You could use a combination of loops to extract the necessary informations. The File Meta Info node could provide you with information about when the file was last saved if you do not want to use the file name itself.
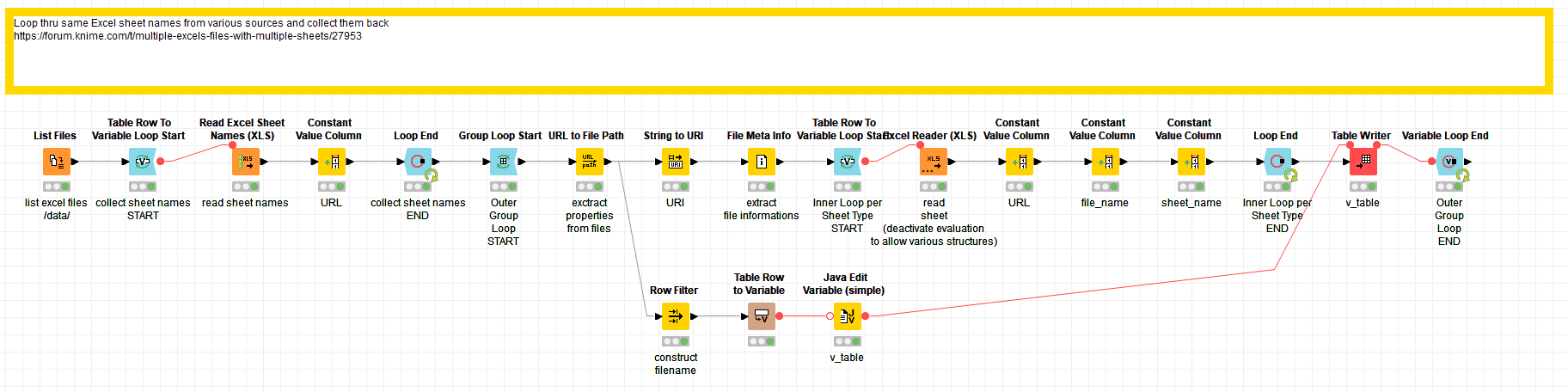
If you want to explore further options how to deal with Excel import you might want to have a look at this collection: