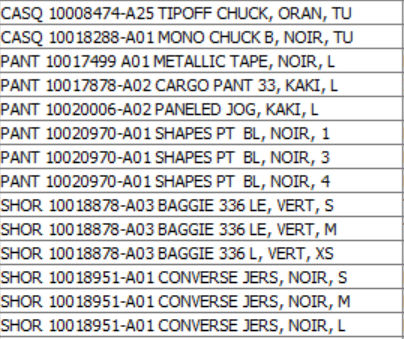
Here I have different articles from my brand. I want to split the cell so I can have only the size (which is the last letters from the string).
The thing, if i do a cell splitter for every space, it gives me 4 or 5 or 6 columns. Depending on the number of spaces of course.
Do you know how I can, for every rows, keep the size apart from the reste of the string?
Id like it to be automated for every row.
Have you tried splitting using a comma as the delimiter?
An alternative to this is using RegEx Extractor to grab the portion of the string after the final comma. The RegEx would be something like ([0-9]|[A-Z]+)$
elsamuels proposal hopefully solves you issue
beside this if you do not like regex (Who doesn’t like regex but anyway) you could also try out string manipulation
substr(reverse($YOURCOLUMN$), 0,1 )
is there a node where i can make a group by whenever there are no missing values
for example : as the split is for the coma
2 columns for 42,5 42 and 5
then the group by would asemble the two
but is that possible if there a no value (for example the 42 doesn’t need any group by)
This is what happens when you don’t provide enough information with your initial post. Your example shows sizes which are just a single letter (or number), or 2 letters, and so my suggestion reflected that. Are there any other peculiarities with your data that we should know about?
My vote would still be for a regex method, but with the updated regex (\d*\,?\d+|[A-Z]+)$