Hi everyone, I am trying to Mix backward feature elimination + “optimal” clusters. So in this case I am merging two workflows: (i) the optimal number of clusters based on the silhoutte coefficient and (ii) backward feature elimination for clustering.
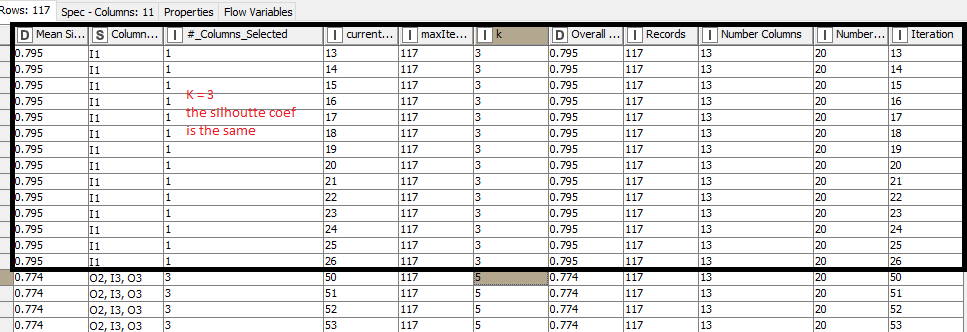
The problem is that the output shows the same silhoutte coefficient for a given k, so I expected that for each iteration the silhoutte coefficient should be different. The possible problem is because for each K the backward feature elimination just collects the best column combination for each K that maximizes the silhoutte coefficient.
I beg if there is a way to obtain all the possible values
First of all, sorry for the delayed response here. I showed this to some other data scientists internally and this is what I heard:
It doesn’t look like there’s anything changing in the loop other than k, which may be why those values are constant per k. Is there a reason why you’re running multiple times for each k? (Maybe it’s just a simple misconfiguration?)
If you’re trying to determine which features create the best clusters for a given k, the silhouette coefficient may not be a good metric, in that fewer dimensions in your data will always lead to a better silhouette coefficient when selected in this way.
If you’re interested in how many clusters there are, then you should use all available features. Clustering is an unsupervised learning algorithm, and not meant to minimize the loss function like supervised learning (where there is a model with known target).
Not sure how helpful this is in directly solving your problem at hand, but maybe if gives you some things to think about.