I have created an example using the Local Big Data Environment and Hive and EXTERNAL table in order to import aCSV file into Hive and later be able to handle it. In this example there is a partition marker (my_partition) in the last column. This can later be used to split the data into parquet partitions so the system will be better able to handle them. Also you might be able to access the files separately if you absolutely must and the system is successful.
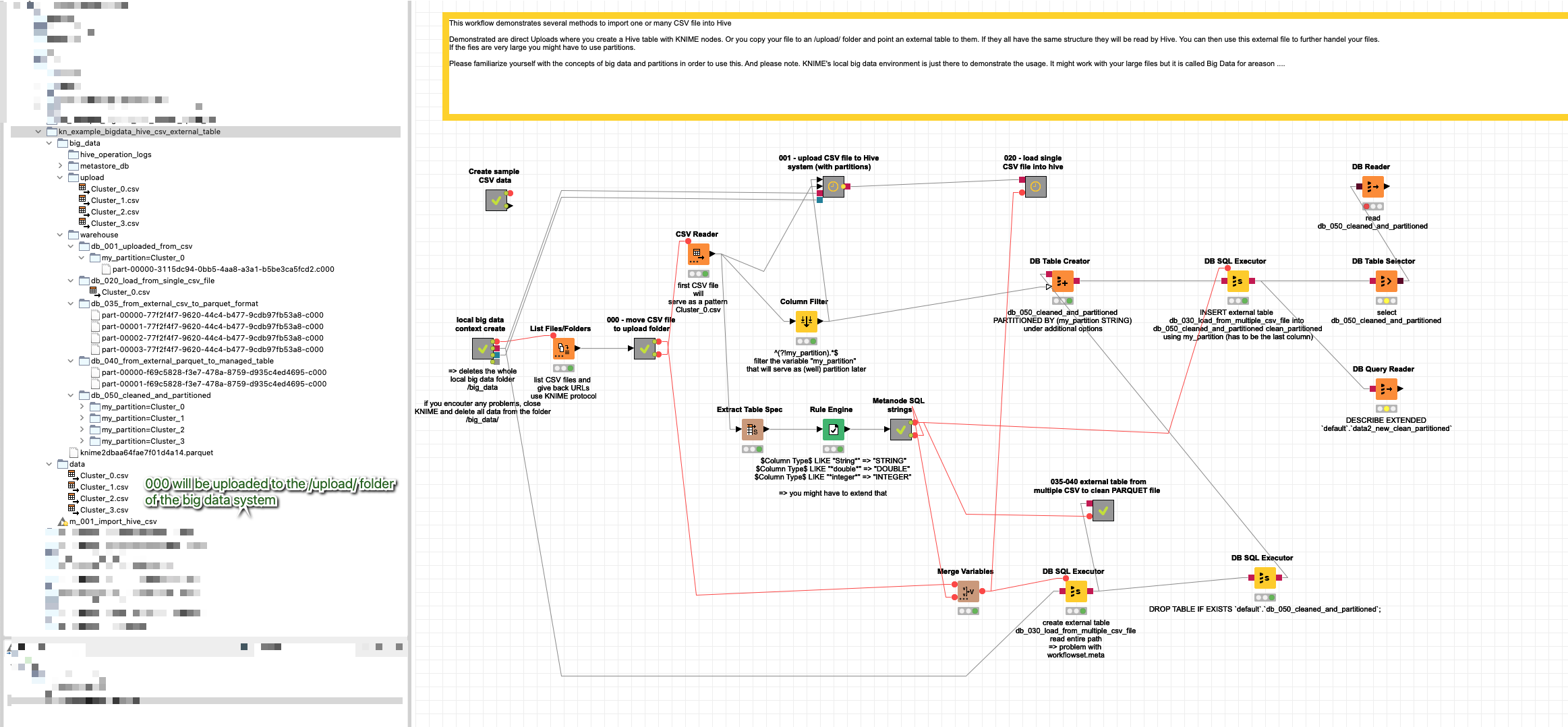
One trick is at the point where an Hive EXTERNAL TABLE is fed the structure of your data and then it can access the CSV file(s) as external information and process them within the hive/big data environment. There would be no need to import them at first. But please note: there is no free lunch here. A a certain point the data will have to be processed. One hope might be, that Hive is quite a robust system.
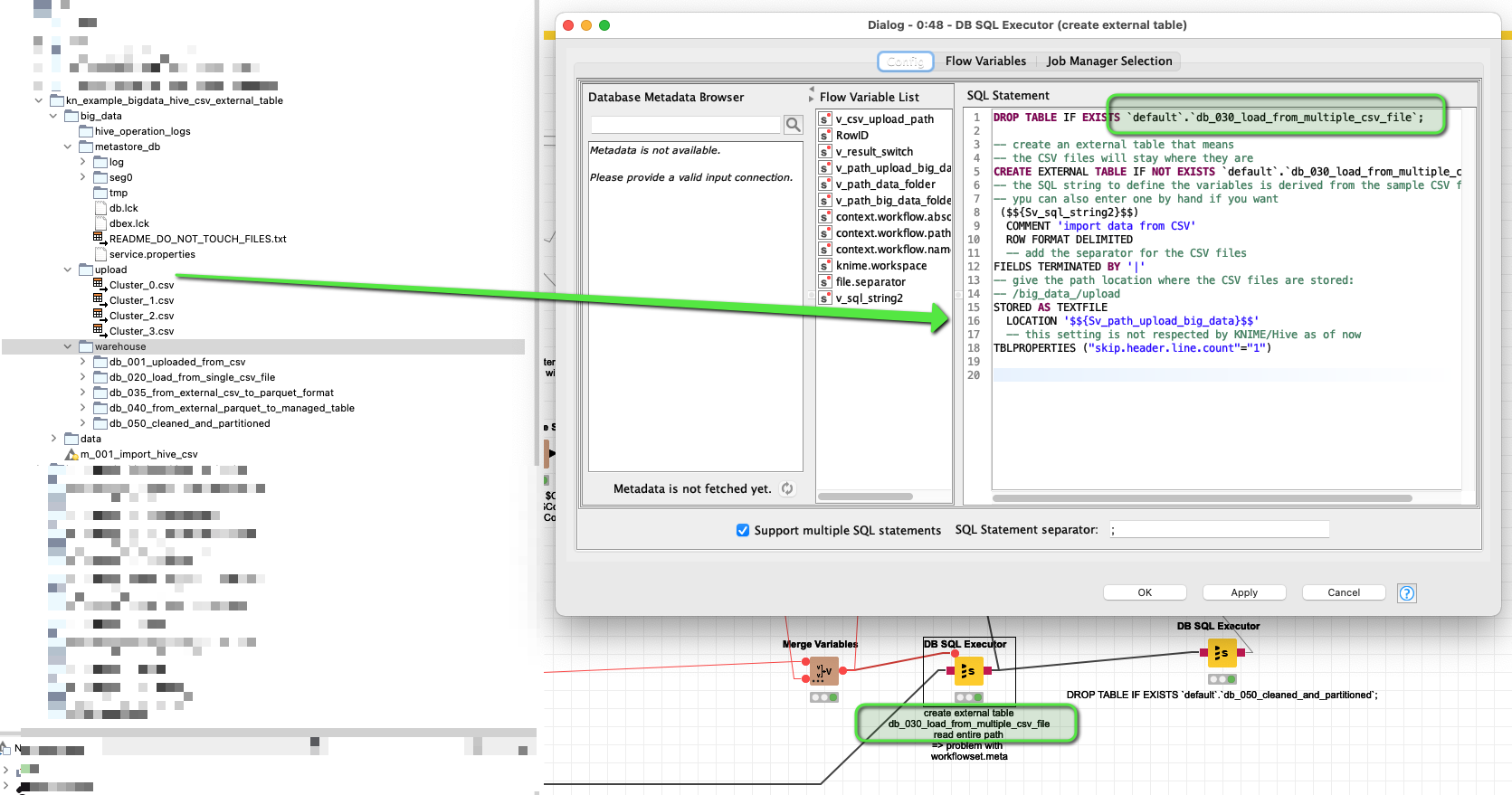
Also: the data might not be able to ‘live’ in this local environment forever. So at a certain point you might want to export the data into Parquet or ORC files (or KNIME’s own table) - or a local SQL database in order to be able to work with it further. Also this is a demonstration on my Mac. So some path nodes might have to be adapted (although it should work on windows also). And also a real big data system would be best to handle that …
You can further try and tweak your performance for example by using the new columnar storage (also based on Apache’s Parquet format).
I have to go for now. More later…