@Thiemo.Kellner my suggestion would be to toy around with this workflow to see various functions and how they would work:
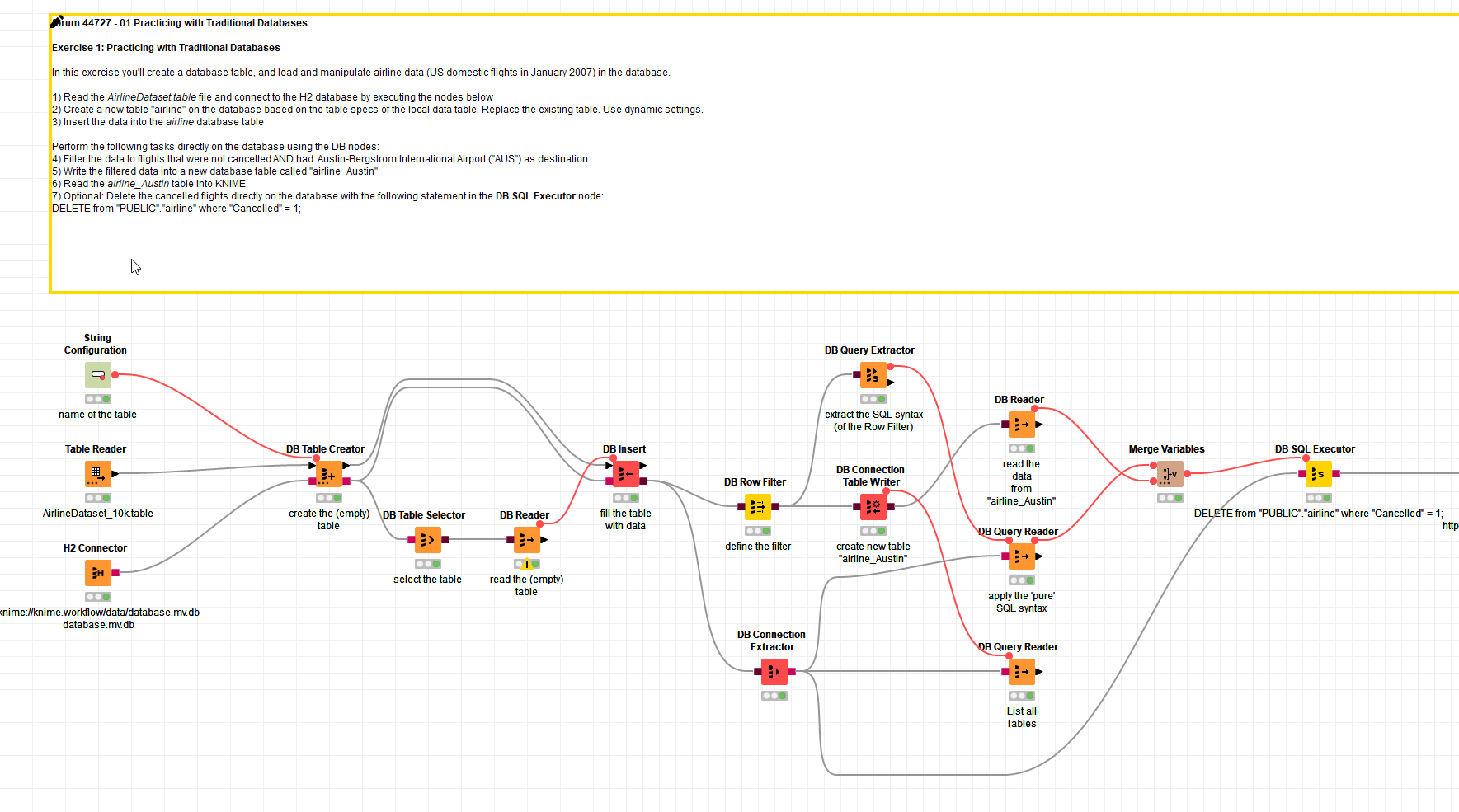
The ‘brown’ database connections are indeed a combination of SQL VIEWS that are put together without optimization (that would be the job of the database). I would assume this is because they are meant to function across a large number of databases and the combinations could be quite extensive (think: Hive, Impala, Big Data). So like with every database the user will also have to keep in mind what a database might be able to do.
What the nodes do is to try and adapt to several different SQL ‘dialects’ that also might include the usage of escaping special charachters like quotation marks. Using double marks as escapes is one way to do it otherf might be backslashes . This very much might depend on the database.
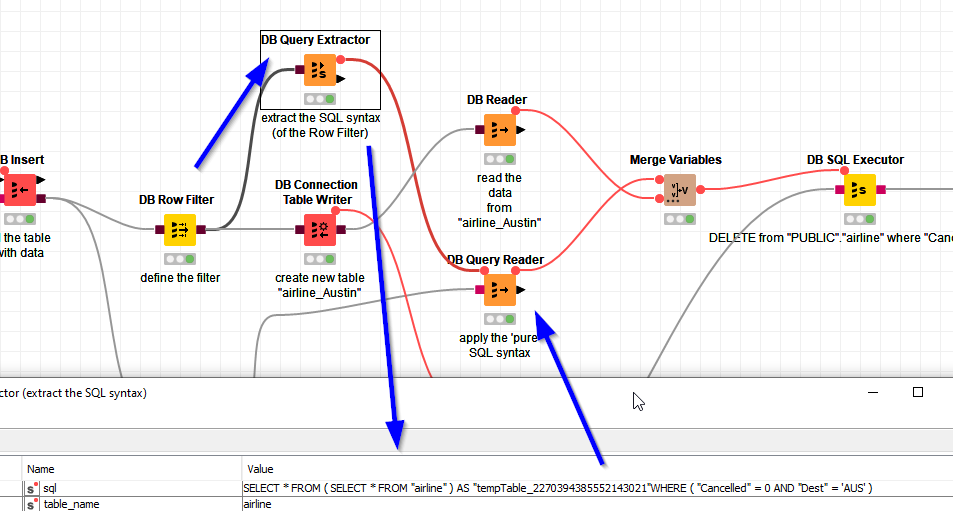
Like shown in the example it is possible to extract the SQL syntax one has created in the workflow from the brown connections and use it in another node.
Then a more general remark: over the last days you let us participate in your learning journey with KNIME. Thank you for that and for the suggestions you made.
If I may add a hint from my side: A lot of (open source) software will need settings and adaptions and has special syntaxes. Often it can be useful to toy around with settings and familiarize oneself with the syntax before assuming something is a bug or simply wrong ![]()
About KNIME and databases you might want to take a look at this Database Extension Guide