We are to create a programm which aims to classify patients and finds out if they have minor/major/severe depressions according to the PHQ8-Scoring-System. We have 3 data sets. Test data, train and dev data. Train and dev data are for machine learning, test for manual testing. We also have 189 individual text csv files with questions and answers from interviews. In the train and dev data set there are already classified PHQ 8 score data, but no corresponding texts. We know by the ID which interviews belong to which classified PHQ 8 score, but the IDs are not written in the interviews but in the file names.
Is there a way to link one line of the test data set to a text data set?
Result: From the data the complete PHQ8-Score is to be created and then the classification in ill/healthy is to be made.
so just to conform my understanding.
-You have X-Files containing your question/answers.
-All files have the interview id in the file name
-You have another table with your scores which contain the same interview id
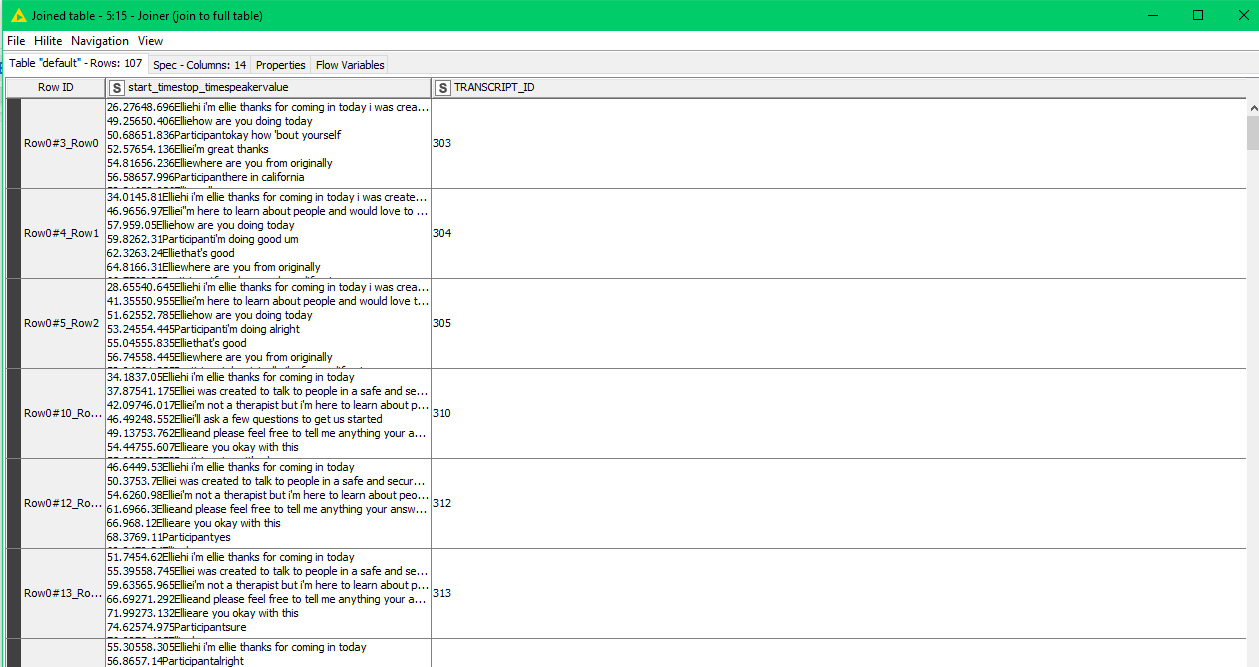
Output should be one table with your scores, as well as the corresponding texts from the files with the same Interview id?
Use the list files node to get the reference to all files:
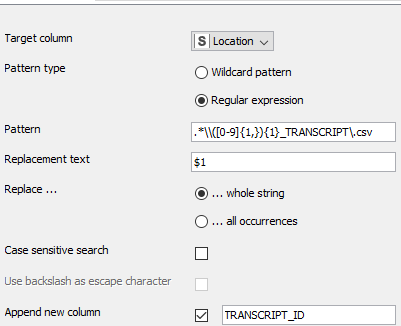
-Use the string manipulation node to extract your id from your file name - depending on the file name structure a simple substring or maybe a regex
-Output the extracted id as new column beside the file names
-Loop though all csv files with the table row to variable loop and a csv reader
After you read in the csv, output the interview id as new column e. g. through
-Use a normal loop End
If i understand your problem and data correctly - you should now have the base table for for answer/questions including the id
Finally use the joiner node to combine your two data sets
*else you can give 3 example files (just the structure with faked data)
As well as a fake table you want to combine it with
Then it would be easier to suggest a solution
For my evaluation I need the speaker and the texts separated, so that they can each be routed to an input of the Concatenate node (see example WF)example.knwf (28.0 KB) .
With this I try to find out by means of “Bag of Words”, applied to the texts, which of the participants (IDs) have depression and which do not (0,1).
My problem now is that I can’t separate the column start_time/stop_time/speaker/value and need help with this. I want to delete the columns start_time and stop_time. Here is Data for testing purposes exampledata.zip (1.1 KB)
If you need more details, I will be happy to provide them.
i think you are looking for the Cell Splitter Node:
From your example file it seems like you can split by space.
Then you get a new column for each value in the start/stop/speaker column
Afterwards just use the Column Rename Node to make it more readable
In case you do not have a splitting character, you could also split by position:
Or by regex:
*Could you please resolve this topic afterwards, so it is shown as closed?
(also would appreciate likes if my reponses helped you… so I can at least see some badges for the hours wasted )


 )
)