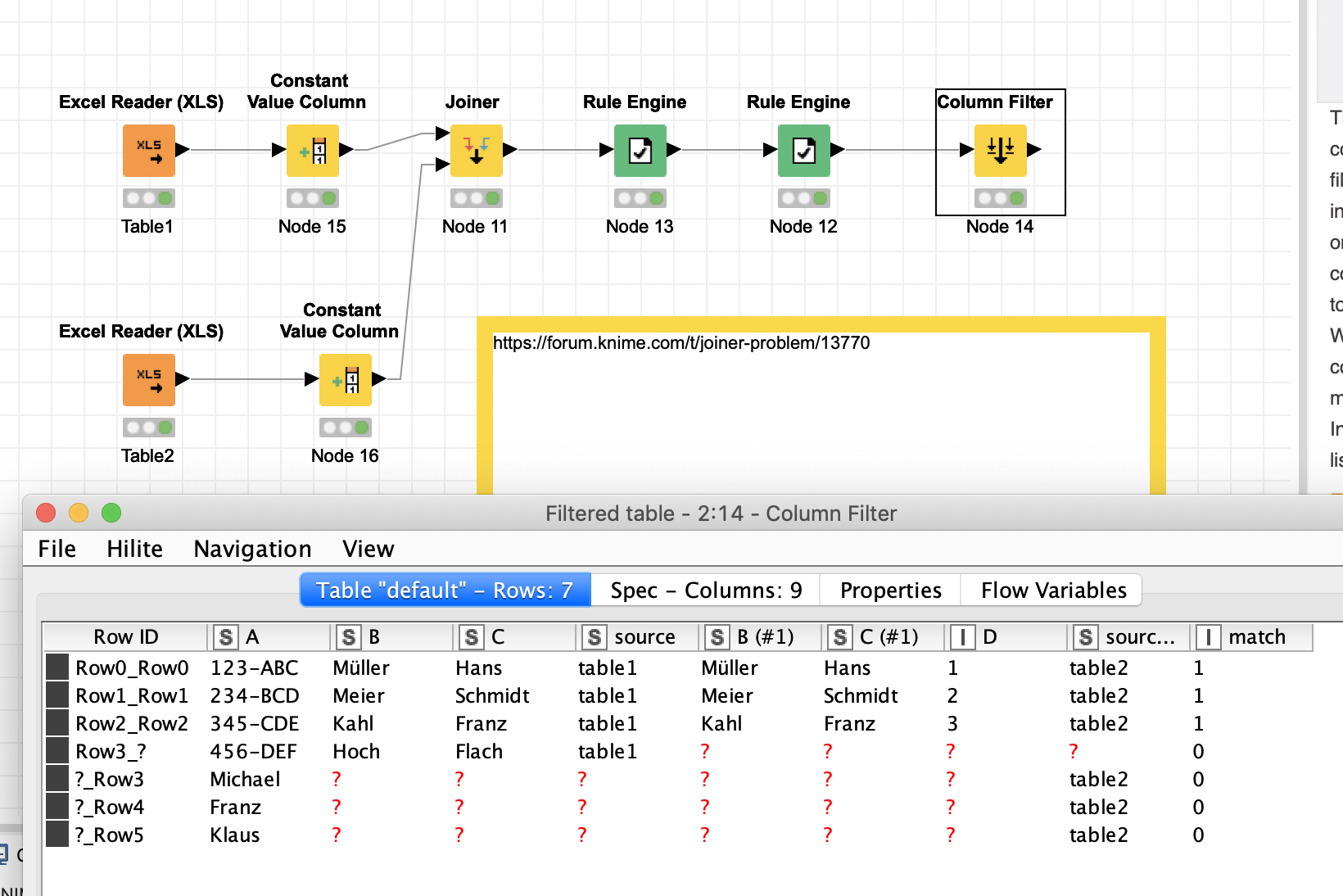
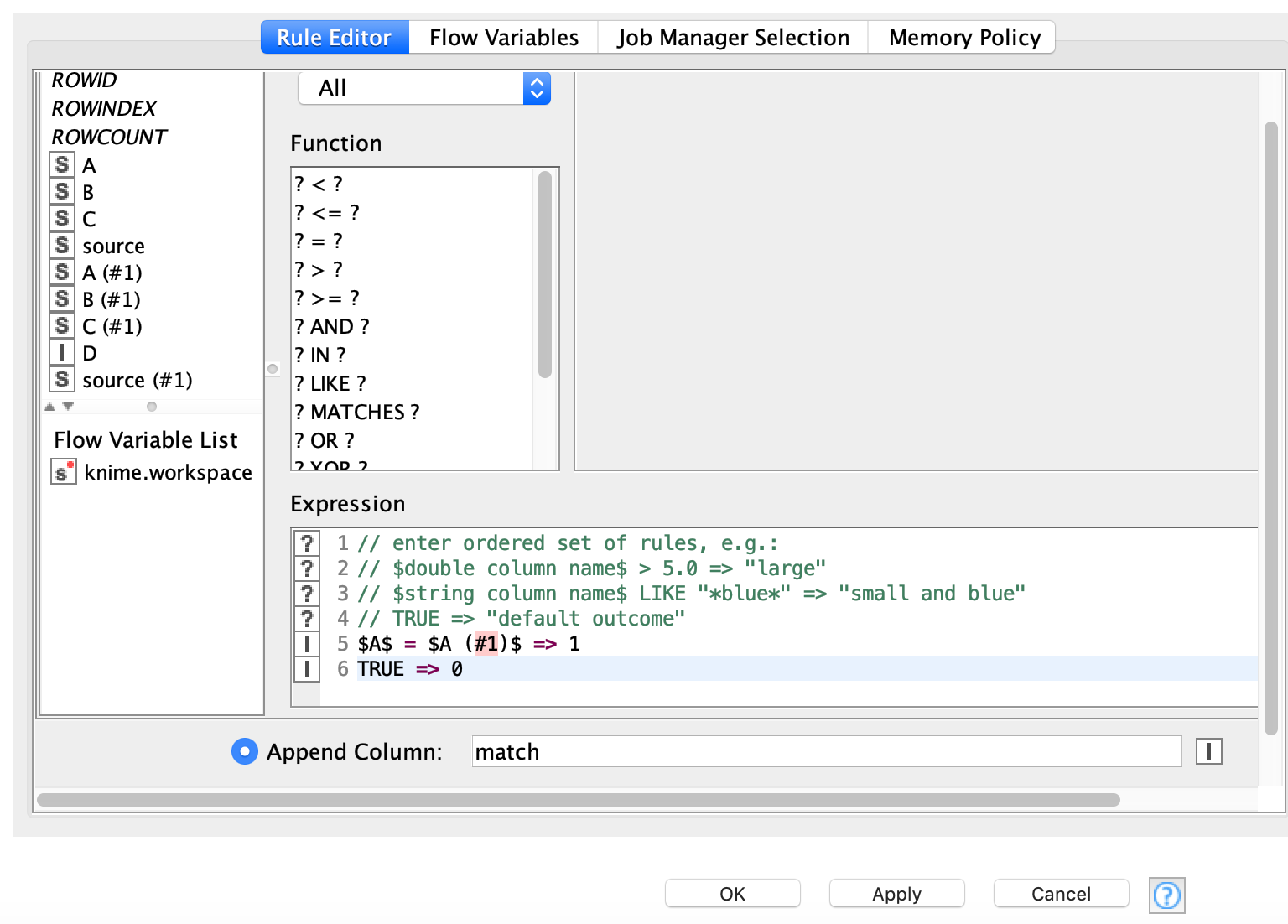
You could use the joiner node with full outer join and then Rule Engine to determine a common ID and if there was an initial match. I also carry information about the source of the data. You would then have to make a decision how to proceed with the data - eg which table gets the ‘lead’ or to check if the two columns B and B (#1) do match - for example you could give table1 the lead and only take data from table2 if it is missing.
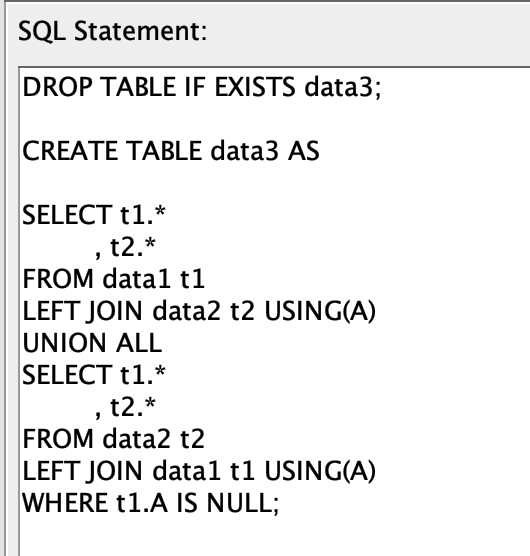
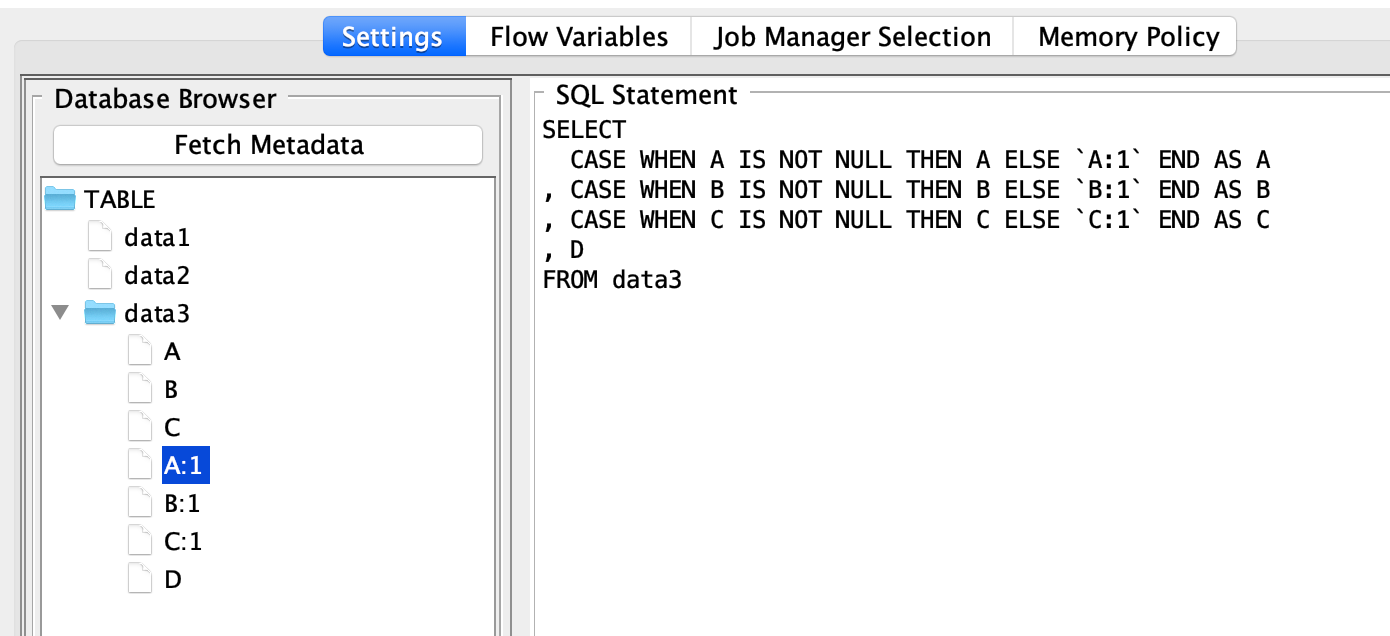
The Join functions of KNIME are somewhat limited and you would have to use a few rules and maybe more nodes to bring the data together. I thin in your case you cannot avoid setting a rule what to do with the columns that are the same in both tables but are not IDs for matching. You could even put all that in a single SQL statement but that is not really more readable.
From your last entry with the c–c--c columns I wonder if I fully understand what you are planning to do. Maybe if the example is not the right one you could construct a file that better suits your question (eg. if there could be more than one ID you might put that in your example). Typically it is much easier to solve problems with sample data - and constructing the example forces the person with the question (that is you) to think about where the specific problem is.
If you need to do this for an unknown set of variables you might have to use a loop.
With KNIME it is often the case you have to use quite some nodes to achieve your goal and often there is more than one way to do it, and especially in the beginning one might take a few extra or strange steps. In the end what matters it that you get your result and you can reproduce it - so if you have to explain it to other people use the node descriptions and annotations to structure your workflow.
So keep up with KNIME and Python - you will see great results and hopefully have a lot of fun on the way
Yes, next time when i am at home, i will show you the “real” datas to get a better answer.
I will keep you up to date and of course try myself to solve more and more difficult problems. It will be a long way to go, but I know it will be worth it. I wish you, izaychik63 and of course the whole community a great time!
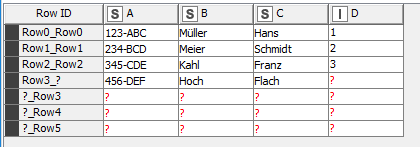
@chrimbo: Have you thought about a Joiner (Full Outer Join with unchecked option “Remove joining columns from bottom input”) followed by three Column Merger Nodes?
Hello Chrimbo,
normaly you have to set the joiner mode to left outer join. In this case all rows of table A are shown and only entries of table B which match the defined key(s). In your example Column A.
I had a lot of stress during the week, so unfortunately I am so late!
Attached as promised, the tables that represent my data source. Now, I would like, as already mentioned, a node that joins me both tables and match and complete same lines to the final table that exist in one but not in the other table and write the no-matches-found-rows and write this too in the final table.
I solved the problem with concatenate and Group by ( Soloution from izaychik63) BUT, mlauber71 woke me up in the positive to continue relentlessly going my way ^^ )
Tonight i will try the solution from agaunt and morpheus and give you a feedback if it works for my special problem ^^
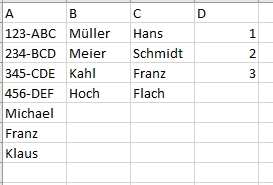
 ),
),