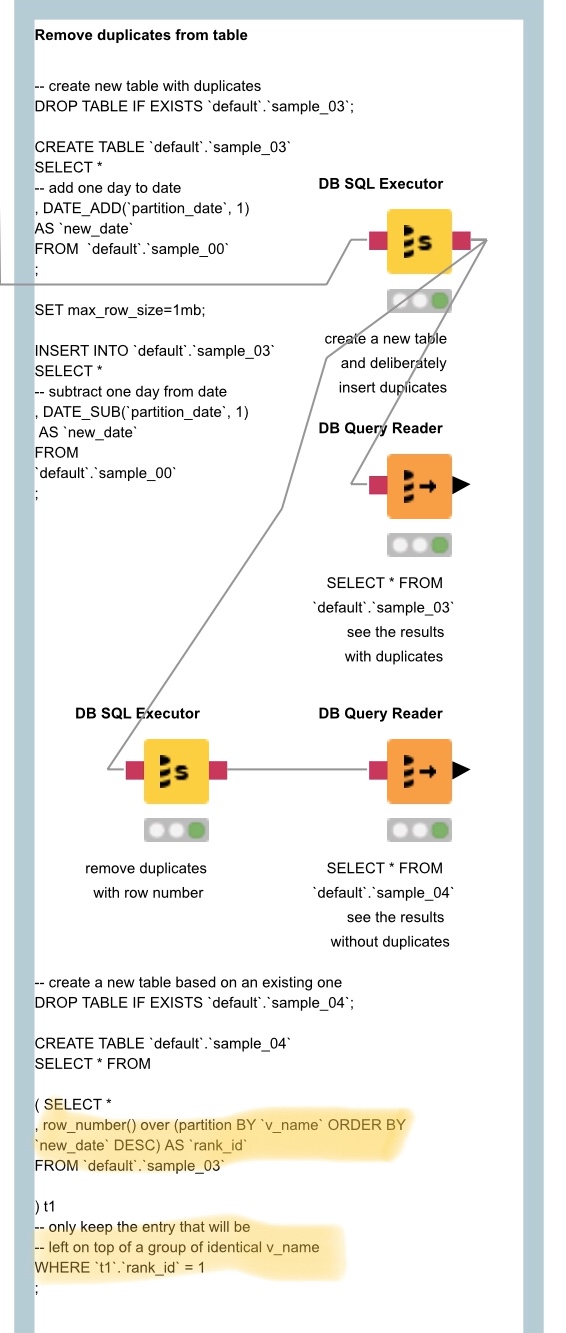
@serendipitytech I can add one more idea to remove duplicates and ensure unique IDs using SQL (Hive in this case) and row_number() if you have to deal with a data base - or you just like using SQL script.
@serendipitytech I can add one more idea to remove duplicates and ensure unique IDs using SQL (Hive in this case) and row_number() if you have to deal with a data base - or you just like using SQL script.