Instead of work with this variablecolumn and variableprimarykey i replaced it with string.
but your solution is very good.
upload.zip (824 Bytes)
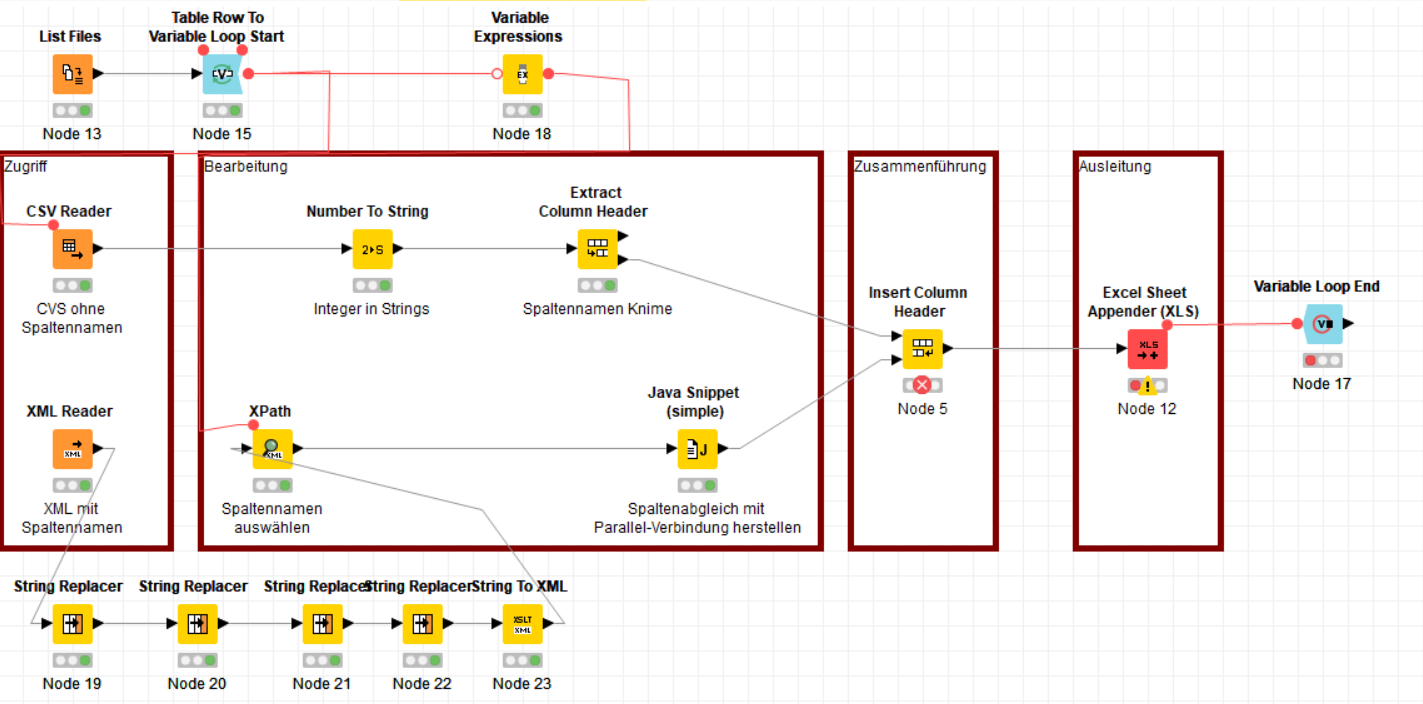
BUT both solutions have one mistake. i show you with a new xml and fileupload.
The LIstfiles are alphanumeric sorted. The XML isn’t alphanumeric sorted. Its important to match the filename in xml-xpath URL with the datanames. Otherwise you get the false column names
The change in this version is the added String Manipulation (Variable) node in which the file name is extracted one step before the XPath creation. So we can use the file name in XPathes. I used the file name to specify the true tags we are looking for.
Regarding the changing structure of the CSV files, I had to replace the File Reader node with a CSV Reader node and add a Missing Value node.
#1 If you have Filenames with blank space you get errors. For example the Filename = “GB London.csv” will be Filename =“GB%20London”. Than you can’t match the Filename with the XPath. In the XML files are the blank space filenams replaced with a “". I don’t know how good my solution is but in String Manipulation I’ll correct this line regexReplace($${SURL}$$, “(./)|(\.csv)", “”) to
replace(regexReplace($${SURL}$$, "(./)|(\.csv)”, “”),"%20","”).
And the String Manipulation next to XML-Reader i wrote "replace(replace(replace(replace($XML$,"</VariableColumn>",""),"<VariableColumn>",""),"</VariablePrimaryKey>",""),"<VariablePrimaryKey>","")".
Is there a way to write multiple commands in different rows instead of writing command in each other?
for example " replace($XML$,"<VariablePrimaryKey>","") replace($XML$,"</VariablePrimaryKey>","") replace($XML$,"<VariableColumn>","") replace($XML$,"</VariableColumn>","").
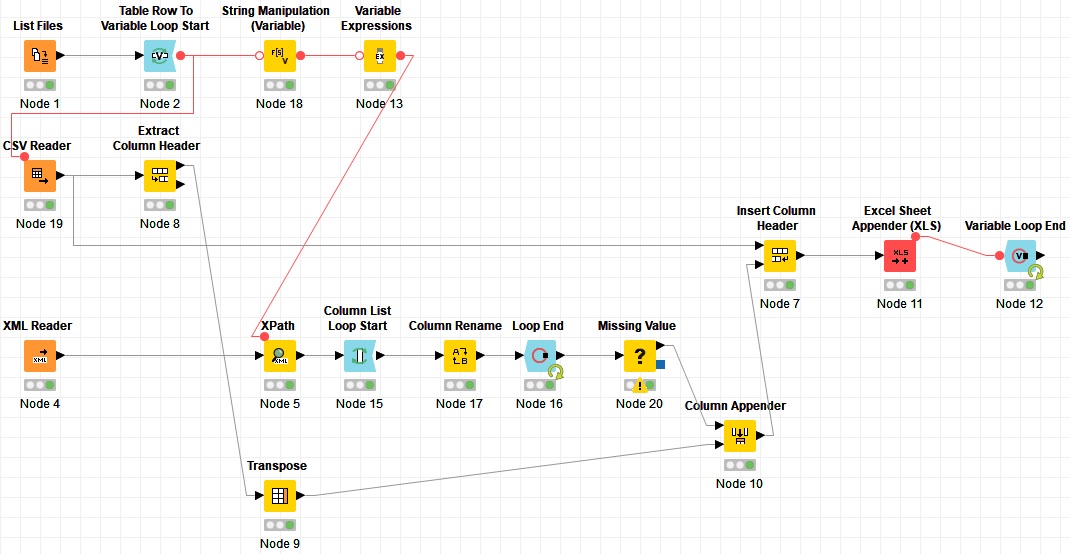
Change: Now uses the “Location” instead of “URL” to overcome the file name issue where there is a space in the file name. This change applies to String Manipulation (Variable) and CSV Reader nodes.
Yes, you can remove those tags and have all the column headers in the same level so you can skip the loop: regexReplace($XML$, "(<VariableColumn>)|(</VariableColumn>)|(<VariablePrimaryKey>)|(</VariablePrimaryKey>)", "")
You’ve Right. Next time i’ll take more time for good Examples. Sorry.
I’m new at knime. I understand the principes but its hard for me to understand the syntax from code.
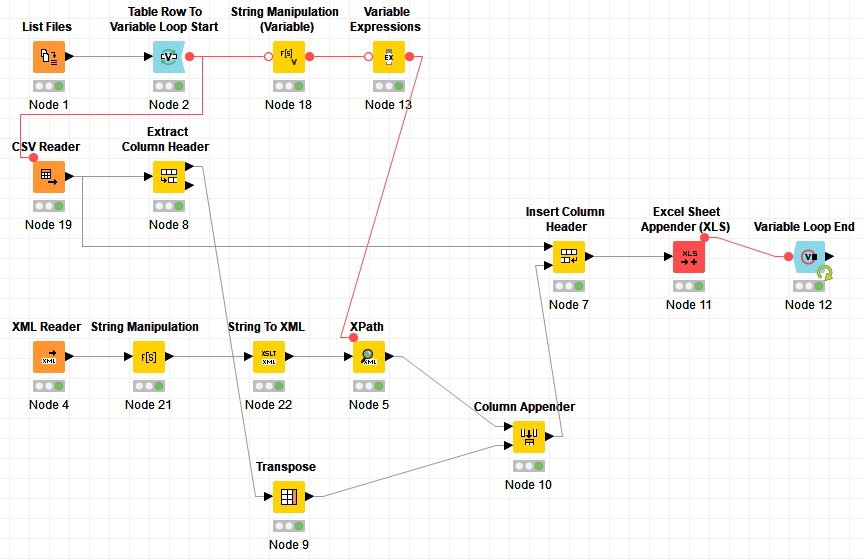
sometimes i get CSV-Files with a comma at the end of the line.
Than the reader gives me one column more as aspected.
The Match in the Insert Column Header gives than an error and the workflow is broken.
I get also sometimes a file with the same name but only in small letters.
how can i change the workflow for this problem? i’ll upload a csv for this problem.file_headers_new.zip (385 Bytes)
And also change all capital letters of the constant strings in Variable Expression (Node 13) to lowercase: join("/root/table[name/text() = \"", variable("fileName"), "\"]/variablelength/name")
That’s possible with “capitalize” function but I considered cases like “GB London” and thought it’s better to make all the characters lowercase or uppercase to prevent any problems.
The Workflow is already very good. But some specials make that workflow better.
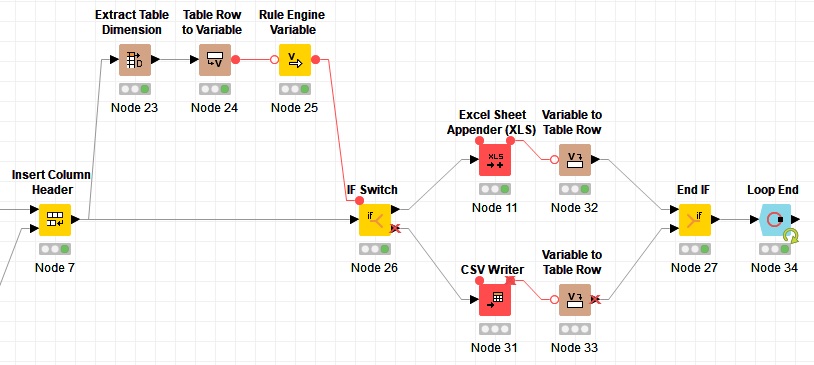
The Final file is a XLSX-Sheet. But if i Have more than 1,5 m rows than excel cannot create a file. I must take a CSV-Writer. Does Knime have a Node with a IF-Decision of Count-Rows ?
For Example:
Below 1 000 000 rows do a XLS-Write and Above 1 000 000 write in CSV ?
for workflow control there is IF Switch node and multiple Case Switch nodes. You can get number of rows in couple of ways. For example Extract Table Dimensions.
but in this case you didn’t take the if switch node; just the case switch data.
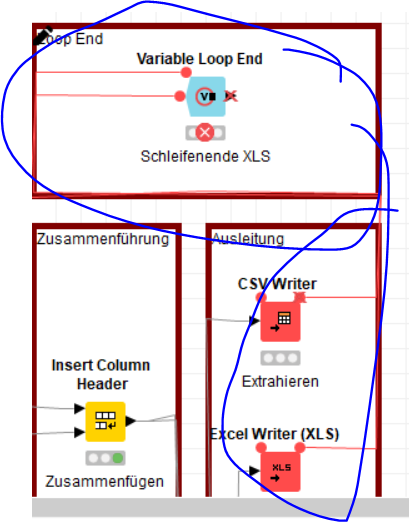
I’ve a small problem: I added your workflow to mine. But I’ve more than one file. Thats why i ’ ve a loop like that given workflow above. I geht the Error --> “Active Scope End node in inactive branch not allowed.”. And the Error is given because I’ve the Variable Loop End after the CSV Writer and Excel Writer. I’ll give you a Screenshot .