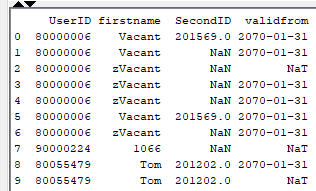
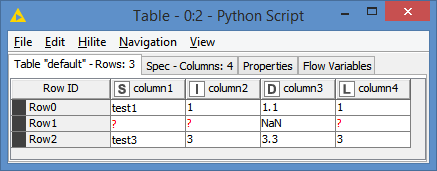
I have some data with missing values which python returns as ‘NaN’ for data type Double, and ‘NaT’ for data type DateTime - see image below of sample output:
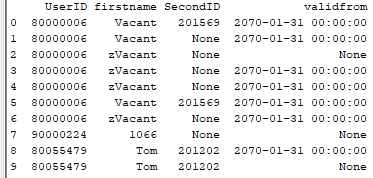
Since I want to output the data to the rest of the KNIME workflow I’ve tried to replace NaN/NaT using the following code (where my dataframe is called ‘df’):
import numpy as np
df = df.replace({np.nan: None})
Within the config section of the Python Script node this seems to work - see below:
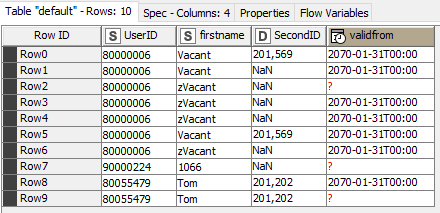
But when outputting to the next node as a table the NaNs remain on the column with data type Double.
Is this a bug, or am I using the wrong code to replace the NaNs?
I can see that this would work, but since I’m having to use python code to replace NaT’s anyway, for otherwise I get the error NaTType does not support tzname I’d rather do it all in Python as opposed to having to do half in Python and half using additional nodes.
Am I therefore doing something wrong by only using the df = df.replace({np.nan: None}) command, or is there some inconsistent behaviour in how the node reacts to ‘None’ values dependent on the data type?
I was interested so I tried it and had to modify the result with an additional KNIME node to get the missing “?”. There is no way to get the Missing “?” directly from the python output if I understood correctly?
thanks and br
Thank you everyone for your replies. @aworker linked an article which confirmed how KNIME handles NaN in Python, it’s just a shame we need to use an extra node to get the Missing “?” instead of NaN.
I’m going to refrain from marking this as solved since the problem still remains, and it gives someone the opportunity to magic up a solution that doesn’t involve additional nodes.
Hi @dpowyslybbe , I’m no expert in Python, but it seems that’s how it handles empty/null/missing for numeric columns (double, int, long). For string, it allows null and present it as missing.
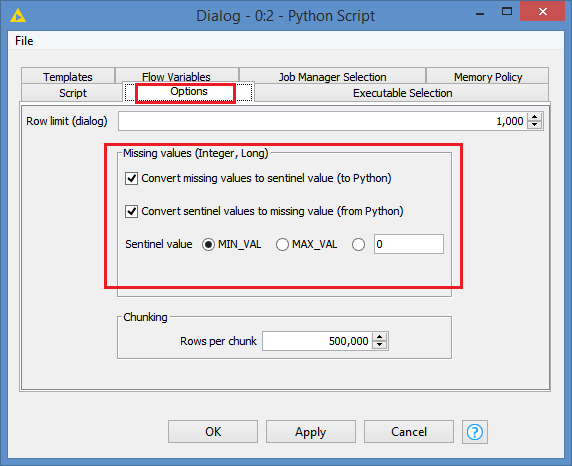
However, Knime seems to offer some option to keep the nulls as missing in the Python Script, unfortunately though, only for int and long, not for double:
I tested it, and indeed it is the case:
I don’t think it can be done within Python for Double. It will come out as NaN.
Based on the values you showed, and on the name of the column (Some sort of ID), I’m guessing that this column should NOT be of type Double? If you convert to Int or Long, you should not have any problem with these options.
@bruno29a you make some really useful points, thank you.
You correctly identify that the data type of one of the columns I shared doesn’t need to be Double, and so if an Int/Long could retain the missing values, however in the ‘real’ data I’m using I do have columns that are genuinely Doubles. Your solution would work in other scenarios, however.