I hope someone can help me to understand this.
If I want to “translate” a Keras Model written in Python to a KNIME Keras Model do I just have to add the nodes like written in the Python Code?
Would this lead to an identical Keras Network? Or should I use the DL Python Nodes if I like to use ReLU and Softmax together? What is the main difference or advantage to use Keras Nodes or the Python Nodes?
The KNIME workflow you posted should in general be able to produce the same network as the one in the snippet (except for the model checkpointing, see below) – given that the nodes have properly been configured, of course. The layer nodes allow you to set their activation function, so choosing between ReLU and Softmax activation is possible – if that is what you were referring to by “using them together”.
Whether it is better to use the Keras nodes or DL Python scripting nodes, in your case, probably mostly depends on your personal preference (and potentially the one of others if you plan to collaborate on/share this workflow with other people) – for example if you have a strong (Python) scripting background or rather prefer visual tools.
In general, I personally would advocate using the Keras layer nodes as long as possible since these better match the way KNIME chops processes (workflows) into digestible, self-contained pieces (nodes). Having a lot of logic in a single node (in your case the entire Python script in a singe DL Python node) may make the workflow harder to understand and maintain for you and others, and may generally feel a little “un-KNIMEish”, especially when embedded into a larger overall workflow. That being said, you will always be more flexible when using code over pre-defined nodes. For example the model checkpointing you perform in the last line of your script currently cannot be done via KNIME’s non-scripting Keras nodes. In this particular case, I would probably assemble the model architecture using the Keras layer nodes and perform the training via the DL Python Network Learner node. If you do not need the checkpoint after all, the Keras Network Learner node should probably be the most convenient solution for model training.
thanks for your reply. It was to late for me to edit the posting, so this “using them together” is a bit confusing. Using them together: ReLU for the hidden layers and softmax for the Outputlayer.
But my main question was cleary answered that I can go thru a PythonScript and just add the Nodes in Knime - makes everything a bit more understandable for me.
Glad I could help! Feel free to reach out any time you feel you need some more clarification. There are also plenty of examples on the KNIME Hub that further illustrate our Keras/deep learning integration (including convolutional neural networks).
No, you would pick Softmax in the last Keras Dense Layer (so Node 75 in the screenshot). This layer is the output layer of the network. All nodes between and including Node 2 and Node 74 are the so-called hidden layers of the network. There you choose ReLU for each layer that actually has an activation function (should be all the Convolution 2D layers and Dense layers, just like in the script). The activation function is a property of the layer in Keras, not of the learning procedure or the entire network.
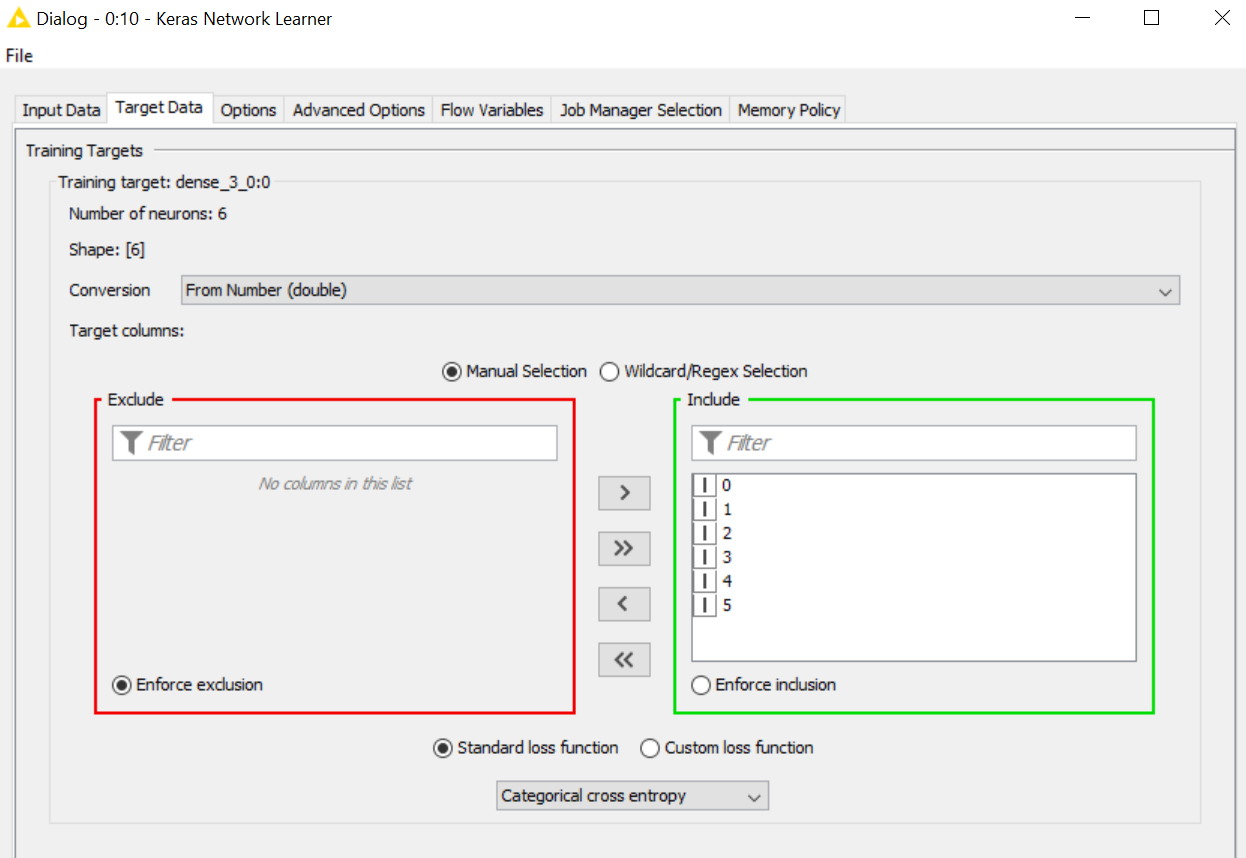
In the Keras Learner node, you would instead set the loss function (at the very bottom of the Target Data tab in the node’s configuration dialog). Given your network architecture, I presume you are trying to perform multi-class classification. So “Categorical cross entropy” (or perhaps “Sparse categorical cross entropy”) would be the right choice there.
Your learner/executor configurations look good, I believe.
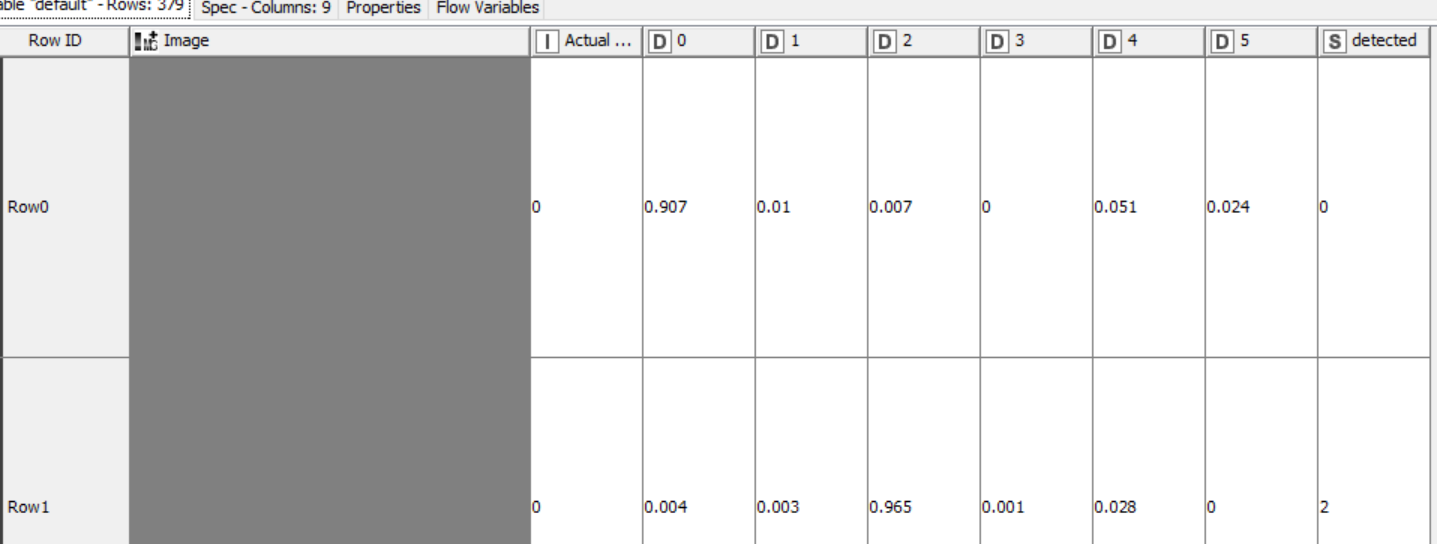
If you are using categorical cross entropy, your labels need to be one-hot encoded, that is, each input data row must consist of six integer values of which five values are “0” and one value is “1”. The position of the “1” encodes the category. So for example “cardboard” would be 1, 0, 0, 0, 0, 0 and “plastic” would be 0, 1, 0, 0, 0, 0. The softmax activation function in your last layer outputs a probability distribution over the classes, that is, all output values will be somewhere between zero and one and sum up to one. The encoding of the labels must follow this representation, which is what the one-hot encoding does.