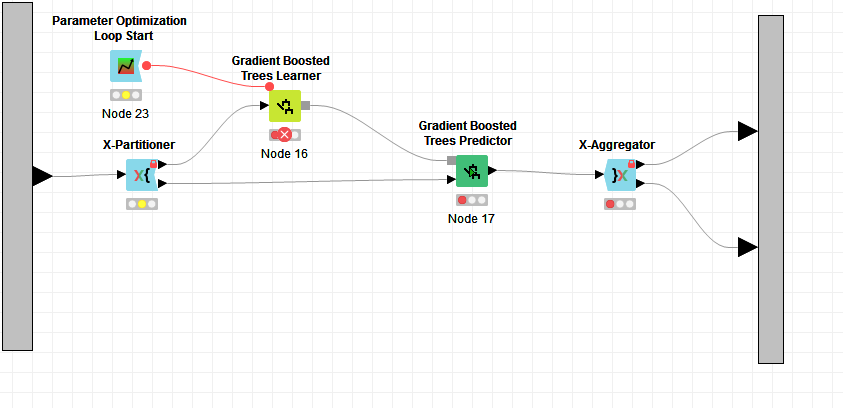
Im relativly new to knime analytics. I tried to calculate a Gradient Boosted Tree wit Cross Validation and Parameter Optimization. For the Cross Validation I used the Metanode ad ist works very well. If I connect the Parameter Optimization Loop Start Node to the Learner I got the following Warning:
“Unable to merge flow object stacks: Conflicting FlowObjects: <Loop Context (Head 0:0:23, Tail unassigned)> - iteration 0 vs. <Loop Context (Head 0:0:2, Tail unassigned)> - iteration 0 (loops/scopes not properly nested?)”
Does anybody know, what tha means and what can I do, that my workflow works?
I tried a second workflow, without the metanode for cross validation and I got the same warning. Furthermore Im not totally sure, how to integrate a Parameter Optimization into the existing Workflow (Picture 2)
at the first glace, it seems that the issue is that you have multiple (two in this case) Loop Ends per Loop Start. This will not work. It you want to test two different models to be trained, you can set two independent hyper-parameter optimisation + cross validation branches
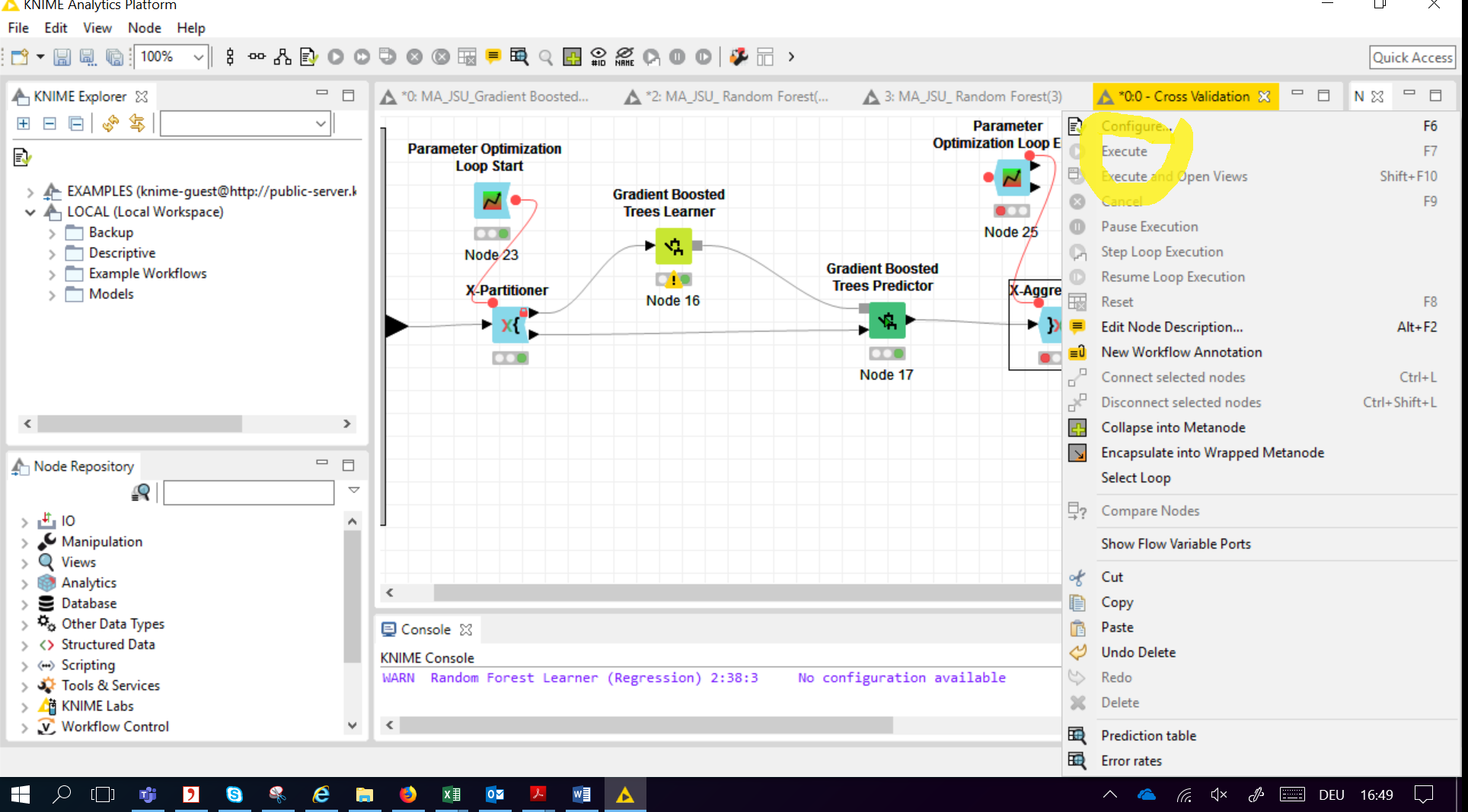
if in the bottom picture you delete node 11 (Scorer on top-right) you will still have 2 loop ends connected to the same loop start. For example you have nodes 23 and node 24 both closing the hyperparameter loop started in node 23. And also nodes 30, 22 closing the loop started in node 13. Both of those have to be resolved.
The issue is that you have the Parameter optimisation Loop End (node 25) connected to the cross validation loop end. The former is not connected to anything and thus not configured. This prevents the cross validation loop end from execution. What you want to have at the end of the chain is X-Aggregator -> Scorer (or Numeric Scorer, if you would do regression) -> Parameter optimisation Loop End. Have a look at the workflow that i linked above - it shows a nice example.
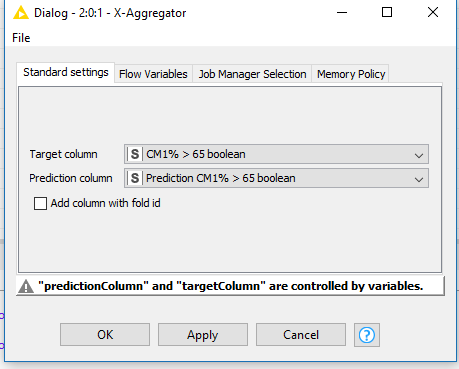
in KNIME one can use flow variables to dynamically control workflows. There is a nice introduction to usage of flow variables. If some of node settings are configured via flow variables you get the message like the one you see in the node configuration window.
Usage of flow variables is set up in the “Flow Variables” tab of a node configuration window (the second tab on your screenshot). So I read your situation like following: you have both target and prediction column names configured via flow variables in the second tab. those variables overwrite whatever you manually set up in the first configuration tab. It seems that at least one of those contains a wrong column name “0”. So if your target and prediction column names are static i suggest that you simply remove control of columns via flow variables (go to the second tab, click on the grey drop-down list and select the first (empty) entry).