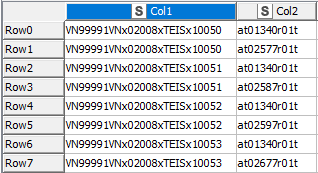
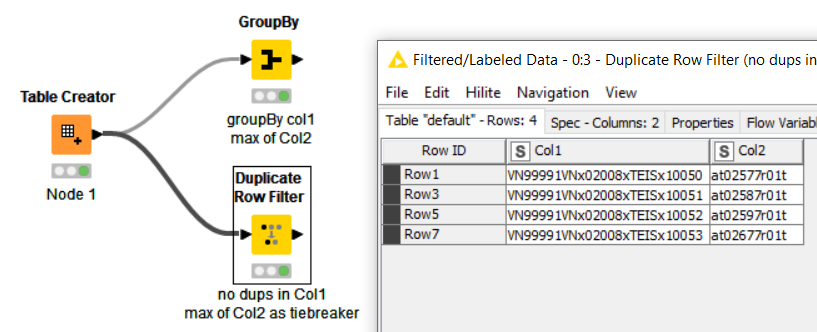
GroupBy Node using Col1 as grouping column and the maximum of Col2 as aggregation.
A Duplicate Row Filter with Col1 as duplicate column and as extra condition the maximum of Col2.
Both methods rely on string comparison to pick the “bigger” value. If you have more than 2 columns in your actual data set, the Duplicate Row Filter will be the better choice.
Thank you very much for providing sample data, it makes finding a solution a lot easier!