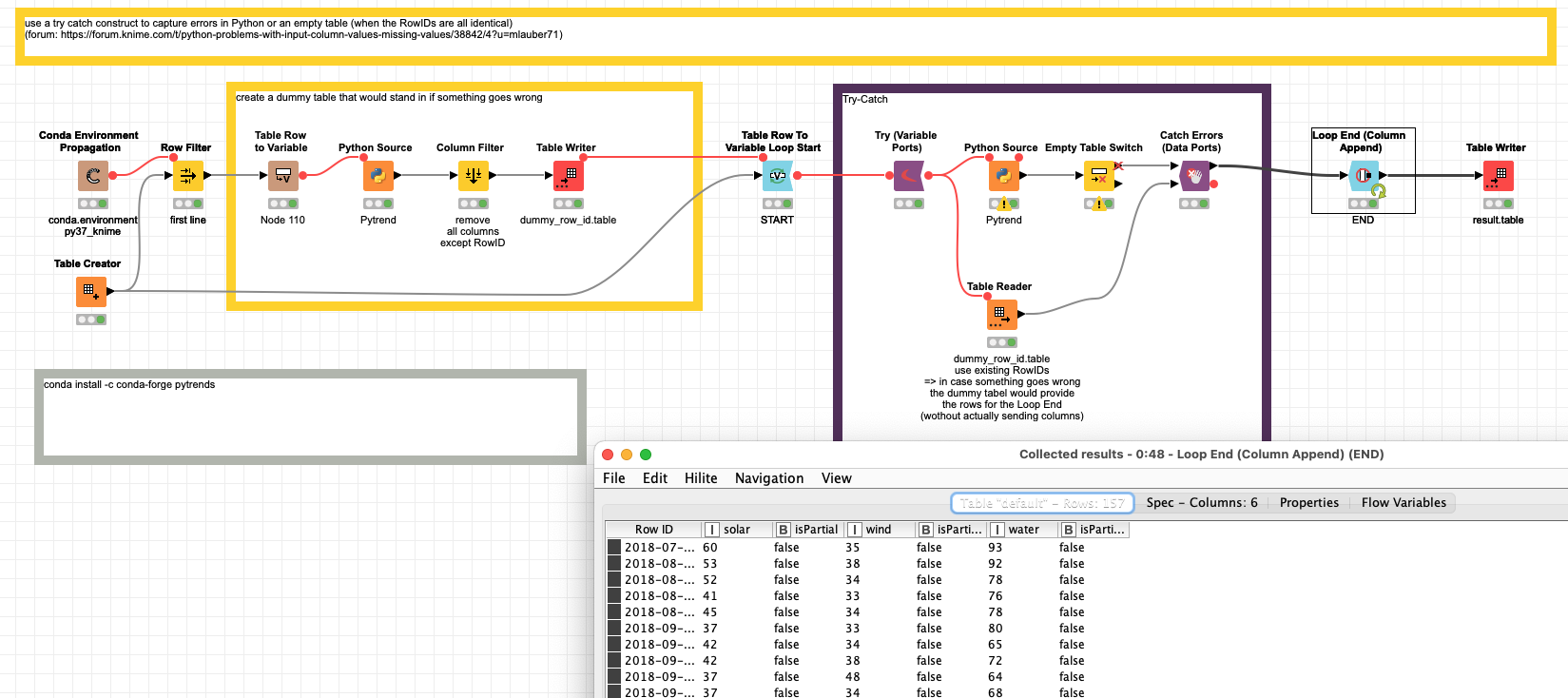
@sabsab OK it took a minute longer. Maybe there is a more elegant solution but it should work if there is always the same number of Rows with the identical RowID which I understand is the case. If not the try-catch might have to look different.
@sabsab OK it took a minute longer. Maybe there is a more elegant solution but it should work if there is always the same number of Rows with the identical RowID which I understand is the case. If not the try-catch might have to look different.