Since you dont have a model yet, I would suggest you to first go for a “easier-to-handle” model like Random Forests. They can do both: classification and regression. And they happily work without burdens like standardization / normalization etc. Later on you can replace them with DL if you want and try to better the performance. That is easy once you have your workflow.
while I agree with mereep for the general case, this is actually a very nice use-case for deep learning.
Essentially you would have to modify this example workflow to fit your setting.
The mentioned workflow shows how to perform transfer learning i.e. how to adapt an already trained model to a different task than it was originally trained on.
Alternatively, you could train a new model from scratch but 2000 images are probably too few to make that work very well.
Anyway, I have to add the disclaimer that a DL based approach is unlikely to work out of the box and will require you to invest some time into learning a bit about DL.
Hi @mereep. I tried to perform the RF example you suggested, but the Tree Learner only accepts "Column attributes that are ordinary columns in the table (e.g. String, Double, Integer, etc.) as attributes to learn the model on. So this approach is not going to work for me since I need the model to learn on images as well as numerical values.
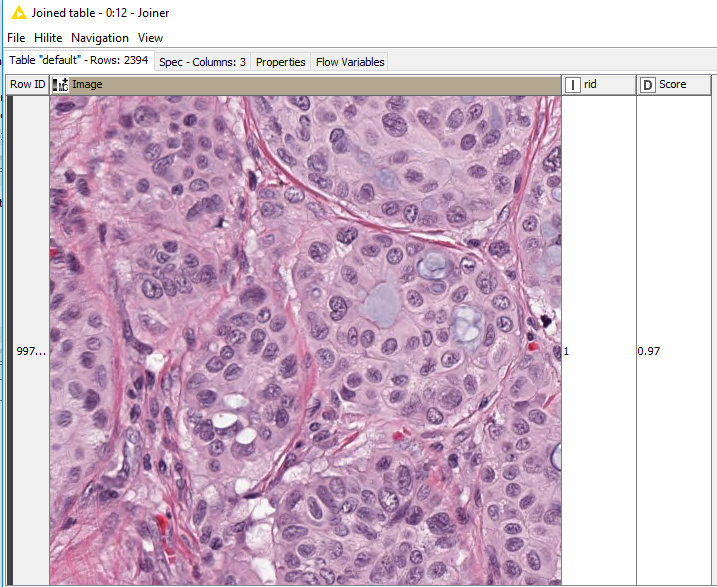
I have my ~2K labeled training images in my joined table (joined with their respective attributes RID and Score). I need to build a model to predict the RID & Score of 200 similar unlabeled images after training a model on ~2K labeled images. The goal is to build a model that can automatically score these type of biological images, with no labels.
ROW ID contains my image file name, RID = the anatomic region, and Score = the toxicity level.
technically it is possible to train an RF based model but you would have to extract features from the images that an RF understands using e.g. the feature extraction nodes from the KNIME image processing extension.
However, as I explained in my previous post, your task is well suited for a deep learning based approach.
My first approach would be based on transfer learning because 2000 images are too few to train a model from scratch.
Your images look large enough to easily work with models such as VGG, Inception or ResNet which makes it even easier to adapt the example workflow I mentioned in my first post to your needs.
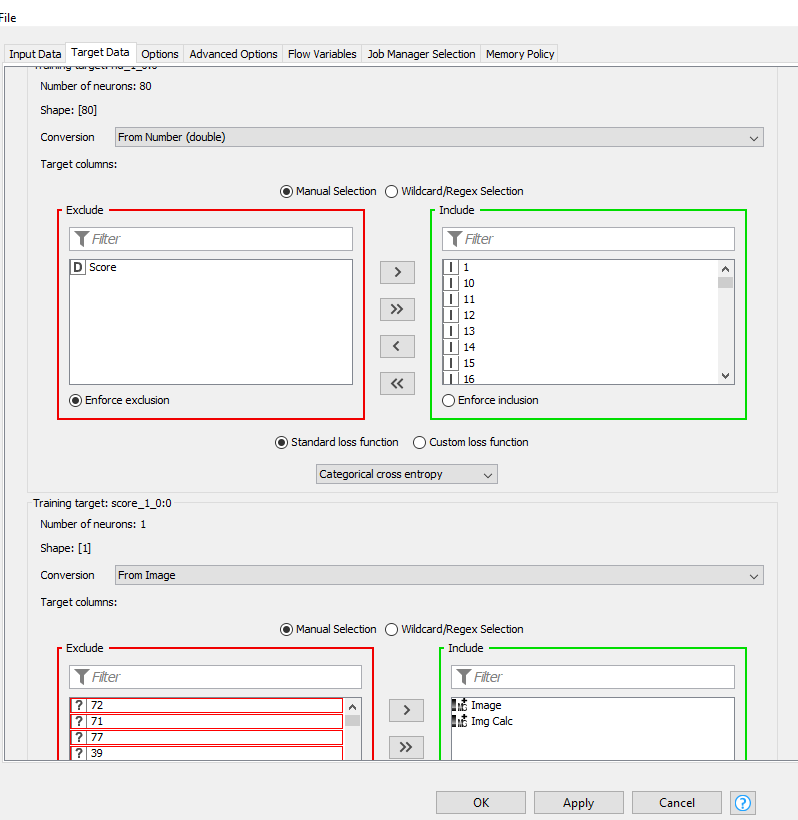
You only have to replace the single output layer in the example with two output layers, where one has 80 units and a softmax activation to predict the anatomic region and the other has only 1 unit and a sigmoid activation to predict the toxicity.
see the attached workflow for an example of how you could tackle the model training. TransferLearning.knwf (15.5 KB)
Ideally you only need to replace the Data Generator node with your input pipeline.
Note that it is crucial to normalize your images in the way the pretrained model expects.
For this, you can replicate the input pipeline of the workflow I linked in my first post.
Thank you for this @nemad - I really appreciate it. I would like to attempt over the weekend; I am still having an issue getting the Python extension to work on my Windows machine, so I cannot start until I fix this. Any chance you could assist with my open post on this? Setting up the KNIME Python extension on Windows with Anaconda Installed
Also, @nemad - can you please elaborate on the "Your images have
to be normalized between [0, 1] " - I have 2K+ images; is this performed by hand? Any detail you can provide is appreciated, thanks.
Here is an updated version of the workflow that includes the normalization as well as some additional preprocessing for deep learning: TransferLearning.knwf (38.2 KB)
Hi @nemad. I made some great progress - I was able to fully establish my Python and Keras environment per the help of @christian.dietz.
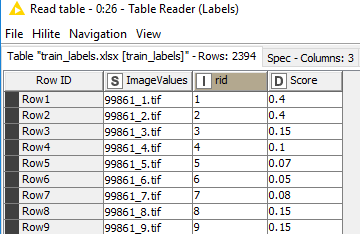
First: I’m having some issues with how I “read” and label my images via the “joiner”. I want to create a table that has (4) columns: Image Name, Image, RID, Score. Currently, I have (1) table and a set of images I want to join, they are in screenshots below. My join is adding “RowID” after the image name, today, which is not what I want.
I am not sure if I understand your first problem.
You can simply use the joiner node to join the image table with the table containing the labels by specifying that the joining column for your image table is the Row ID and the joining column for your labels table is the ImageValues column.
The images are now converted to float values within the range [-1, 1], unfortunately it is currently not possible to see the actual content in the KNIME table view because it only supports values in [0, 255] for display. However, if you open the view of the Image Calculator and click on an image you will see that the images are still valid.
What you need to do for the rid column is to add the possible values to its domain.
You do this by making sure that it is in the include list and the checkbox “Restrict number of possible values” is NOT checked. Then you can use the one-to-many node to create the “one-hot” columns for the rid column that will serve as target for your classification.
I’m getting close - I was able to join correctly, perform the image calc, and execute the domain calc w/ one-to-many hotshot.
My issue is now with the Keras Network Learner; I get this issue:
WARN Keras Network Learner 3:6 failed to apply settings: More target columns selected (2) than neurons available (1) for network target ‘score_1_0:0’. Try removing some columns from the selection.
As I get deeper into this, I’m starting to realize that maybe it would be better if I split the problem into (2); first, tackle RID, and then tackle score after, then just document the predictions in excel after (copy & paste).
This is a hard problem from my advisor, so it is not supposed to be easy
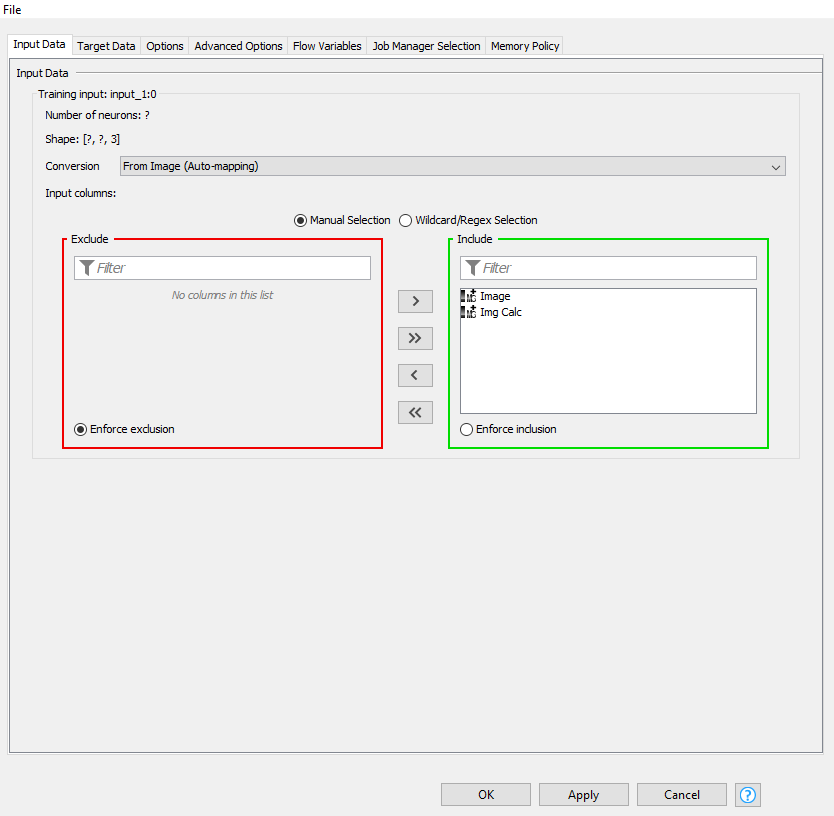
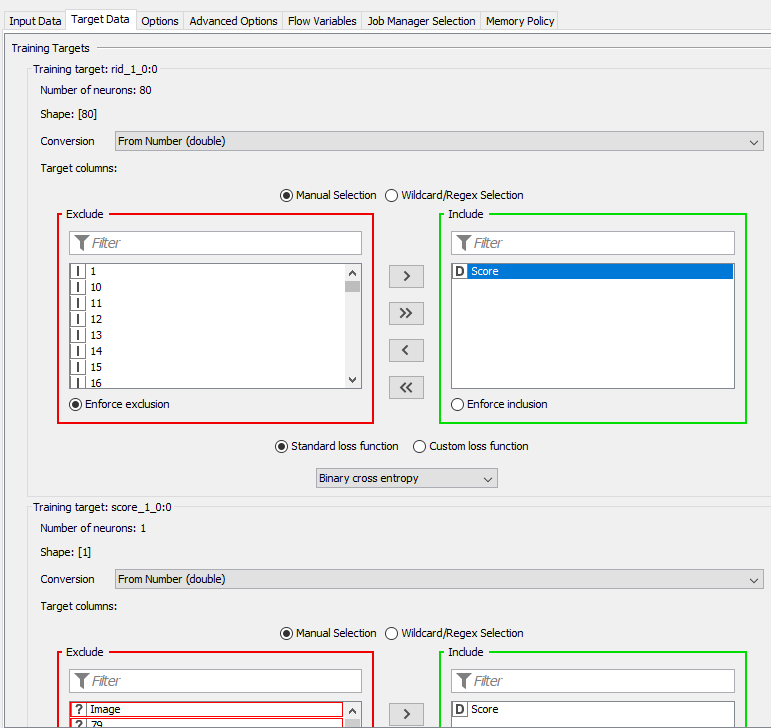
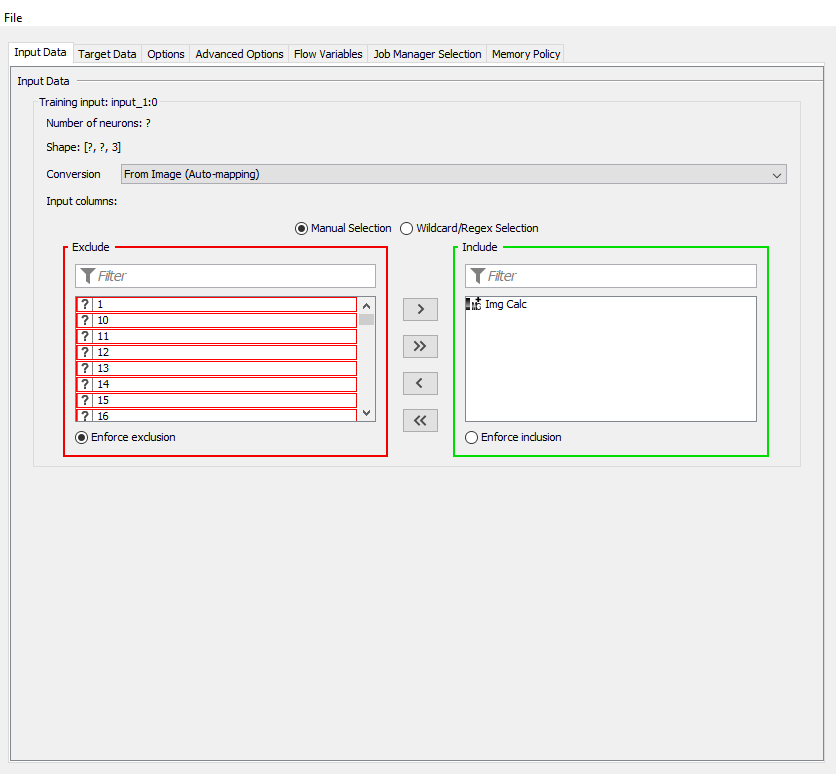
your inputs for the images and the score target are incorrect.
For the image, you need to only include the Img Calc column and for the score, you will have to switch the converter to “From Number (double)”, you should then be able to include the score variable.
Make sure that you select “Binary Cross Entropy” as the loss function for the Score target.
Don’t give up now, you are almost there
That is not to say that you shouldn’t also try different strategies but I would suggest to first get this approach to work, as you already put a lot of effort into it.
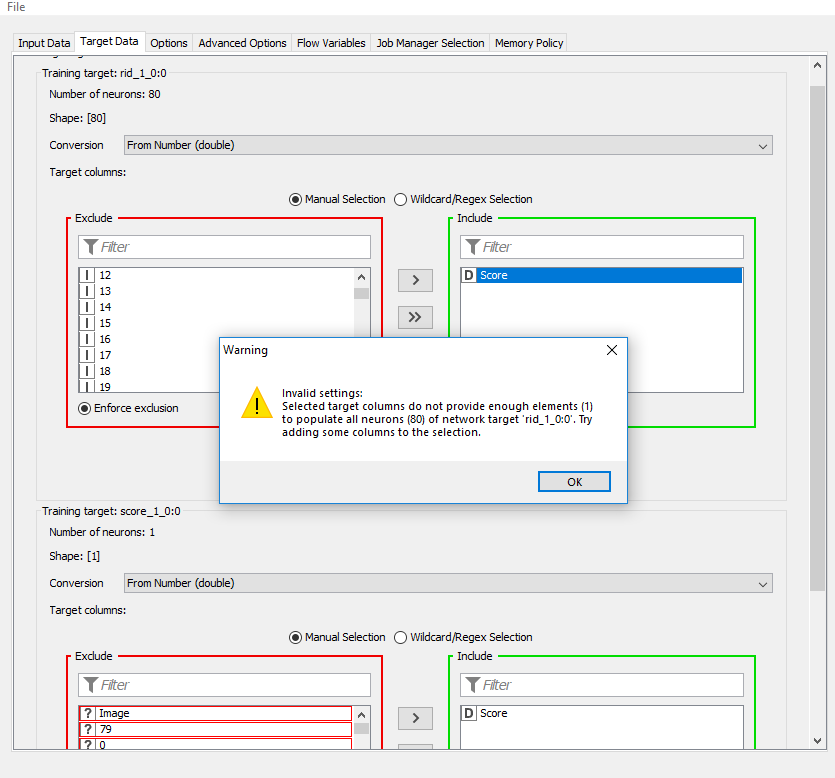
I gave another shot at this and I’m still coming up with errors; its now telling me I do not have enough “target elements”.
In the simple terms I want to build a model with (2) Inputs:
Image
RID Label
I want then want the output to be the Predicted Score (toxicity). I have labels for RID and Score, but Score is my target. I’m confused about if I should be using the score as an input or not.
ok maybe I misunderstood what you are trying to achieve.
I thought you wanted to build a model that can predict both, the rid label and the toxicity score.
The workflow I provided above does that but their is still a small mistake in how you provide your targets.
For the first target (rid_1_0:0) you have to exclude the score and instead use the 80 integer columns that were created by the one-to-many node. They represent a one-hot encoding of your rid classification.
You should also switch the loss function from Binary cross entropy to Categorical cross entropy since I assume a sample can’t belong to multiple regions.
If you can provide me with a small subset of your images I can set up the workflow properly so you only have to run it.
Thanks for your quick reply @nemad and continued support & patience - I appreciate it.
Yes, the model requirements have changed - the RID will always be provided in the test set; Score is the constant unknown which I have to determine in the test setof 1K images.
A few more facts about the training set:
Consists of 2K~ images, for which the RID (region) and Score (toxicity) are labeled in a ground truth CSV.
There are 77 possible regions (RID) and 31 values in the range of toxicity scores (integers and decimal between 0 and 1) from which these 2K training images are labeled. (0 = no toxic cells present, vs. 1 = 100% toxic cellularity)
The images are based from about 32 different patients (for which a patient ID exists, but not needed at this time, since I need to be able to score on unknown patient images)
RID = the region from where the biopsy was taken from. That said, a toxic (.50 score) sample from let’s say RID #1 could look very different from an equivalent .50 toxicity sampled from RID # 77. (this can be due to the level of fat/muscle existing within or not, in a particular region).
I need to train a model, that can predict scores of any non-labeled images submitted to it, to give the highest probability of the Score. In the end, I need to be able to run inference on the model once complete, using random batches of images.
My advisor believes this can simply be achieved via a regression model; I thought it could be done via classification with the proper last layer and activation function. I am not certain on how to build this, because I have not observed any similar examples in the forums/posts and because I am new to the platform.
If you have any thoughts on how to build a regression model in KNIME, or if you observe a better way to tackle this, I am open to your ideas. I would like to create a project in the KNIME community, covering this use case, once I have success.
I actually spend quite some time with your data but I had some troubles with my hardware which prevented me from creating a fully deep learning based workflow.
However, I also tried a different approach which also uses a deep learning model but only as feature extractor.
The rough idea is to feed the images to a deep learning model (e.g. InceptionResNet) which extracts a feature vector describing the images. These features are then combined with the region indicator and fed to a “shallow” learner e.g. the Gradient Boosted Trees Learner.
If you already updated to KNIME 3.7.0, you could also use the new XGBoost nodes which have the advantage of supporting logistic regression (the targets all lie in [0, 1]).
Note that it uses the mentioned XGBoost nodes, so you will need KNIME 3.7.0 to use it.
If that’s not possible, you can simply replace the XGBoost nodes with Gradient Boosted Trees or another KNIME learner (and consequently predictor).