I have a similar issue. When reading in multiple files, one of my columns has decimal values in a couple of files and the other files don’t have the values as decimals (for the same column). With the preview set a 50, KNIME defaults the type to Integer in the new Transformation tab. When I try to execute (with the preview setting), the errors out with the attached error. If I remove the limit for the number of rows scanned (basically read the whole file) I can read in the files successfully. The problem I have is that the source files are large so this is a bit time consuming and sometimes doesn’t work. In the transformation type, the only option initially is change the type in the numeric columns to (Integer or Long), why wouldn’t Double be a valid option also?
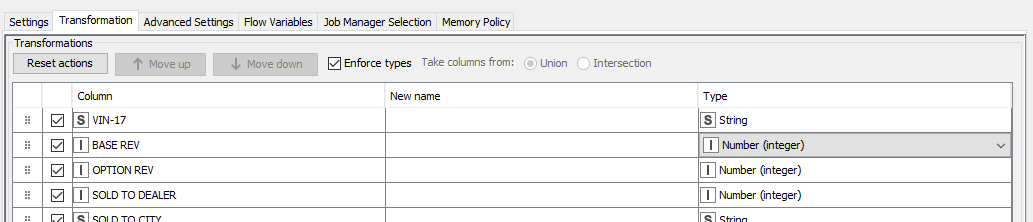
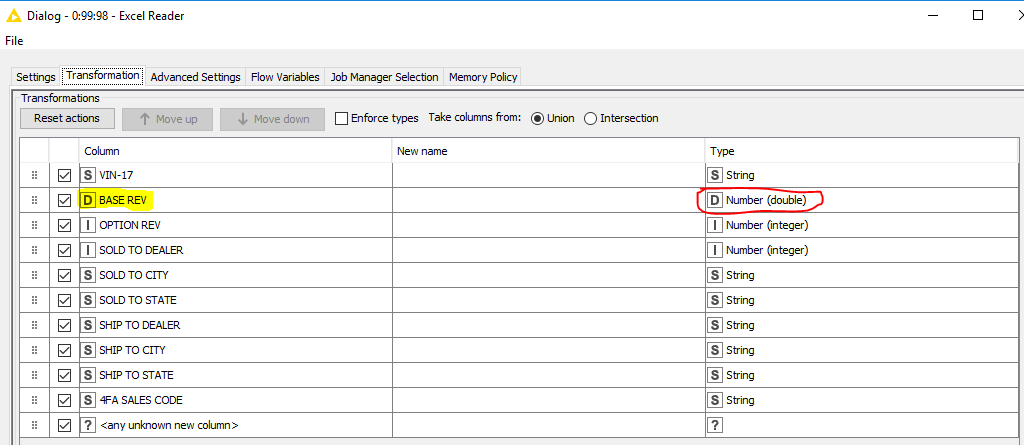
Once I scan everything, KNIME defaults the column to Double
knime_excelReader_dType_error.txt (3.5 KB)