Not sure. SMOTE doesn’t scale well at all with number of features. It likley takes a very large fractions of the total runtime. besides the facts I would never use it to begin with ( I think there is enough data about why to be found with google) but use a classifier that can deal with class imbalance instead.
I do however agree that there seems to be some kind of memory leak as it shouldn’t use that much memory. But my original point still stand in fact I’m even more certain now after seeing the SMOTE part. SMOTE + forward selection + what else? Not sure in the end what you are actually training on. I wouldn’t trust a model out of this pipeline at all.
@kienerj Smote doesn’t seem to play nicely with SVM either which is why I originally used a python script for oversampled class balancing, but I’ve now ditched SVM for speed considerations.
Don’t worry, our classifiers won’t be going into mission critical systems (yet )
Hi @christian.birkhold I’m getting the same problem on multiple systems, so I’m optimistic that you should be able to recreate it.
If anyone is curious, here’s a trimmed down worksheet and datafile (filled with random numbers) that are recreating the problem for me. You’ve certainly all given me ideas to pursue, in particular the warnings and the characters in certain cells of the dataset.
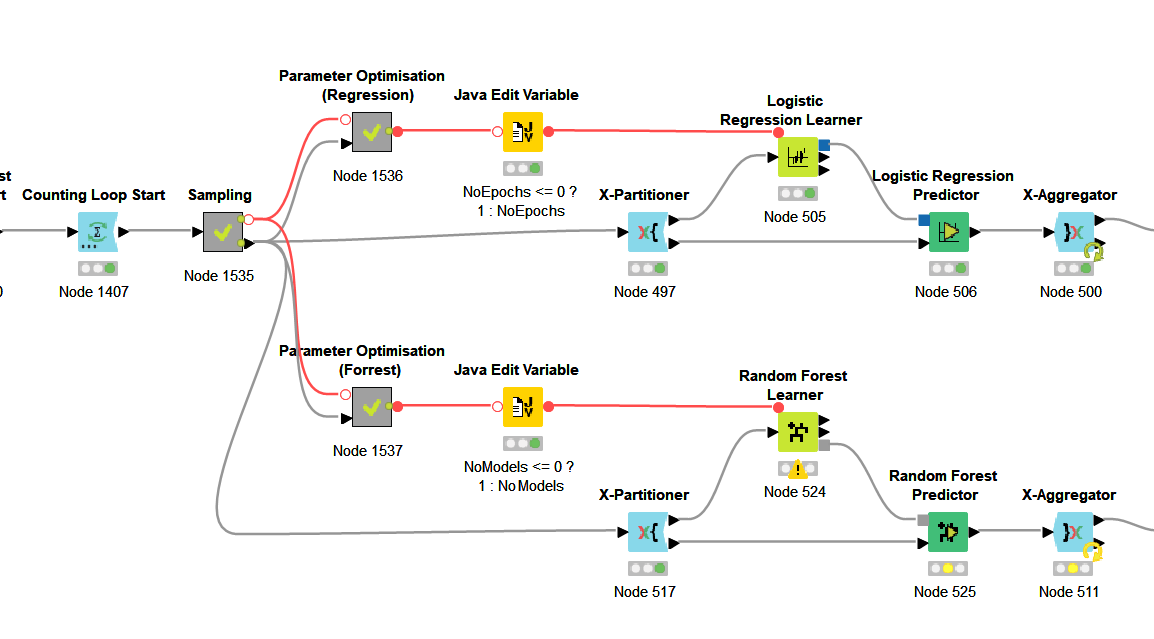
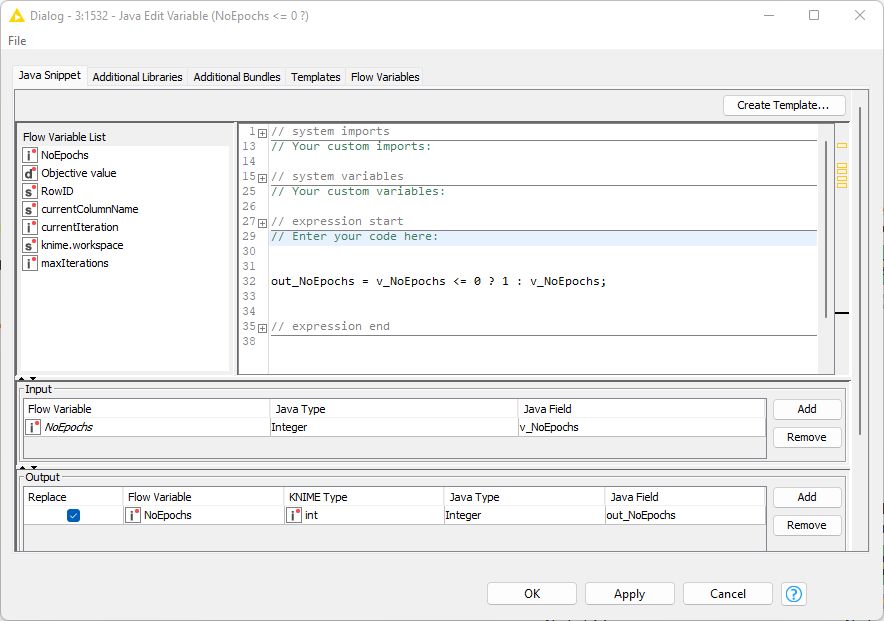
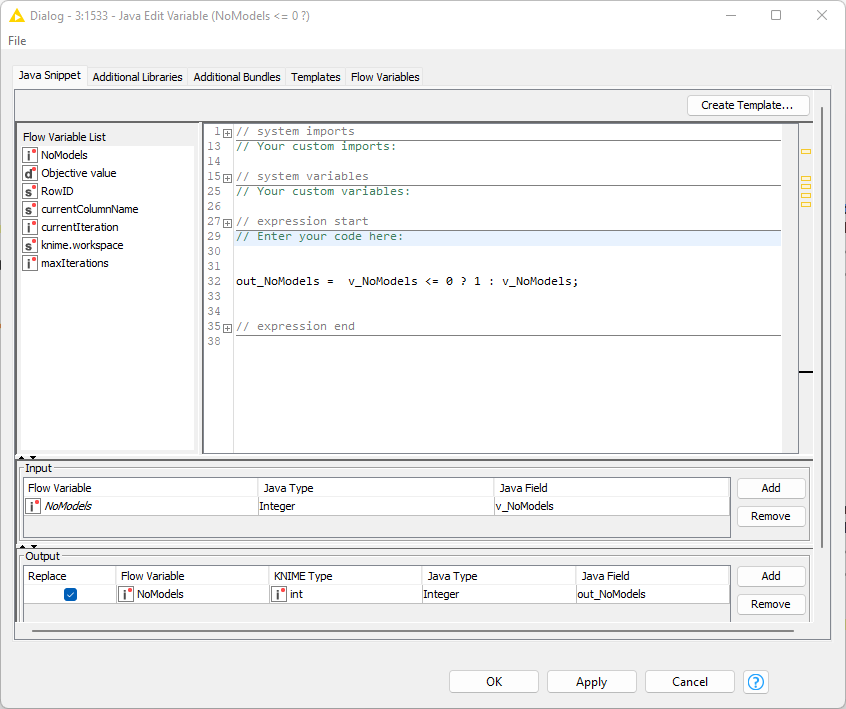
Thanks for the workflow and data. I ran it on my machine (Windows/AMD) and did see some increase in memory utilisation (non-heap) after about 10 minutes of running. I changed your workflow to add two Java Edit Variable nodes to remove the warnings generated by the learners which occur due to the input variable being outside the permissible range. I then ran the workflow again and didn’t see an increase in memory usage (other than what may be expected as results accumulate at the output). It’s not an exhaustive and thorough test, but may help.
Modifications to your workflow: The two nodes need to be on the variable input to the learners.
SVM is in my opinion pointless especially with such high dimensional data. It’s slow and usually gives worse performance than faster tree-based methods.
And say with xgboost you get class or instance weights to solve the imbalance. BUT: in general imbalance is not really a problem. It is only a problem if you have very few observations (eg 300) and then have imbalance on top so you end up with very little data points on the minority class. The issue is lack of data. If you had 100k observations, the imbalance would likley not be an issue. So even class weight are at best a crutch.
I can reproduce the problem - even switching off console logging or logging to knime.log. I’ll talk to the development team. Thanks for the patience and all the investigation.
Quick update: I was only able to reproduce the problem on Linux. Mac and Windows work as expected (thank you for testing @carstenhaubold and @tobias.koetter). That doesn’t make all of the debugging easier.
@DiaAzul did you see constantly increasing off heap (e.g. process memory > xmx) on windows?
I saw a jump in memory usage, but it could have been ephemeral. I didn’t have a lot of time for testing. I’ll see if I can repeat the test over a longer timeframe to see whether memory really was increasing or I was seeing digital ghosts.
Hi @kienerj These are the challenges of working in biomedical science. Lots of features (measurements), relatively few observations (patients) and often imbalanced (rare diseases). I dream of 100k observations!
Hi everyone. Thank you all so much for looking in to this. I’ve incorporated @DiaAzul 's suggestions and eliminated all the warnings (and removed null/? characters from input), but unfortunately it’s made no difference on either of the Linux platforms I’ve been using. However, I’ll dig out a windows laptop and try to run it on there to see what happens. Thanks for that tip @christian.birkhold It would never even have occurred to me to try that.
Seems to work without problem on Windows. Unfortunately, all the HPC to which I have access is Linux. Have to find some money to spin up an Azure Windows VM.