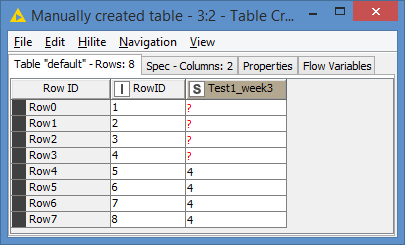
If I use joiner, of course I get duplicate columns for those columns that have the same name across the two dataframes (e.g: Test1_week3(#1))
I wanted to use concatenate, but it duplicates the rows (appending_dup)
Any ideas?
Also please notice that this is a toy example. I would like to know a general way of solving this problem, and not for this particular case, as the real data has dozens of columns with much more complex names.
Can we hardcode the “Test1” part, or does that change within one table as well?
Also, is it guaranteed to be one missing value, or can there be overlap? Not that important, but the aggregator method depends on that.
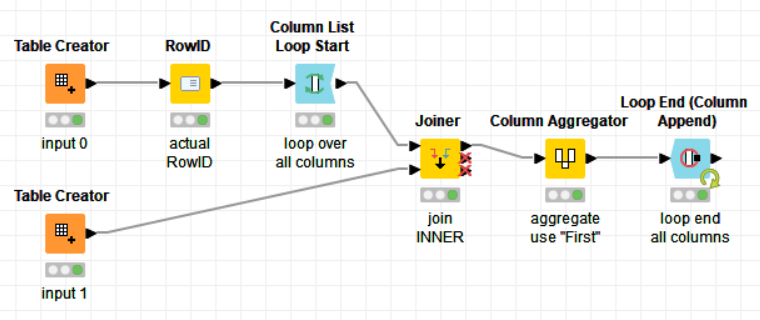
The right node combination is a Joiner and then either a Column Aggregator or a Column Merger. But since you have many columns to pair, we’ll need to loop over them somehow. Gonna figure something out later.
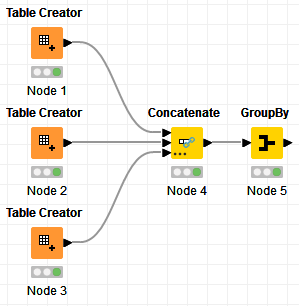
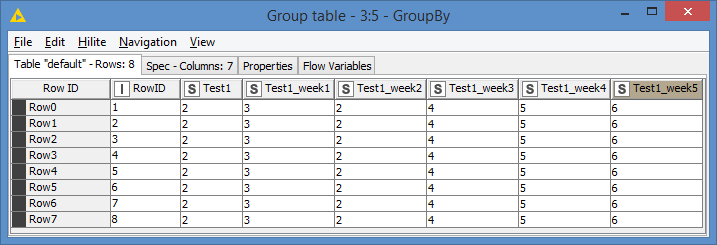
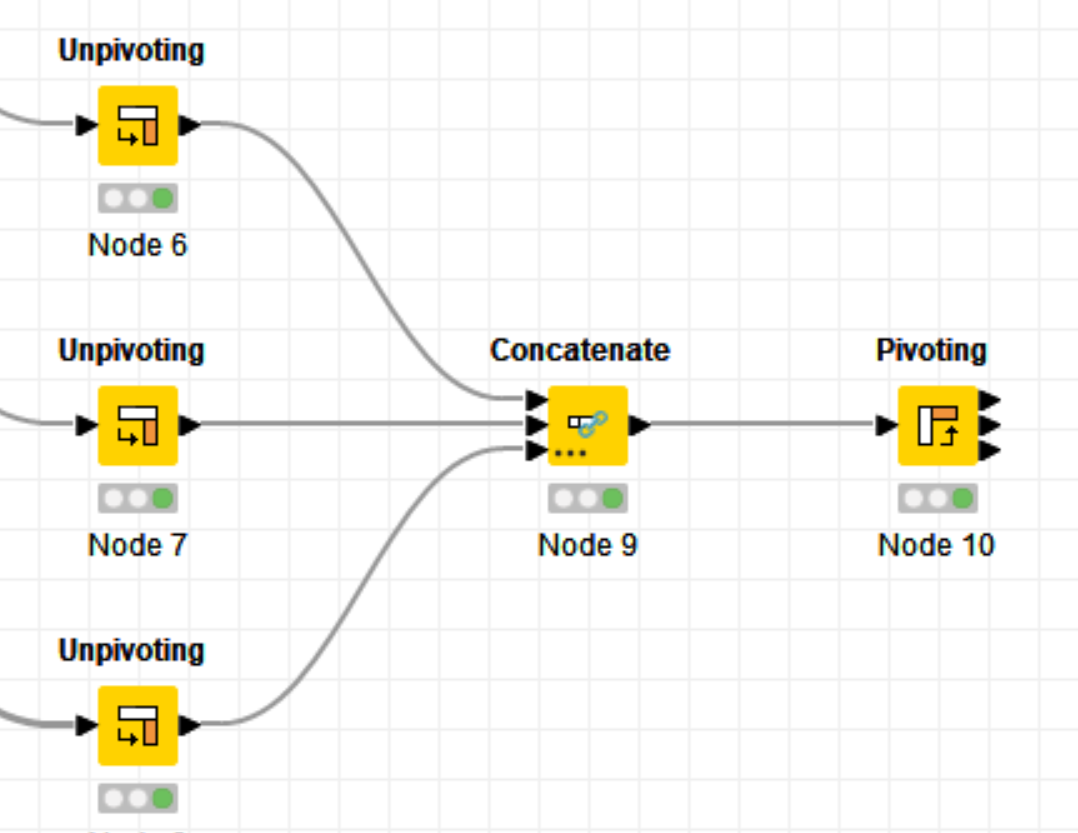
Hi @RoyBatty296 , here’s a different approach where I process them vertically with concatenation instead of horizontally with join. I then do a groupby RowID and choose the maximum value for each of the other columns.
It does not need any loop to process any number of columns.
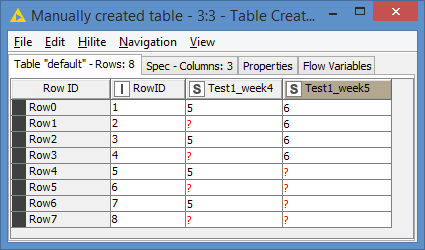
And to expand your use case, I created a third dataframe and added new columns to the first dataframe
EDIT:
Note: The reason why I chose to use Concatenation is because of the fact that the columns are the same name - that’s the basic rule of the project and that’s how the columns are identified.
I could not agree more with @Thyme 's comment, and it also helps the community that the solution was found.
Regarding the Joiner solution, it’s limited to two dataframes only, though to be fair, it is what the use case of the request. The concatenation solution does not care how many dataframes you have, since it’s vertical. You can have as many dataframes as you want. You just need to add more input ports to the Concenate node and link the dataframes, and that’s it.
For the joiner node, you would need to add additional layers of joins, and even if you get to join all the tables, you will get additional columns of (#2), (#3), etc… to deal with manually.
EDIT: @Thyme , it’s probably best to use the Column Merger in case of Joiner instead of the Column Aggregator, as the Column Merger’s purpose is to actually do what we’re trying to do. Here’s the node’s description:
“Merges two columns into one by choosing the cell that is non-missing”
@bruno29a Yes, but the Column Aggregator is easier to configure for this scenario. Not sure if it’s slower than the Merger, but with Loops that doesn’t really matter anyway.