Hi @evert.homan -
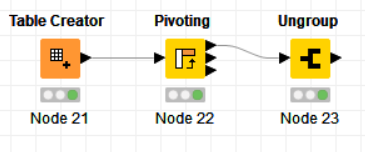
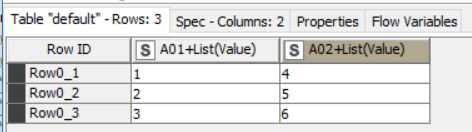
What about this? The key is aggregating on Value as a list in the Pivoting node, and then ungrouping that list. I guess you would want to do some cleanup on the column names too.
Hi @evert.homan -
What about this? The key is aggregating on Value as a list in the Pivoting node, and then ungrouping that list. I guess you would want to do some cleanup on the column names too.