I have to iterate over each and every row in a column, and if that meets a specific condition, I need to simultaneously iterate over each and every record in another column as well. Is there any possibility of achieving this using knime and without python as we don’t have access to it at the moment.? Also using the version 4.1
Hi @Saishiyam
Welcome to community
Maybe you can try:
Different Loop Start nodes (Group Loop Start ?)+ Table row to variable + (Rule Engine node ?) + Loop end node
1 Like
Hi @Saishiyam and welcome to the Knime Community.
You almost never need to manually iterate over each rows as Knime automatically does this for you.
For example, if you have these row values:
1
2
3
And you want to multiply each row by 2, you just need to apply a Math Formula where you take the column and multiply by 2. Knime will multiply each row of this column by 2 for you, without you having to manually do it row by row.
This means that you almost never need a Loop to do this. That being said, of course Loops exist, but they are used for some specific cases, such as if you want to process your table in batches for example, or by groups, of if you have multiple variables that you need to apply.
Based on what you are saying, it seems like you want to compare values from a column to a specific or all the values of another column, is that correct? You may need to use the Lag Column node, or a Joiner node to do this. Using a Loop would be so slow to do this.
May be you can provide some sample data along with your explanation to make sure we understand what you are trying to achieve.
3 Likes
Hi @bruno29a.
Thanks for the answer. Here is a sample data and how it has to be done:
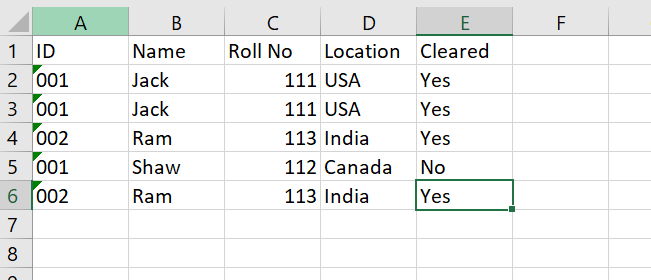
So I have to start from Column A. I have to compare each ID with every other ID present in the same column. so for eg: If two records have same ID (eg: 001), then I would move to the next column ie Column B and check if the values are same again, so this would be done for until Column D. So if all the values are same, then I need to mention “yes” in the cleared column.
So basically, I can achieve this using two for loops in Python outside KNIME as we don’t have access to it yet.
Is there any way to achieve this without Python?
Hello @Saishiyam ,
You actually don’t need any complex coding to achieve the result.
You can complete this task with:
- ‘GroupBy’ node. and count any column (i.e. creating a constant one).
- Rule Engine node with a rule about COUNTING > 1 “Yes”.
- And finally a Joiner with the input data to transfer the Labelling (Yes/No) from the results.
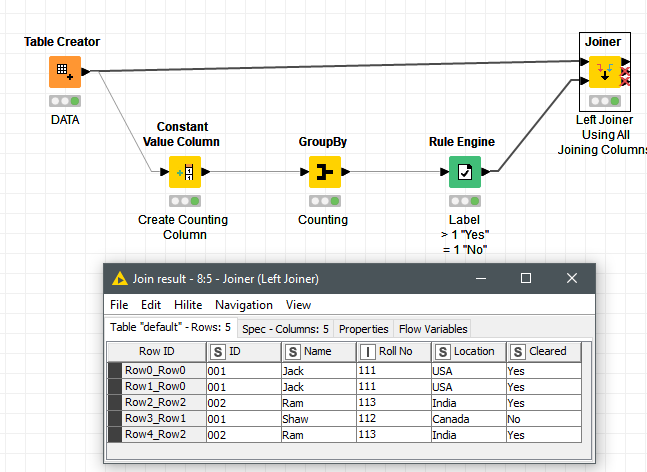
20220127_labelling_duplicates2.knwf (28.0 KB)
BR
2 Likes
Hi, thanks a lot. But what if I want to compare one record with every other record in the same column, and then validate them, and based on that I need to move to the next column. There will be many conditions on which I have to be validating. Will the same apply there as well ?
- The GroupBy Node performs aggregations on a per group basis. Rows in a single group have to have the same value in all group columns (ID, Name, Roll No, Location). Any rows that share the value in all 4 grouping columns will be in one group.
- The aggregation is to simply count the rows in each group., so we get a table with one row per group and a column holding the group size.
- That group size is translated into “Yes/No” with the Rule-Engine.
- Finally, the “Yes/No” column is joined with the original table, using the same 4 columns that have been used in the GroupBy.
So in the end, rows that have at least one matching partner in all 4 columns will be assigned “Yes”, otherwise “No”.
2 Likes
May be I can’t see the full scope of the challenge. What we already have done was basically check for row duplicates in the whole data as stated in the provided sample.
You can use the Group By on every column against itself doing sophisticated loops. You will get a matrix of Yes/No with the same size as your current data; but in this approach a row all filled with Yes, would not guarantee that the row (as it is) is repeated in a complex data set.
Another more comprehensive way to achieve your sample result, would be with a String Manipulation node with joinSep rule (ie: “,”) joining all the values in the same row. And work with a GroupBy node around this column.
BR
You may be interested to have a look into this. This past challenge came at this point to my mind.
@Saishiyam Regarding the “many conditions” part in your follow up:
Is it just more columns that need to have the same value? Then you can add them to the Group Columns in the GroupBy Node (and also the join conditions in the Joiner) and you should be fine.
If not, and those other conditions are different, can you explain what those are?
This topic was automatically closed 90 days after the last reply. New replies are no longer allowed.