Not much to say. It’s about 2.5 times faster to serialize the data, pivot in pandas and serialize back. (2 mio rows) compared to using the native KNIME node. And that is with serialization taking longer than the actual pivot. So the actual pivot is probably more like 5xtimes faster.
So if you guys have time to spare, probably worth a look if there is a quick win for performance as it probably could be a lot faster.
Where index is a list of columns to group on, columns is the column that contains the new column headers and values is the column with the, well, values (both can also be lists of columns). aggfunc is aggregation function, so if there are duplicates in Name, in this case take the first one (pandas first ignores None, NaN values). reset.index() for nice rowids in knime output.
But one needs to look at the pandas API and apply accordingly to your use-case. At least I do because I’m far from a pivot expert.
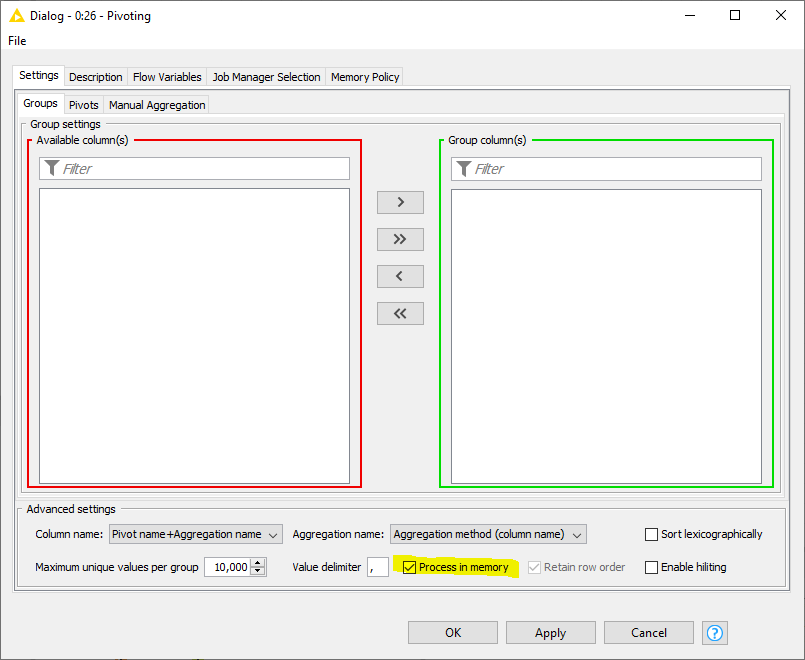
This should speedup the execution dramatically. It is disabled by default to also work with data sets that can not be processed in memory. But with your 2 mio rows and first as aggregation method this shouldn’t be a problem.
If this option is not enabled the node first sorts the input table by the group and pivot columns in order to process each group one after the other.
Bye
Tobias
Indeed I haven’t activated that feature. I now tried with it activated but the effect surprisingly is rather small (25 vs 22 sec, 10s for python including serialization). I suspect the issue is my data as in many cases (the regular case) the group will consist of only 1 row but grouping is still needed because in the less common case there are multiple rows.