you use the Category to Number Node (and store the rules as PMML to later re-use it) to convert categories to numbers *1)
you could use the Missing Values Node (and again the apply node) to replace Messings or blanks *2)
Be aware there are several ways in which to handle categorical data for various models. You might have to consider which approach is the best. There are:
One-Hot Encoding where each string gets its own variable 0/1 (True/False)
Convert to a number that reflects the number of occurrences. The most common entry of a string variable gets th 1, next one 2 and so on
you might experiment with Label Encoding
And several more. All of these have implications towards your model and results. You might think about your use case and especially test your approach on ‘untouched’ data to see what is the effect.
Also you should read about your deep learning approach. The technique as far as I understand it is not a magic tool but has several limitations and preconditions (it might help to normalise the data *3).
Hi,
First thank you very much for the extensive reply. Missing Value is solving my problem right now!
The second problem is in my dataset there are numeric columns and also string columns. I want to replace every string with “1” and I don’t want to touch numeric values yet. After I filled them I will normalize each column. Any thoughts?
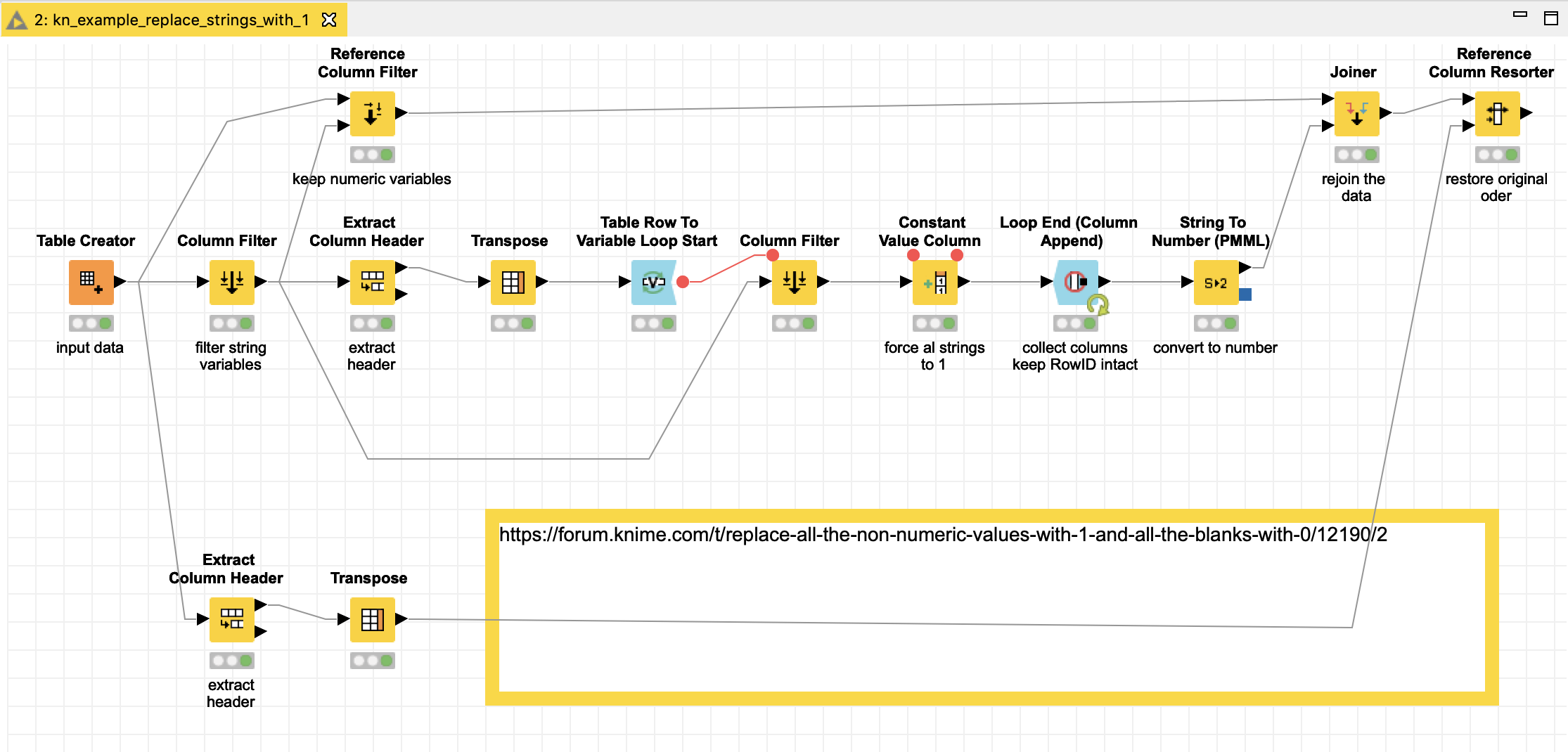
I built something to replace all Strings with a constant 1 and then convert the columns to Integer and rejoin them with the original data. Not sure if there is a more elegant way…
I would advise against using these constant numbers in any model because they would not contain any valuable information and might confuse the model. Even if this manipulation makes the model simply ‘run’ in the first place. If you want to include your string variables I would recommend to look into one of the transformation strategies I mentioned before.
About your workflow, @mlauber71
[kn_example_replace_strings_with_1.knwf ]
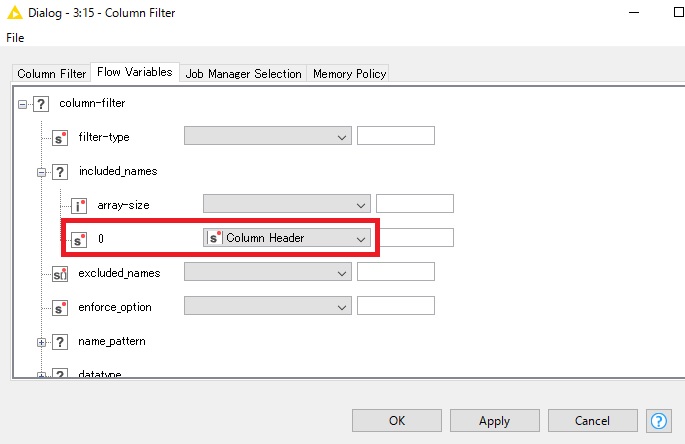
I’m interested to the Column Filter setting in the table row to variable loop.
How to set a “0” parameter of included_names in Flow Variables?
When I create a Column Filter node I just can’t see this “0” parameter shown here, and don’t know how to add this.
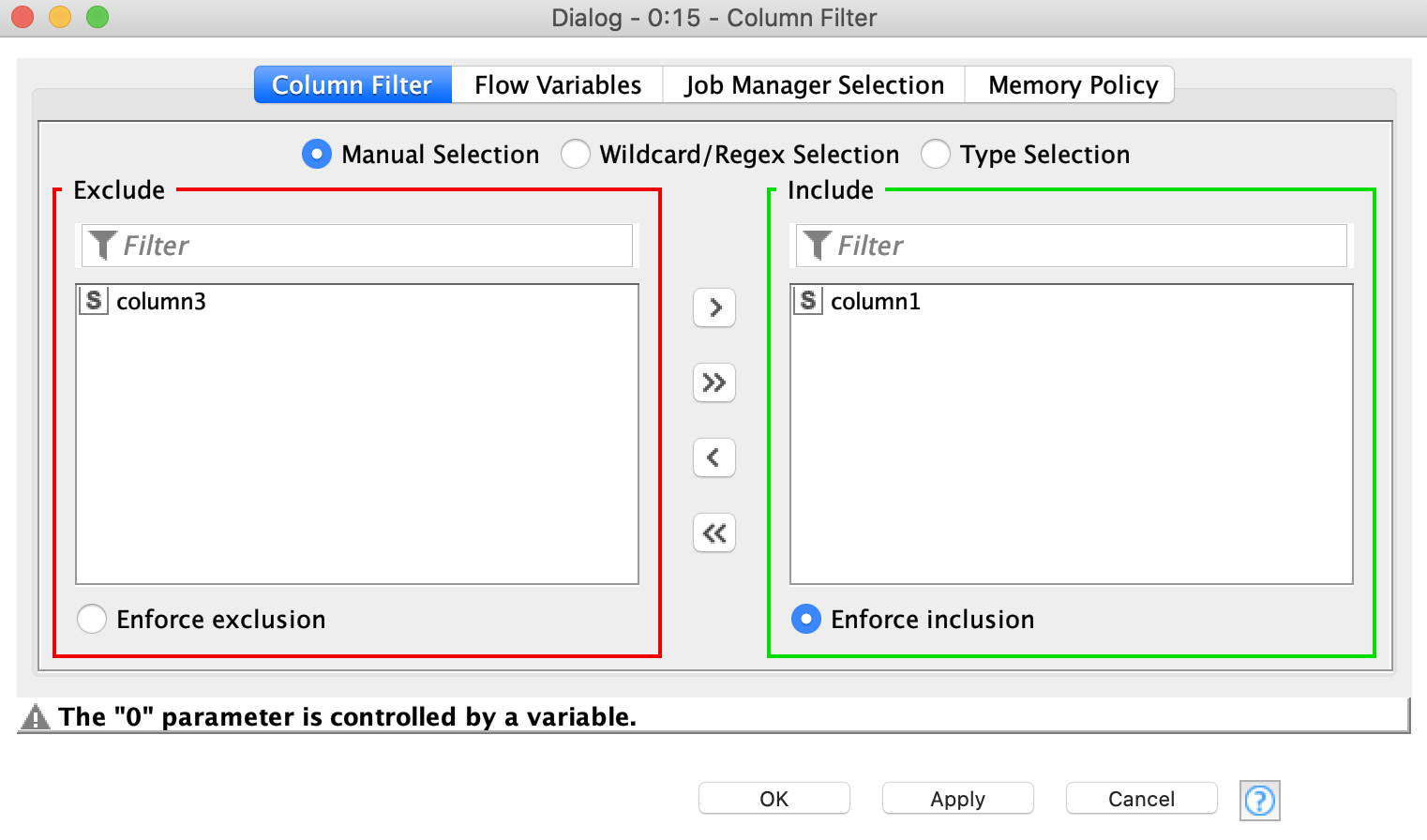
@qianyi the ‘secret’ is in providing a dummy column (“column1” in this case) that would then be controlled by a flow variable. You can specify as much flow variables as you have defined columns.
Thanks for your reply. @mlauber71
I have already added the column1, but sitll cann’t find the “0” parameter in flow variables - [include_names].
Is there any thing have to be set up particularly?
I was interested about the “secret setting” because it seemed convenient, hoped it would be a useful way though I do think other way like a reference column filter could work in this case.
Regarding flow variables in Column Filter node. From KNIME version 4.1 new flow variables types have been introduced. Specifically this means you can control number of column in Column Filter (and nodes alike) dynamically and flow variable of type array (collection/list) is required. You can check this workflow to see how it is done in GroupBy node.
@qianyi can you explain a bit more what are you trying to accomplish?
Hi @ipazin
Thanks for your attention.
I don’t have an actual task right now, but I was not sure what’s the best way to tackle a dynamic column filter in a Column List loop. I would need to to this kind of staff someday. Before I do some practice, I find this post and information from mlauber71 here which contains a good answer for me. I will look over the your information then.