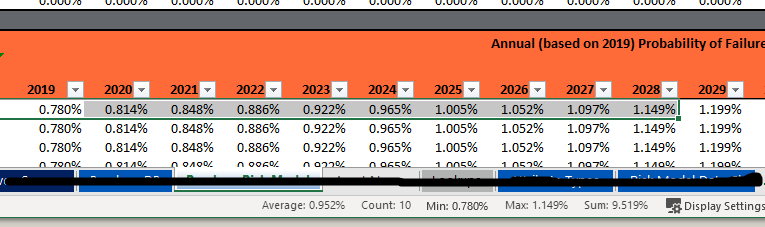
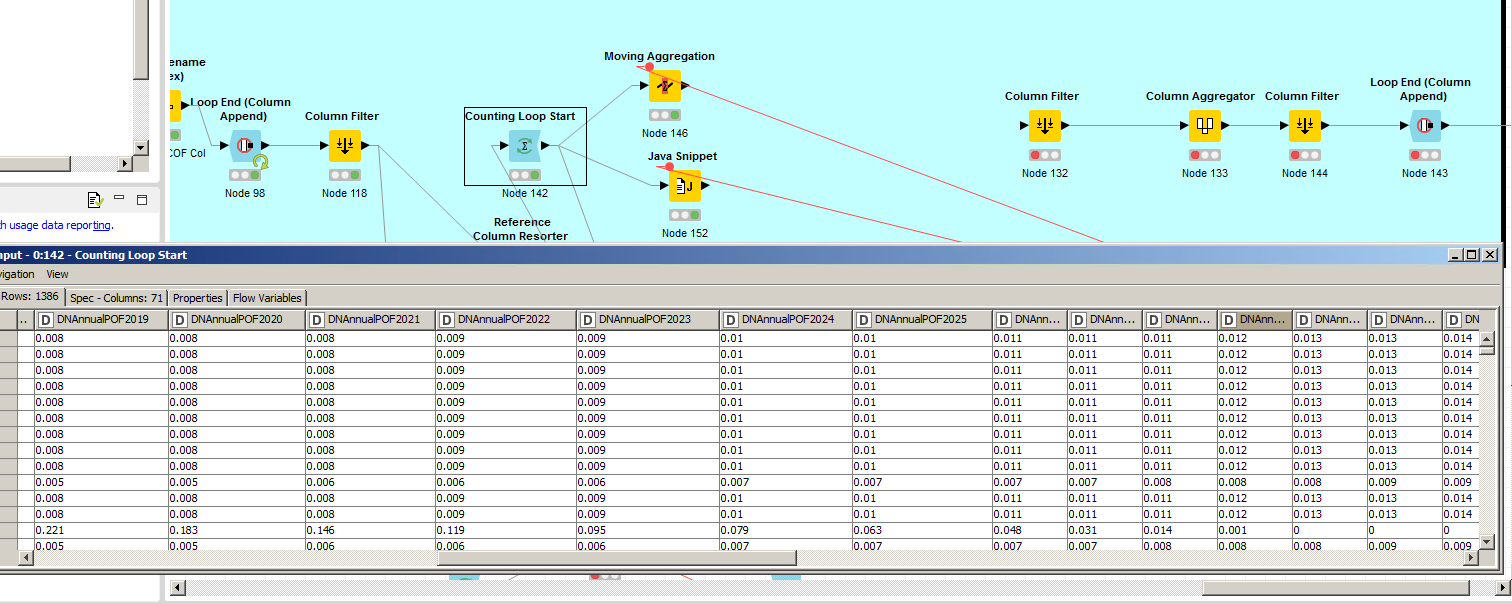
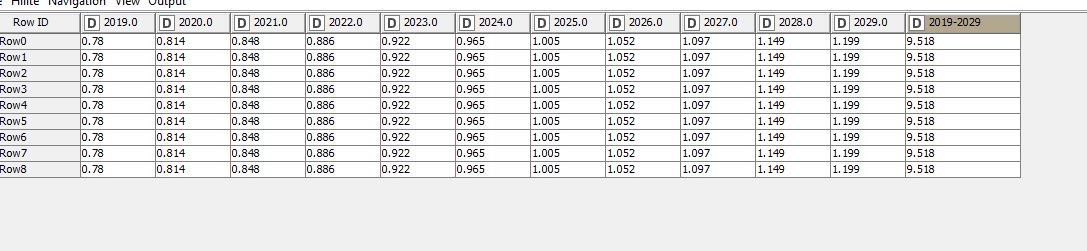
So I was using a nested loop to do this, then I found the Moving Aggregation node and got super happy! I have 30 years of columns “DNAnnualPOF2019” then 2020, etc. I need to create an aggregated column starting at 2019 for X years (11, in this case, but I’m using a flow variable for that) to sum the annual columns 2019 through 2029. Here’s what the source data looks like. For this row, I’d expect 9.519%.
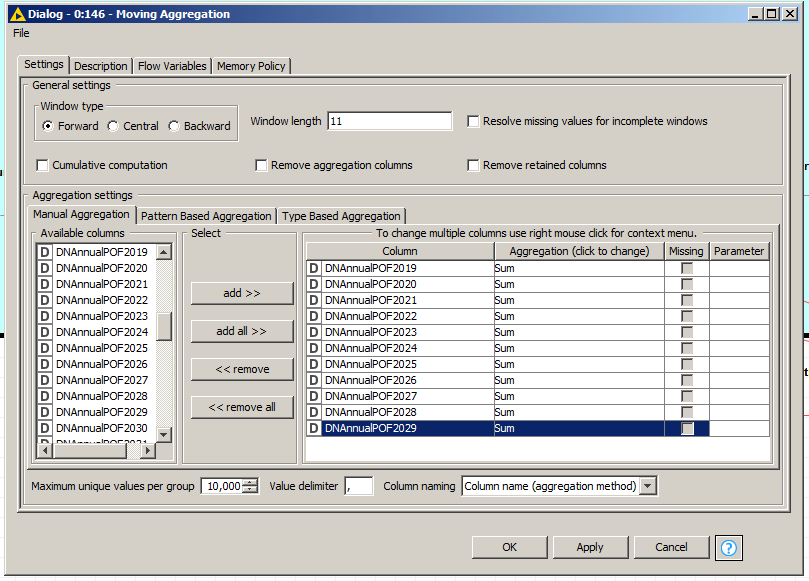
Here are my Moving Aggregation Node Settings. I have removed the flow variable for window length and the pattern based aggregation I was using (I was using DNAnnualPOF as the number of columns could vary greatly based on earlier inputs) in order to troubleshoot my issue.
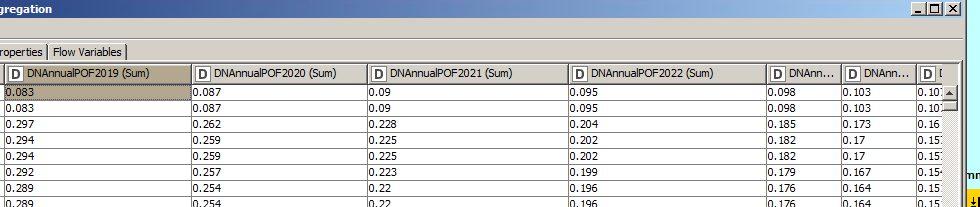
When I get the results…the sum doesn’t really come close? It shows 8.3%. I’ve tried adjusting the window up and down to see if I can get it to produce the right number, but I can’t figure it out. I’ve tried reducing the window down and it gets ‘more’ accurate as I reduce the number of columns I’m summing, but that really doesn’t fix my issue.
Okay, I thought this was a moving aggregation of columns, but apparently, it’s a moving aggregation of rows. That’s why it doesn’t work like I expected it to (because I can’t read!). Does anyone have a better method of looping through columns and creating a sum column for each result at the end than doing a nested loop?
Wonder if this would work for you…you will still need a loop to iterate through a decade at a time but at least you wont have to use a nested loop.MovingColumnSum.knwf (16.7 KB)
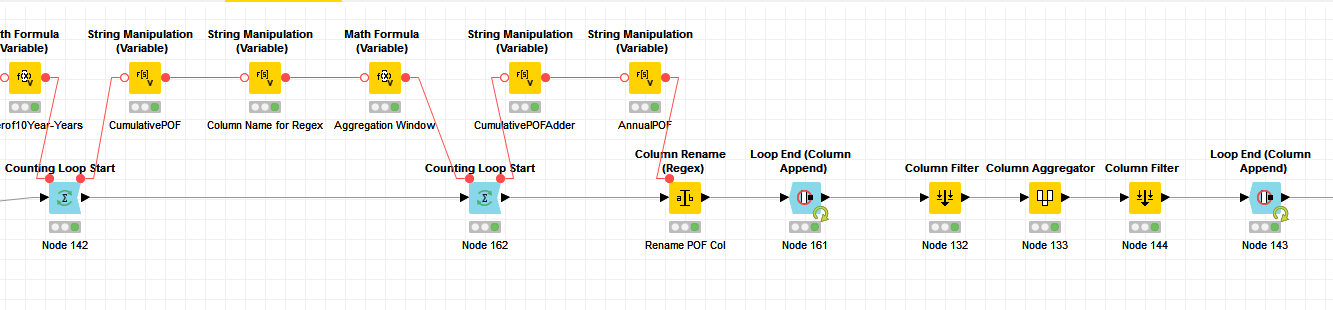
Thanks @agaunt. That’s a good idea I hadn’t considered. Right now I have about 1,800 rows, but eventually I’ll have about 2, 3, even 4 million. I could do it in chunks maybe? I did end up coming up with a solution, unfortunately through lots of trial and error. At the risk of revealing my lack of KNIME experience, I’ll post what that looks like. I found out after my posts that the first column is always the same, but the number of columns to be summed (including the first one) changes with each iteration. So I bring in variables before the first loop for the first year (2019) that needs to be done and the first count of columns to be summed for each row (11). The interior loop renames the 11 columns to have the same naming convention. Then I aggregate using wildcards after that loop completes and append with one column for 2019, with the sum of those columns for each row. Then I use the current iteration for the outer loop to both increment the year to 2020 and the column count to 12…then repeat the process.
Have you tried using the Column Aggregator node? Unless I’m missing something obvious - entirely possible! - that should be all you need to sum up column values in the same row. No looping involved.
@heshanhenry Sorry! I didn’t see your post for some reason. Thanks for the workflow! It seems like you and @agaunt both suggested the transpose method. I may give that a shot.
@ScottF Let’s take this example. I have a number of annual columns from 2019 through 2059. I have the following variables:
Sum Columns = Number of aggregated columns to produce = 20
Sum Start = Currently a constant, but could be variable in the future = 2019
Sum Distance = Number of columns, including Sum Start, to aggregate = 10
Sum Column Name = “Sum” & (Sum Start + Loop Counter)
So…
Sum Column1 (“Sum2019”) = Sum of Columns from Start through Sum Distance (2019 through 2028)
Sum Distance += 1
Sum Column2 (“Sum2020”) = Sum of Columns from Start through Sum Distance (2019 through 2029)
…
Sum Column20 = (“Sum2038”) = Sum of Columns from Sum Start through Sum Distance (2019 through 2047)
Can the aggregator do that w/o a loop?. I think the moving average may work if the transpose isn’t too taxing on the system.
Ah, OK - in that case a transpose approach may be better. There probably is a way to do this using Column Expressions, but it would involve a lot of flow variable manipulation, and I’m not sure it would be any easier to deal with than what you already have.