On the Advanced tab of the CSV Reader node, enable support for changing file schemas.
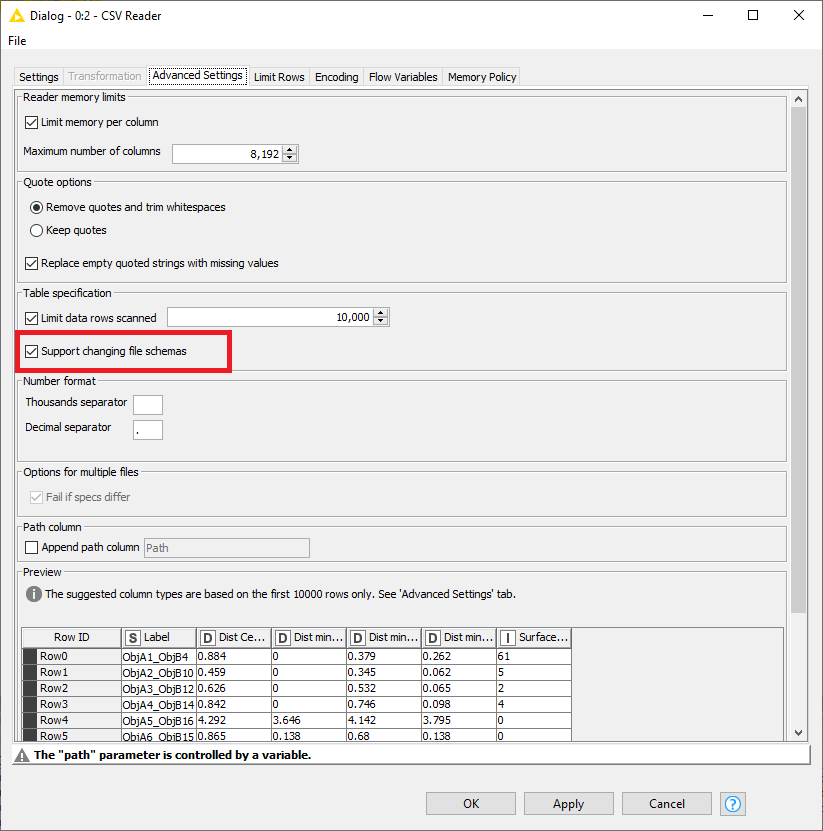
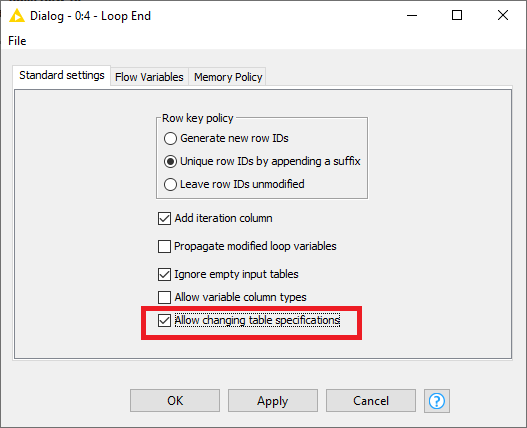
You’ll also need to allow changing file specifications in the Loop end node.
Alternately, you could do away with the loop and only use the CSV reader node to read all of the files directly and concatenate them:
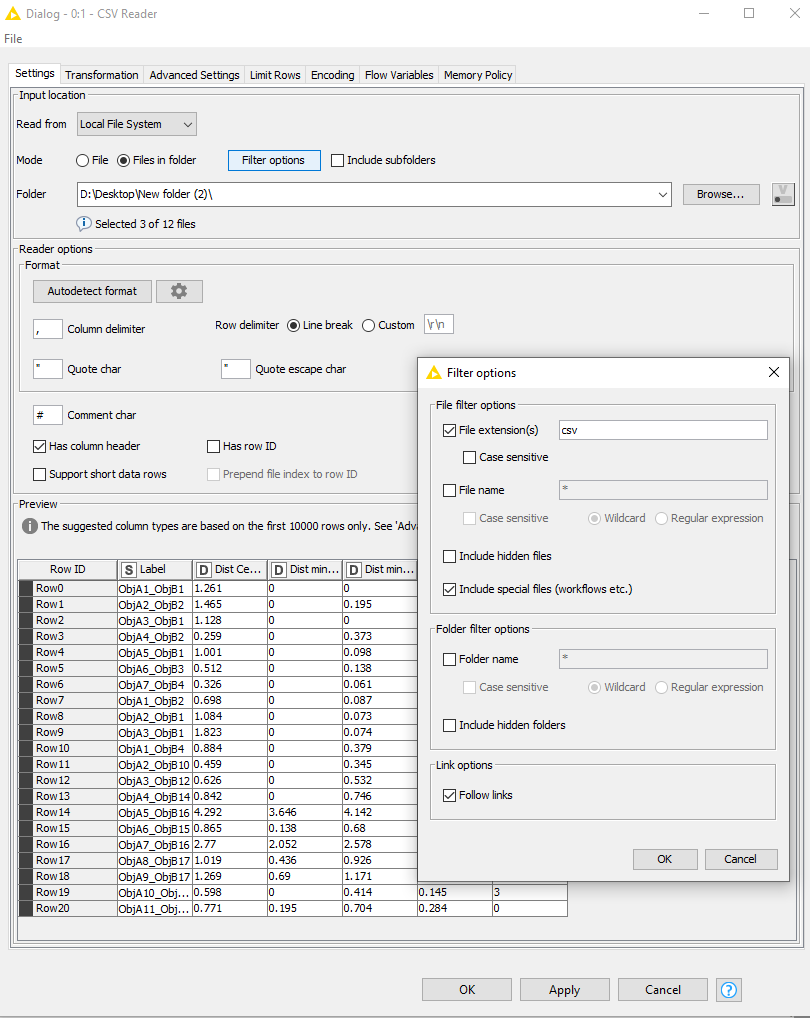
When I do this, everything works without having to change any file schema settings.