Hi @nba , my component parses the HTML code manually and goes and fetch the exact content based on the HTML code.
I’ve put something similar for retrieving URLs/ Links and Titles from https://www.zerohedge.com/
It will not blindly look for <a href="">, it will look for clearly identified links. For example, it will not retrieve ads links.
Here’s what my workflow retrieved:
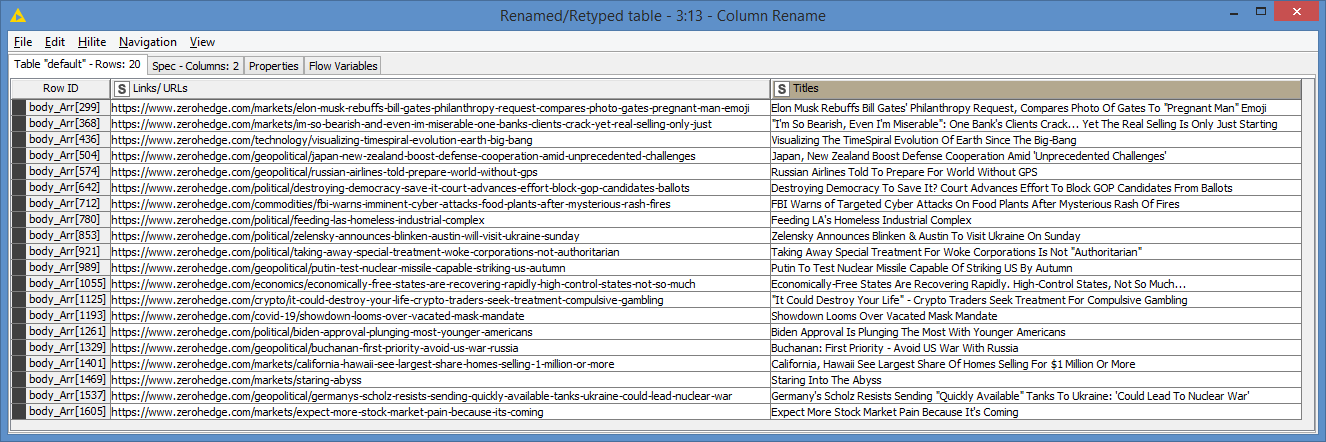
Just as with my Component for Google works only for Google (because it looks for specific HTML code from Google, more precisely for specific CSS classes), the same goes for my workflow for Zerohedge. Each site has its own HTML structure and code or class names.
If I don’t look for these specific code, it will retrieve all <a href="">, which includes links from the navigational menu, or shortcut to other websites, etc. For example, the https://www.zerohedge.com/ has 117 <a href=""> links on its page, but only 20 of them are relevant to what you are looking for.
Unless you are reading from RSS feeds, you won’t have any standard solution reading directly from different websites.
Here’s my workflow: Retrieve URLs and Titles from Zerohedge.knwf (26.8 KB)
EDIT: I am sure you can apply the same logic using XPath. This is an alternative if you are not familiar with XPath, as it is reading the content of the website as text, and then parsing the HTML text. It will most probably not be as direct either in XPath. You most probably would have to go in multiple levels, and possible multiple paths.