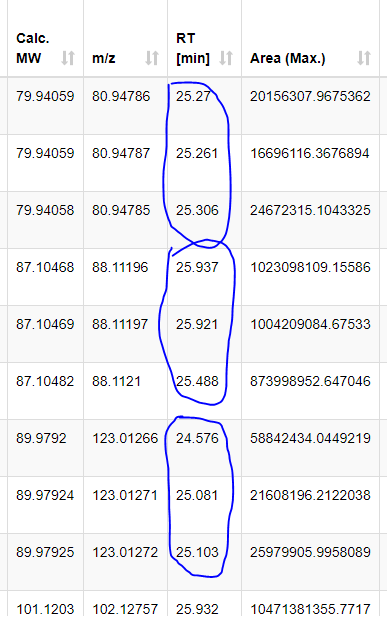
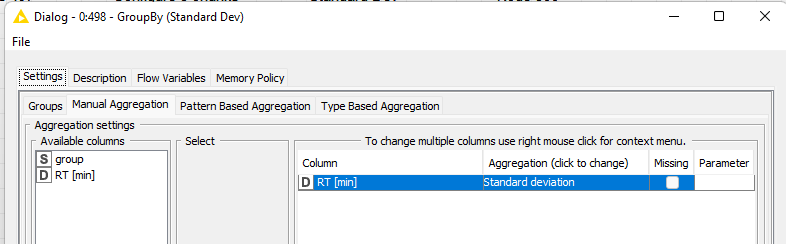
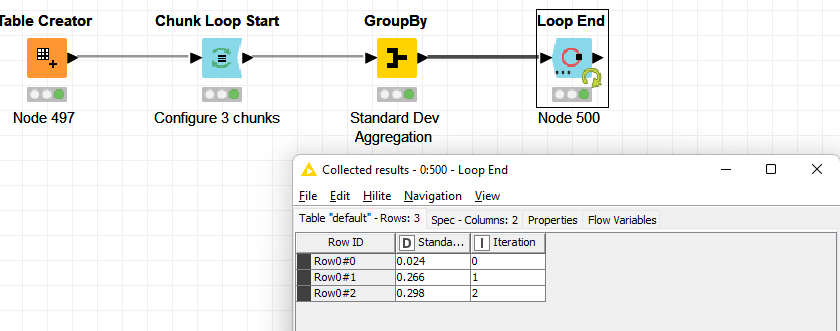
For what I understand you want to calculate the SD of those encircled rows. It should be pretty easy with the GroupBy node if you have some other column column that helps you group those three lines.
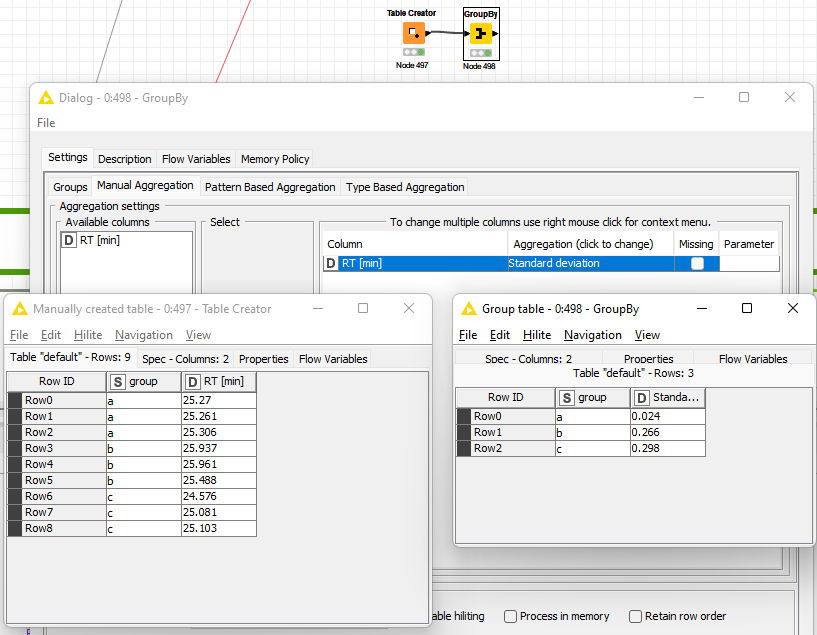
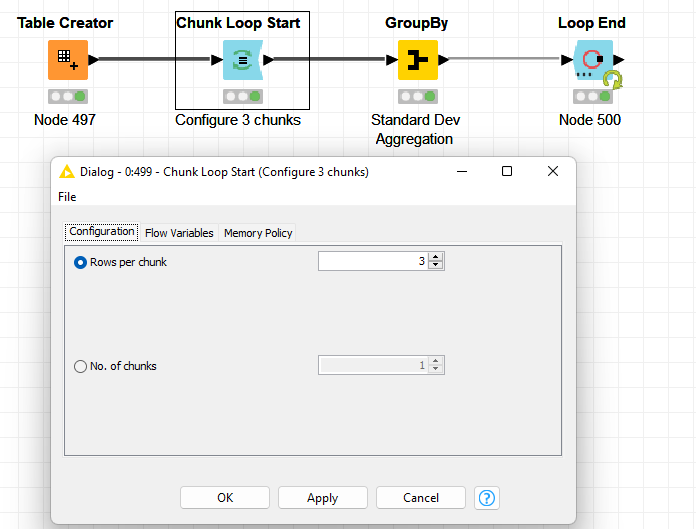
Create a loop that starts with a Chunk Loop Start node and set the “Rows per Chunk” in the Configuration window to 3. At each iteration you will have a set of 3 rows from your input table.
Hello,
I have an other question related to the same problem. Is it possible in Knime to perform this type of calculation directly?
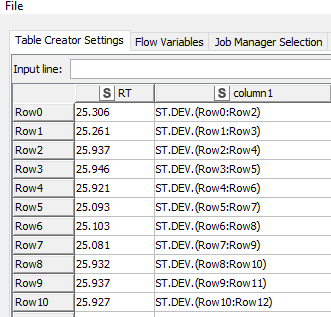
I would like to iterate the calculation as shown in the pic.
Now, I am able to iterate three rows at a time, but how I am able to do the same for 1 row and 2 rows below at a time ?
I assume that, for the rows are R0, R1, R2, R3, you want to calculate st.dev for 0,1,2 and after that for wrows 1,2,3 and so on ?
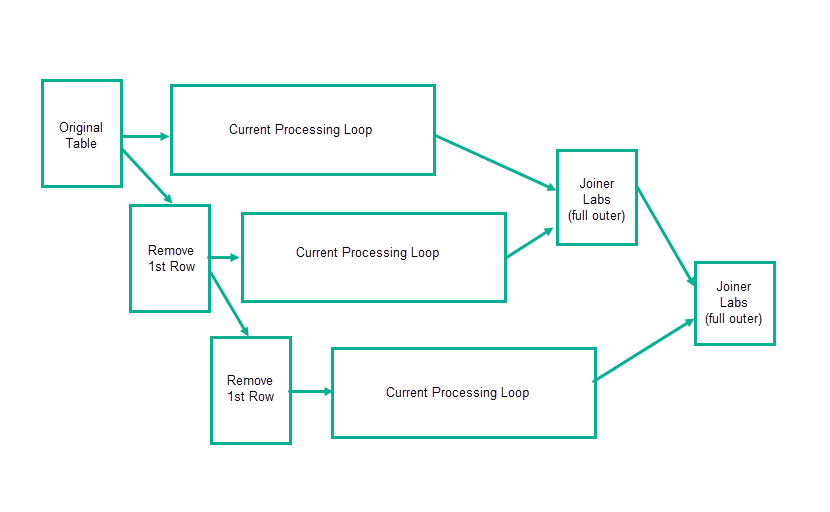
If true, than your final output is a union /join of:
what you already did - see rows 0, 3, 6, 9 in your picture - with
a similar loop that is missing the first row from the original table. This will create the st.dev for rows 1,2,3 from the original/full table, as row0 is not available anymore, and finally
another similar loop that is missing the first 2 rows from the original table. This will create the st.dev for rows 2,3,4 from your original/full table.
You join the 3 tables and get the desired result.
Check the result for the last 2 calculations as they will have st.dev calculated for 1 and 2 records that you may not what.
please let me know if my assumption is incorrect.
If my explanation is not clear enough, let me know and I’ll try to make a pic for it.
Thank you ! The assumption is correct and I think it could work in my workspace. The pic is an example, I do this after a “sort” and based on the input data the first row can be totally different every time, even in terms of rowID. Therefore, I thought that I can automate the deletion of the first or second row by creating a new “number sequence” column after “sort”. I could use a loop with “Counter Generator” to assign a sequence of numbers and then through “Row filter” delete row 0 and then row 0 and 1. And then I follow your steps
I hope I have explained. Let me know if there are easier ways
All loops are based on the same table that has the first row removed in sequence.
The current processing loop can include some cleanup of the last records if you feel that is required.