I am not 100% sure what the question is. If flow variables do not show up immediately you could execute up to that point and try again or restart KNIME and start again. Or you could check with right click and the results of the previous node if the flow variables are there.
If you need more information on the location you could extract them.
And then it might make sense to open a new topic in the forum to asks your question.
From what I can see you don’t need to setup a variable at the List Files point since you’re telling the node to list the files from the folder that have the .txt extension. You will want to ensure that the Table Row to Variable Loop Start is just reading in the one file and that the file reader is set to the proper variable. Otherwise as long as those text files are the same shape you should be fine to loop over them.
@Tardispilot is correct here - you should apply the URL variable in the File Reader node, not the List Files node. (The URL variable doesn’t exist until the loop starts.)
Hi there, I suppose my question relates to this thread.
I am reading multiple (quite big by structure, 500K rows (roughly) and 158 columns (should be exact)) tsv (tab-separated values) files into one csv/excel. However, due to data quality (upon data recording) it happened that some files got less columns, i.e. 146 or 150. As I’m reading about 70 tsv files, it is quite challenging to go through each file and check if they are having the same number of columns or not. Moreover, as I’m processing each file (within the file reading loop), manipulating the data and transforming to a completely new table, it takes quite a long time. When such files with less columns encounter, the loop gives an error (for instance: “Too few data elements (line: 2 (File-3-Row0), source: ‘file:/C:/Users/KNIME/2W1P1.tsv’”).
I know that Concatenate Node takes care of different structured tables and concatenates tables even if they have different number of columns.
I thought the below settings would take care of the issue the same way the Concatenate Node does. But it seems not to be the case.
Can anyone help with this problem?
Thank you in advance.
judging by error message I would say it is reported by CSV Reader (?) and not Loop End node so option Support Short Lines in Reader node might help.
Two things to add. First maybe you can try to incorporate Table Validator (Reference) node into your workflow considering you are expecting the exact table structure every time. Second instead of CSV Reader you can try File Reader node if possible.
Give it a try and if any problems/questions feel free to ask.
posted this into the wrong topic :). I assume you are using the File Reader node so either you try setting support short lines in the reader (advanced options) as @ipazin already suggested or you use the CSV Reader node.
I’d go for the CSV Reader solution, because the File Reader has some flaws, i.e., usability inconveniences, when it comes to reading files, that don’t have identical structure, inside a loop. The error you’re seeing afaik is one of those .
Thanks a lot for your post! my apologies if this was not under the relevant topic.
Just like you and ipazin suggested, the option Support Short Lines turned out to be the solution.
I used to use CSV reader before and it seemed a bit rigid, moreover I was having some issues with it. Another reason for choosing the File Reader was my current files extension being TSV.
glad it worked out for you. No apology needed. Your question is on spot. Mark wrote his answer to another topic as well - that is what he meant by “wrong topic”.

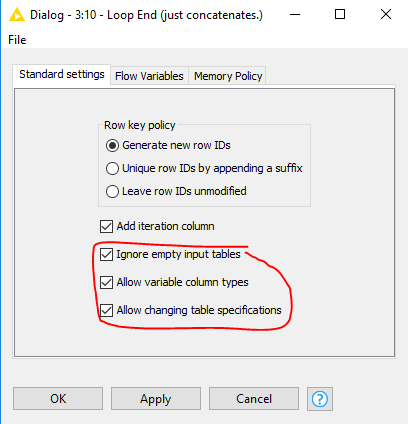
 .
.