I’ve tried the parameterized query reader now.
It seems to continually run without result. and also seems to need a black connector where as the SQL server connector puts out a red connector.
Not a clean alternative to the legacy looping node.
I had trouble with legacy Parameterized Query node and use Database Looping one as a better option. Why KNIME decided to eliminate it?
Hello,
we haven’t re-implemented the existing Database Looping node for the new db framework because the looping node had some flaws which were already eliminated by the Parameterized Database Query node in the old database framework. Among the problems is the duplicate value handling, optional database connection in-port, the hard coded quoting of the value list, and the performance problems since the looping node does not use prepared statements. That is the main reason why we haven’t migrated the Database Looping node but the Parameterized Database Query node which is the Parameterized DB Query Reader node in the new db framework. We think that the parameterized nodes provide more functionality, better control over the generated SQL query and improved performance then the looping node. But we might be wrong which is why your feedback is important to us. So if you have a case that can not be solved with the Parameterized DB Query Reader node let us know and we need to rethink our decision.
For the migrating from the Database Looping node to the Parameterized DB Query Reader node I suggest to first assemble the query that would return all of your data e.g. join the tables you need and use this as input for the Parameterized DB Query Reader in which you then simply filter based on the values of the input column(s).
If you still want to use something similar to the old Database Looping node you could use a loop construct with a DB Reader in KNIME. Admitted, depending on the options you use from the node this loop might be a bit more complicated  That is why I have created a component that emulates the old Database Looping node for the new database framework but which hides all the complexity. You can copy&paste the node from the workflow that I have uploaded to the KNIME Hub at https://kni.me/w/7tCeIJ6M6ZX0o3xO
That is why I have created a component that emulates the old Database Looping node for the new database framework but which hides all the complexity. You can copy&paste the node from the workflow that I have uploaded to the KNIME Hub at https://kni.me/w/7tCeIJ6M6ZX0o3xO
@izaychik63: It would be great if you could tell us which problems you had with the Parameterized Database Query node.
Thanks for using the new database framework and your valuable feedback. Your feedback helps us to improve KNIME Analytics Platform and the new database framework.
Bye
Tobias
2 Likes
Thank you, Tobias, for detailed explanation. First of all I have trouble to switch to new framework because it is not possible to use old and new nodes in parallel. In my situation I cannot have 2 parallel installations of KNIME because of strict company policy.
As for Parameterized Database Query node, it works only with flow variable as query parameters but not with fields from input table. Believe in new framework it works.
In general new framework takes much space. In version 4 two compact nodes gone Database Reader and Database Looping. Many people do not need details and flexibility but functionality and compactness.
Just checked, Database Looping returns same number of rows as MS-SQL SMS and Parameterized Database Query returns less records (query has distinct clause).
Please, bring Database Looping back to the new release.
1 Like
In general the old and new framework can we used in parallel except when you use native authentication to connect to a Microsoft SQL Server as discussed in this thread. We weren’t aware of this problem and are working on a solution for it. We know that our users use the database node extensively and with many different settings. That is why the old framework is still available and only flagged as legacy. So as long as we haven’t solved the above mentioned problem you can use the old framework as before.
The Prameterized Database Query node works with the column values of an input table. To do so simply double click in the node dialog on the column name and a place holder will be inserted into the SQL query at the current cursor position. When the node is executed this placeholder is replaced by the value from the column. This way you can also use several input columns in your SQL query.
The Database Reader node has been replaced by the DB Query Reader node. For details about the mapping from old database nodes to new db nodes have a look at the node name mapping table in the database documentation.
Can you please provide more information or ideally an example workflow that demonstrates the problem where the Parameterized DB Query Reader node returns less records then the Database Looping node. This would help me a lot.
Thanks
Tobias
1 Like
Tobias, I need to state again that Prameterized Database Query is not accepting parameters from Column List with error massage The index 1 is out of range.
It is not possible for me to provide data set as far it is confidential. And my reason to avoid this node initially was based on the incorrect result comparatively to Database Looping.
Also, performance of Database Looping is better then combination of the Chunk loop and Prameterized Database Query.
Sorry for being so persistent but I try to understand the problem so that we can fix it. If you can not provide the data can you at lease tell me the query you are using e.g. where you are using the distinct clause. You can also change the column and table names if needed or send it to me via personal mail.
I tried to reproduce the problem with the Parameterized Reader nodes but couldn’t so far. I have uploaded the workflow that I used to try it out. It would help me a lot to find the problem if you could could either manipulate my example workflow in a way so that it fails or if you could send me the KNIME log with the full error message. To view the KNIME log go to View->Open KNIME log then you can go to File->Save as to save it on your local disk.
Thanks
Tobias
Here’s SQL and the screen. When I use Flow Variable NPI as parameter it works (but incorrectly in some cases (some NPI returns less records then expected), when I use NPI from column list - index 1 is out of range error goes to log).
select distinct dt.DateValue as Service_Date, enc.EncounterEpicCsn
,pos.Name as POS, pd.ProviderEpicID, pd.NPI, pd.Name as Billing_Prov, pd.ClinicianTitle, pd.PrimarySpecialty
, pp.ProviderEpicID as Serv_ProvID, pp.Name as Serv_Prov, pp.ClinicianTitle as Ser_ClinicianTitle, pp.PrimarySpecialty as Ser_PrimarySpecialty
,c.PrimaryMrn, c.Name as Patient
, a.BillingProcedureQuantity
–, coalesce(d.CPTCode, d.HcpcsCode) as CPT_Code
, a.BillingProcedureCode as CPT_Code, a.BillingProcedureDescription as CPT_Desc
, dx.Value as Dx, dx.DisplayString as Dx_Desc
, cvg.BenefitPlanName, cvg.PayorName
from fullaccess.BillingTransactionFact a with(nolock)
join fullaccess.PatientDim_current c with(nolock)
on c.patientKey = a.patientKey
join DiagnosisTerminologyDim dx with(nolock)
on dx.DiagnosisKey = a.PrimaryDiagnosisKey and dx.Type = ‘ICD-10-CM’
join ProviderDim pd with(nolock)
on pd.ProviderKey = a.BillingProviderKey and pd.IsCurrent = 1
join ProviderDim pp with(nolock)
on pp.ProviderKey = a.ServiceProviderKey and pp.IsCurrent = 1
join PlaceOfServiceDim POS with(nolock)
on pos.PlaceOfServiceKey = a.PlaceOfServiceKey
join CoverageDim cvg with(nolock)
on cvg.CoverageKey = a.OriginalCoverageKey
join EncounterFact enc with(nolock)
on enc.EncounterKey = a.EncounterKey
join DateDim dt with(nolock)
on dt.DateKey = a.ServiceDateKey
where a.TransactionSubtype =‘Post’ and a.TransactionDetailType = ‘New Charge’
and dt.DateValue > dateadd(mm, -2, getdate())
and (pd.NPI =’$${SNPI}$$’ or pp.NPI = ‘$${SNPI}$$’)
Hello izaychik63,
thanks a lot for the information. I was now able to reproduce the the index 1 is out of range problem. I haven’t thought about using the same column twice. I have created a ticket for it to fix it as soon as possible.
We will also gather further feedback to see if we can re-implement the Database Looping node. But I can see that the Prameterized nodes would return more rows then the Looping node if you have a distinct clause for all result columns. However I guess this would also only work reliably if you create an in statement that contains all possible input values and thus execute only a single query.
Bye
Tobias
Thank you, Tobias. I agree that if Parameterized node will have an option to create a temp table for input values to generate code like Select * from table where value in (select in_parameter from temp_table). Of cause implementing Database Looping in v. 4. will help to switch to the new version.
Hi izaychik63,
we have just released KNIME 4.0.1 which also contains the fix for the Parameterized Reader bug (AP-12329). For further details see the changelog. To update simply open KNIME and go to File->Update KNIME…
Bye
Tobias
2 Likes
Thank you, Tobias, for a good news. Is the issue with parallel use of new and legacy DB node functioning is resolved too?
Hello izaychik63,
do you mean connecting to a SQL Server via native authentication with the legacy and the new MS SQL Server Connector in parallel? If yes this is not fixed but we are working on it for the winter release.
Bye
Tobias
1 Like
Hello izaychik63,
with KNIME 4.1 you can now use native authentication in parallel with the new and the legacy database framework. In the new database framework native authentication is supported out of the box. So you do not need to install or add any additional files. For further details see the updated database documentation or the node description of the Microsoft SQL Server Connector node.
Bye
Tobias
Could you please add some specific? I’ll start with old database framework.
First I register MS-SQL JDBC in KNIME. Should I copy sqljdbc_auth.dll to specific folder or it supposed to work immediately?
I cannot experiment with parallel KNIME installation. My company policy does not allow to run any executive not installed by admin.
Thank you
Hello izaychik63,
sure no problem. For the old framework nothing has changed. So here is what you need to do to connect to MS SQL Server with native authentication for the old framework using the official Microsoft driver:
- Install the available “” plugin in KNIME via File->Install
- Close KNIME and open the knime.ini file which is located in the KNIME installation directory with a text editor such as notepad
- Download the latest Microsoft SQL Server JDBC driver from here.
- Extract the files and copy the path to the sqljdbc_auth.dll which is usually located in the following directory: sqljdbc_7.4\enu\auth\x64 for 64 bit Windows and sqljdbc_7.4\enu\auth\x86 for 32 bit Windows.
- Append the following line to the end of the file: -Djava.library.path=<path to the DLL>
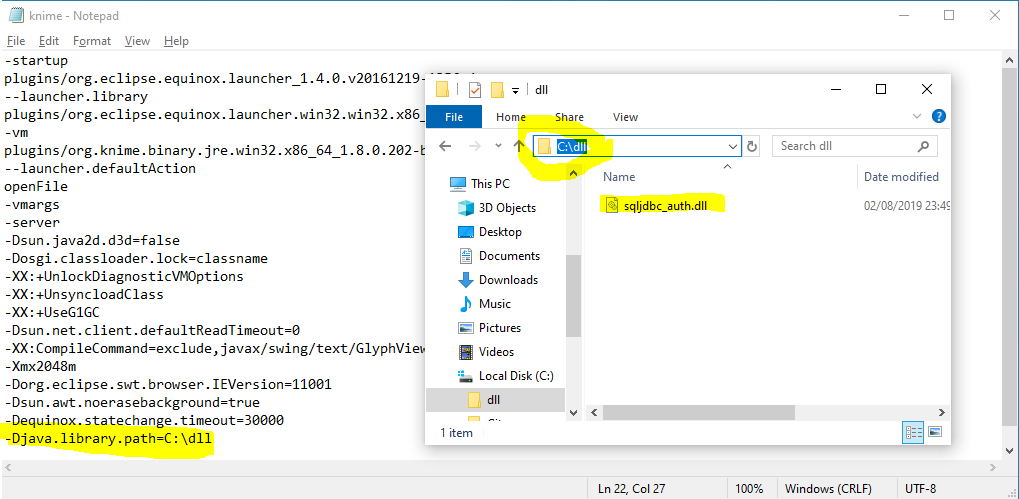
With the new framework this is now much simple since we now ship all required DLLs with the driver. So to connect to your database using the new framework please follow the instructions in the database documentation.
Unfortunately the new DB Looping node hasn’t made it into the release.
Bye
Tobias
2 Likes
Thank you, Tobias.for details.
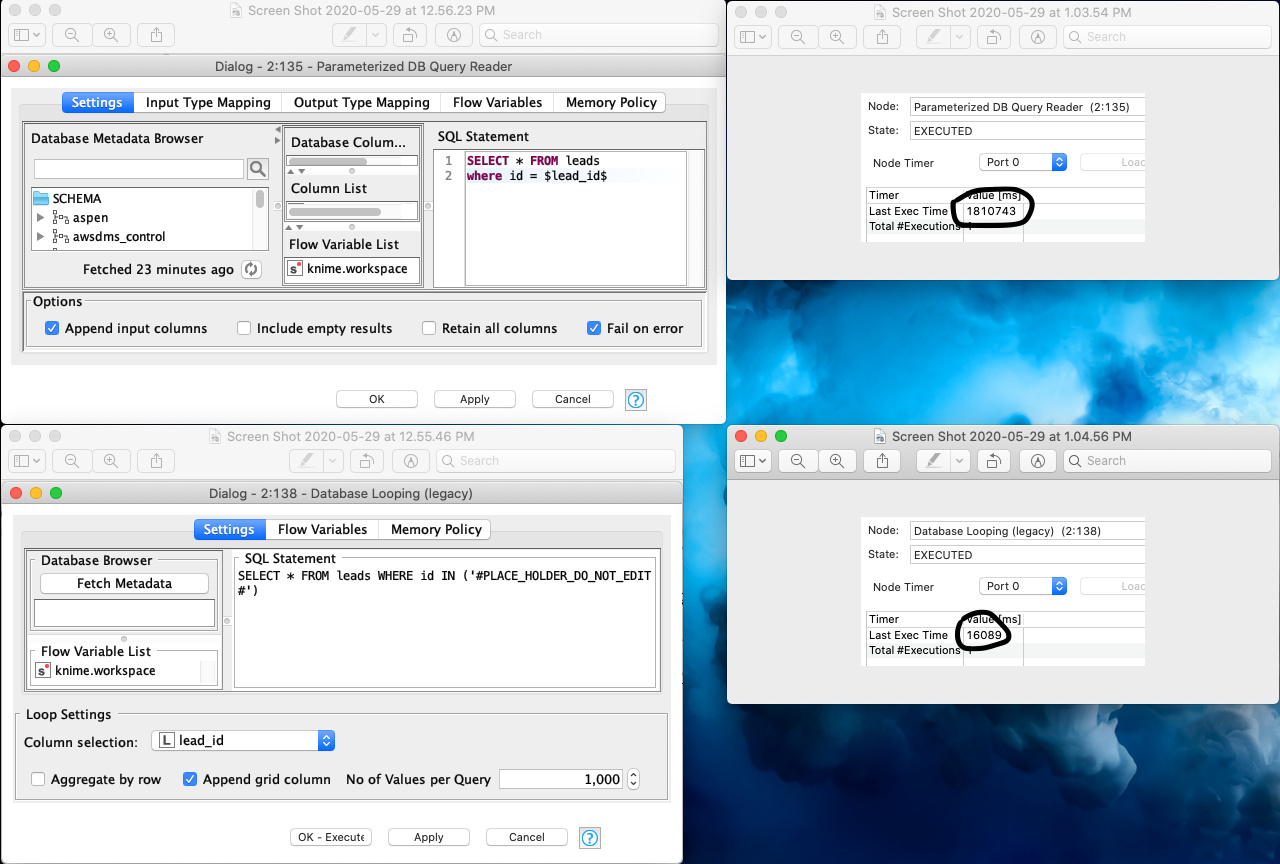
Hi. Interestingly enough, it is true that the parameterized query returned more records, when all I really wanted was the set from the “in.” Easily enough solved by a group by.
My real problem with the parameterized database query is simply the time. It takes 112 times longer for 30,000 records. There has to be a far more efficient way, doesn’t there? The parameterized database query is unusable.
1 Like
Could you please try the simulation component from here
1 Like
This topic was automatically closed 182 days after the last reply. New replies are no longer allowed.