@pma99car welcome to the KNIME forum. One option I see is to use PyArrow directly for your operations instead of converting it to pandas in the first place. Another option might be to split the data and use a loop or even streaming in oder to speed it up. Sometimes also a Cache node in front of the operation might be able to help.
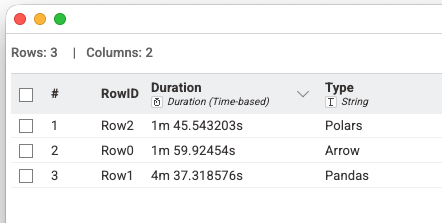
I tried the same operation with all three options and using polars beat out PyArrow. Although that would require some additional Python installations.
Also if you have large data you want to process you can take a look at this article:
Collect and Restore — or how to handle many large files and resume loops