Hi @IlariaL , I hope I understood what you meant by “vice versa” duplicates here 

The way I understood it is ID and ID#1 interchangeable values being the same ({a,b and b,a}; {c,d and dc}), and similarly Name and Name#1 interchangeable values being the same.
So, the logic I have used is I create a sorted collection between ID and ID#1, and between Name and Name#1, that way, since they’re sorted, {b,a} will become {a,b}, and similarly, {xy,as} will become {as,xy}, and I finish off with the Dupliate Row Filter.
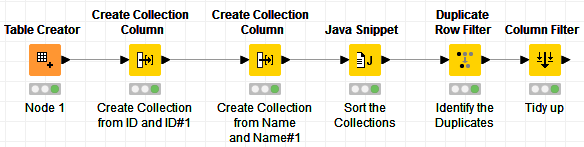
This is how my workflow looks like:
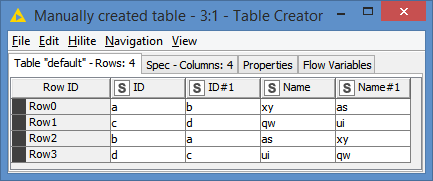
Input data:
Results:
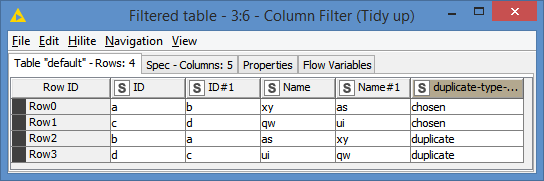
In my example, I am not removing the duplicates, as I don’t know which one you want to keep or remove, but this is just a matter of configuring the Duplicate Row Filter to whatever you want to do:

You can choose which one to remove and which one to keep.
Here’s the workflow: Remove vice versa duplicates.knwf (14.4 KB)