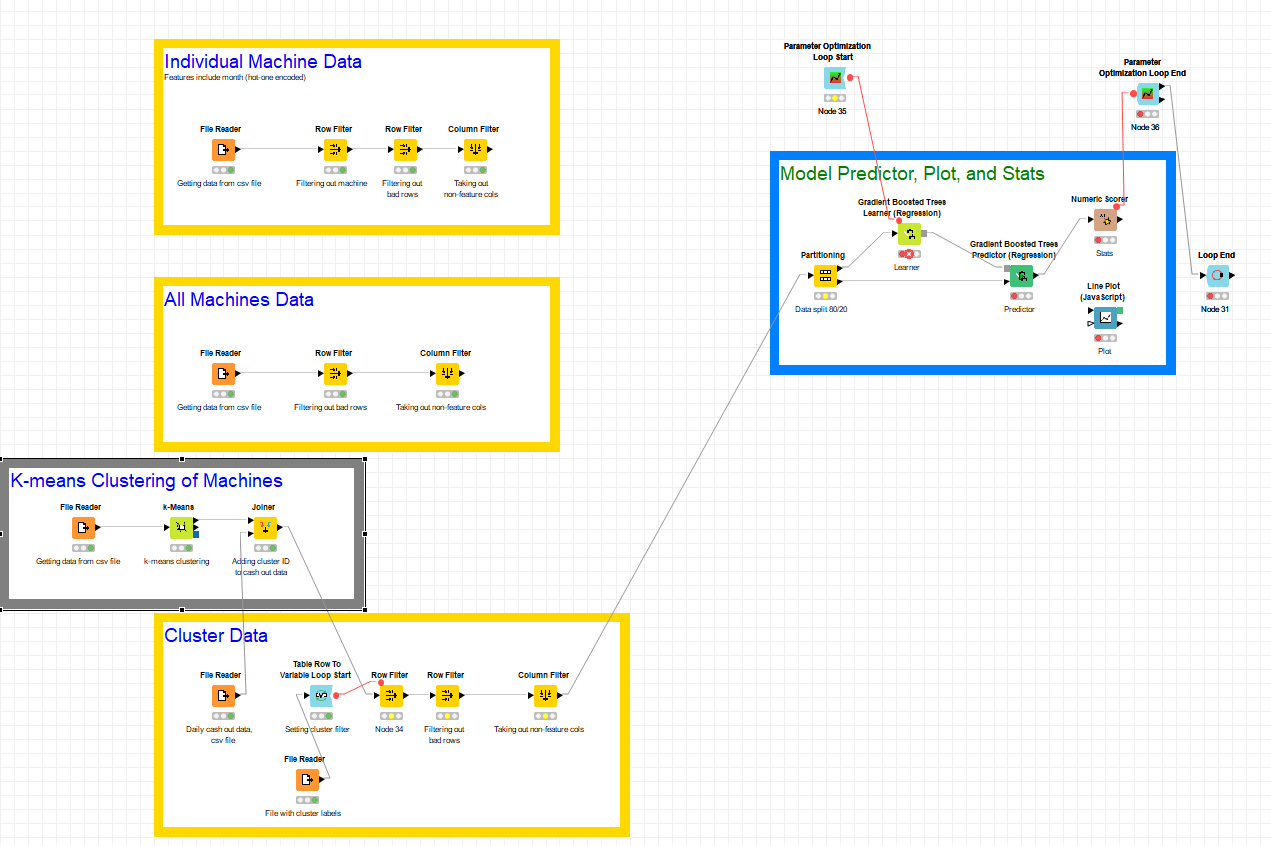
I am creating some clusters with k-means and then I want to run the gradient boosted trees model for each cluster. I have the Table To Row Variable Loop to read a file that has the cluster labels so that I can filter the data for a particular cluster (if you know a better way to do this, please share). Then, I pass that data to the model, where I want to use Parameter Optimization. The error on the Learner node reads: Can’t merge FlowVariable Stacks! (likely a loop problem.)
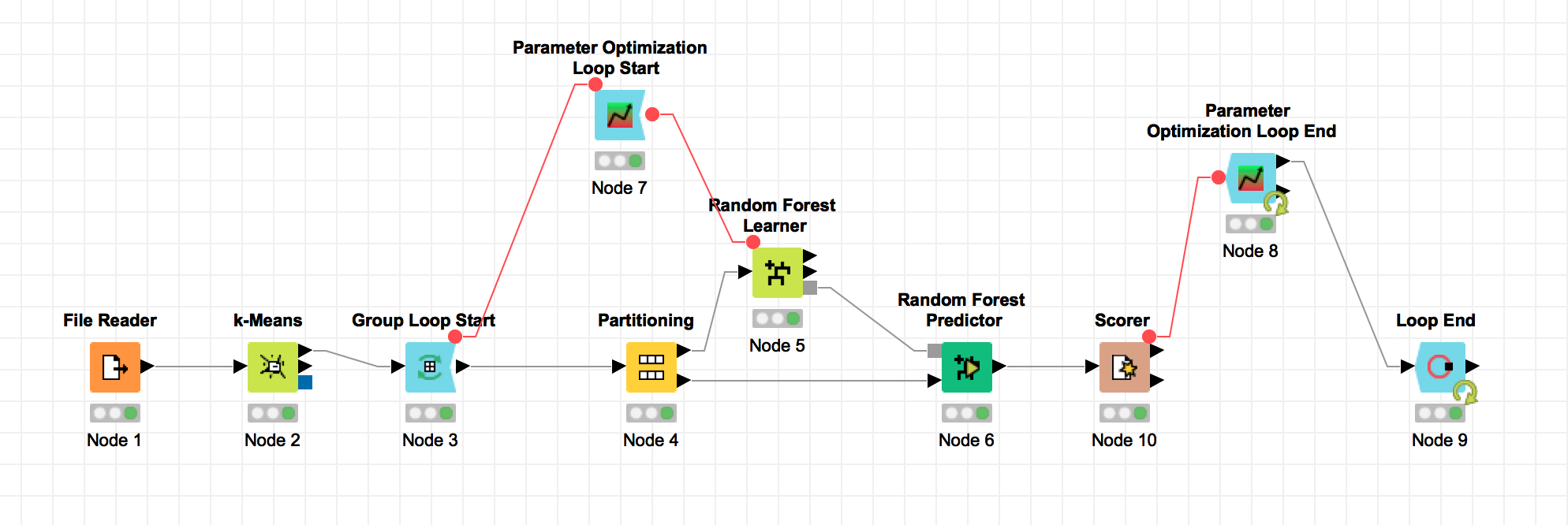
As you have the cluster labels, you can use the Group Loop Start node (instead of the Table Row to Variable node) and group over the cluster labels.
To solve your error message, you have to tell KNIME, which is the first loop start node. To do so, you can connect the flow variable output port of the group loop start node with the flow variable input port from the parameter optimisation loop start node (see attached screenshot).
I have a follow up question regarding this loop: right now with the setup that you suggested I can only see the collected results from the Parmeter Optimization, but I also want to see the Scorer results for the iteration with the best parameters. I tried connecting the scorer to a 2 ports Loop End but this was not succesful (I get the error: Branches are not permitted to leave loops!). Is there a way to do this?
Retrain the model with the best set of parameters (if you set the static random seed in the learner node you will get the exact same model again)
Write the output table of the scorer node in each iteration with a table writer node and a changing file name. Then read only the table of the best parameter set.
If you want to continue with the second approach, please let me know and I can build a small workflow for you.
I would like to continue with the second option since this will also serve me later. I would like to store the stats for the model trained with the data from each machine in a cluster individually and then do an analysis of those results with the results of the model trained with the data of the entire cluster.
I would appreciate it if you can help me building a small workflow.
attached is a little workflow. The idea is that we create a flow variable with the output location inside the loop. The file name contains the current parameter settings, in my case the number of models, and the current cluster, so that the output location is different in every iteration.