Dear all,
i hope it’s fine that i just highjack the topic. I also have a problem with a regex.
I tested the regex on several websites in order to fit it to my needs, however, once I apply it to my data in knime I don’t get the same filter results.
The regex is:
^(([a-zA-Z0-9]+(?![^\(]*\))% )([a-z]+).*)|([a-zA-Z0-9]*(?![^\(]*\))%)
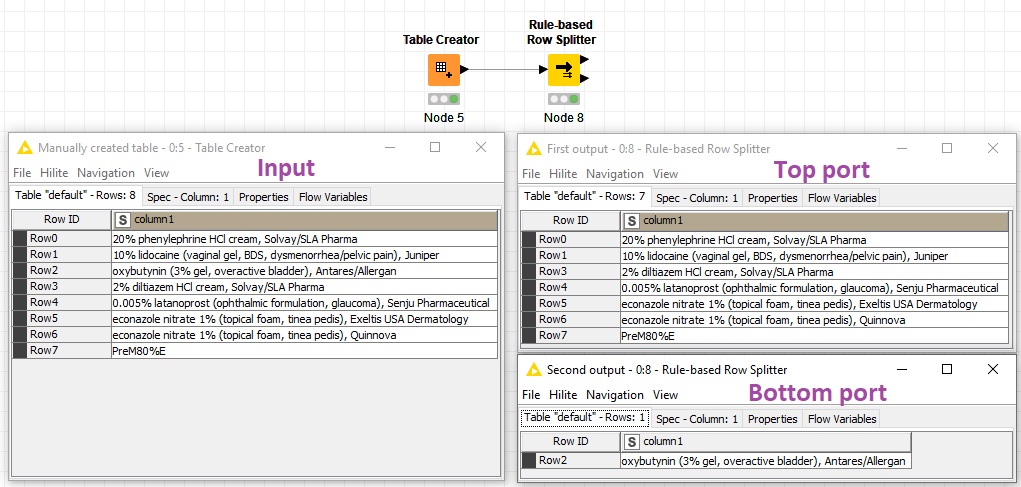
and a subset of the data:
20% phenylephrine HCl cream, Solvay/SLA Pharma
10% lidocaine (vaginal gel, BDS, dysmenorrhea/pelvic pain), Juniper
oxybutynin (3% gel, overactive bladder), Antares/Allergan
2% diltiazem HCl cream, Solvay/SLA Pharma
0.005% latanoprost (ophthalmic formulation, glaucoma), Senju Pharmaceutical
econazole nitrate 1% (topical foam, tinea pedis), Exeltis USA Dermatology
econazole nitrate 1% (topical foam, tinea pedis), Quinnova
PreM80%E
the once in bold are supposed to be hit whereas oxybutin isn’t supposed to be a hit.
I included the regex in a rule-based row spliter node using the MATCHES condition but i don’t get all the terms in the filter e.g. PreM80%E and 0.005% latanoprost are missing.
does anybody have an idea what might be the problem?
many thanks in advance
best
Andreas