i am doing a task in knime tool where task: i need to check the rows like row 1 == row 2 in a single column(cash) then if it same it need to check the next column(Currency) two rows where row 1 == row 2 if it same then need to check for another column(Amount) where row 1 == row 2
Hi @Abhiram , and welcome to the Knime Community.
Please check the Lag Column node where it allows you to “shift” the row values into a new column:
Here’s a very simple example:
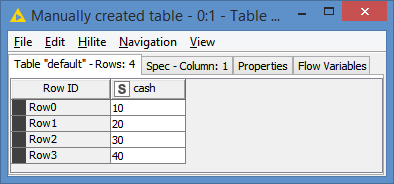
Initial data:
Lag:
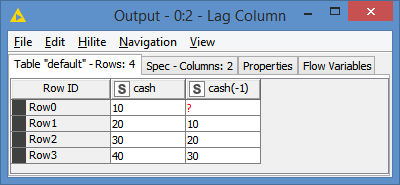
You can now compare the 2 columns, which is essentially comparing 2 rows of the original column.
2 Likes
Thanks, but i need to compare the two rows example

consider country as one column and currency as 2nd column then in cash has 2 rows
row 1 = AUS and currency has row 1 = AUD
row 2 = AUS row 2 = AUD now code need to check tat row 1 == row 2 if both same next code moves to next column currency where row 1 == row 2 like that comparision
consider that above image where knime need to check entity column irows i.e row 1 == row 2 if it same then it need to go currency column rows i.e row 1 == row 2
Hello @Abhiram
Then you would need to make some grouping before the approach suggested by @bruno29a , and concatenate your data afterwards.
If your data has only two currency types, you can do it in parallel with a Splitter (rule based or other), and collect back at the end with a Concatenate node.
If you have many ‘currency’ data categories, you may want to select a Group Loop approach (by currency column), in this case the data will be collected in the Loop End itself.
BR
2 Likes
Hi @Abhiram,
For something like this, I think it would be useful to understand what it is that you are actually trying to do once you have performed the comparison. I’m guessing that comparing one column and then a second column is not the end game for your use case, and that you wish to do something once both conditions have been met, or maybe something different if the first column matches and the second column doesn’t.
Unlike traditional coding, where you would follow a sequence of steps such as test condition A, then test condition B and so on, typically with a tool like KNIME, the approach taken can be very much dependant on what end result you are aiming for.
If for example, you simply want to find all rows where your two columns match, and maybe mark or join them in some way, then you could concatenate the two columns first and then use a lag column, as has already been suggested in replies from @gonhaddock and @bruno29a.
If however you wish to take a certain action if only one column matches, but a different action of the second column also matches, then it might be that a different approach is more suitable.
Could you maybe elaborate on what it is that you are actually wanting to achieve once you’ve found matching columns?
3 Likes

Hi @Abhiram,
I think that maybe if we restate your problem, then maybe somebody can help you more quickly. Unfortunately I have little time this afternoon, and am just looking at this in my break.
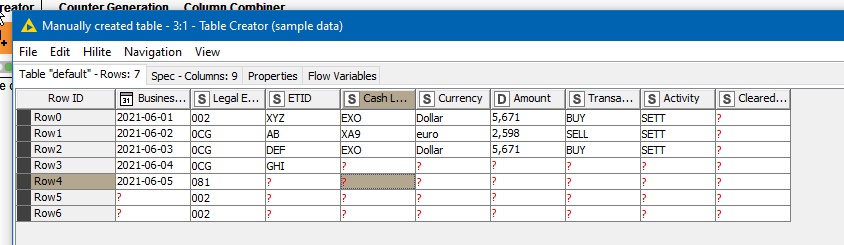
So… you are reading a spreadsheet into KNIME and it contains the following columns:
Business Date
Legal Entity
ETID
Cash location
Currency
Amount
Transaction Sub Type
Activity
Cleared?(Yes/No)
On each row where all of the following columns match the values in the next row:
Cash Location
Currency
Amount
You want to set the Cleared?(Yes/No) column to “YES”
Is that it?
Is it always comparing each row with the row immediately after it, or are you actually looking for matches of those three columns between each row and all other rows?
I’ve made an assumption based on your screenshot, that it isn’t always just sequential rows that you would be comparing
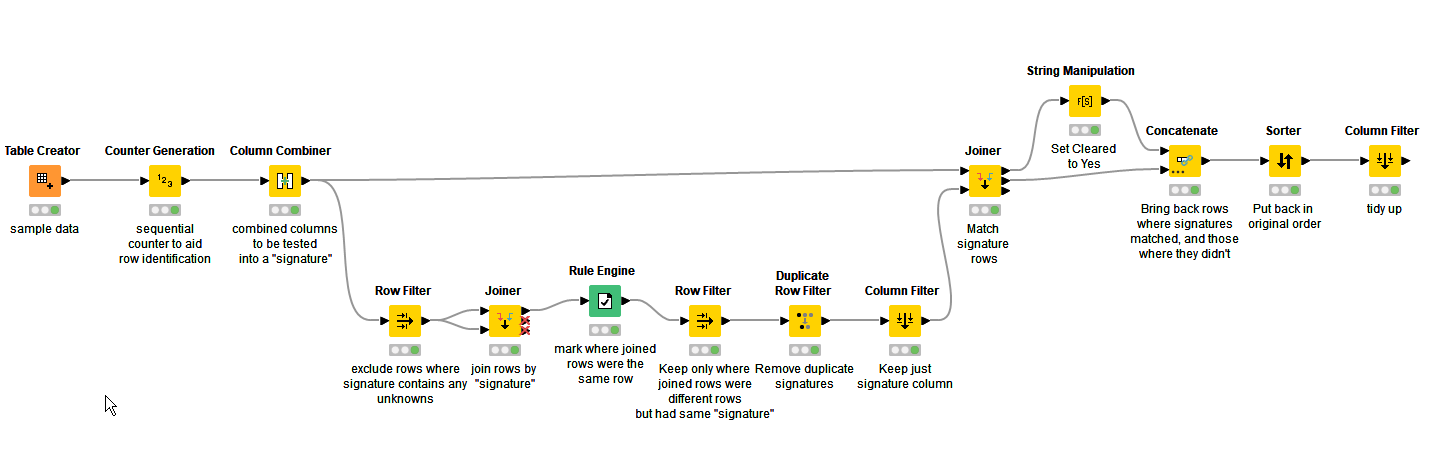
I’ve attached a workflow that does this comparison across ALL rows, which you might find useful. If you really only want to compare adjacent rows, then the comparison logic can be replaced using a Lag Column node, as previously suggested.
I’ve done this in a bit of a rush so more importantly, somebody else may be able to extend this in a different direction, or improve on it if it isn’t exactly what you want. I’ve tried to write in the node descriptions what their purpose is. As it stands, it is quite convoluted and there may be some shortcuts that can be found
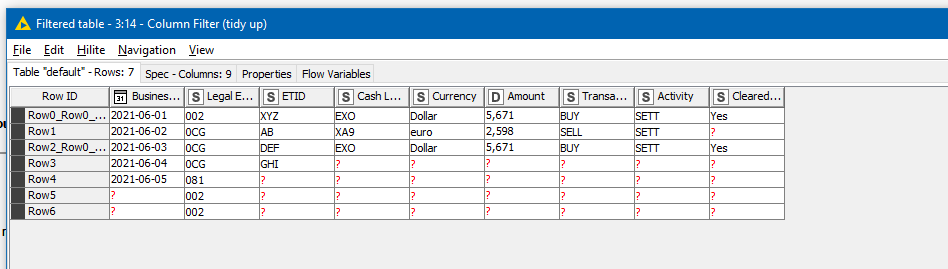
Set value on row comparison.knwf (35.5 KB)
3 Likes
Hi @takbb,
Thanks a lot for the workflow,
yes it is always comparing each row with the row immediately after it.
like see my task was consider the data having 100 rows then total approx six columns and next comparision will be if row 1 == row 2 with all columns if it matches then Cleared column will be Yes.
if not then comparision will be row 1 == row 3 then again the same process it need to do. if it matches then row 1 and row 3 values must be YES in column Cleared, then next the process need to start from row 2 == row 3 if it matches then row 2 == row 3 must be yess. next the process need to start from row4 == row5 like that it need to go
please @takbb @bruno29a @gonhaddock help me guys very urgent but @takbb the process you sent i am checking that
Hi @Abhiram,
I think in your last post you meant that row2 would be compared with row3, rather than row1 with row3.
I’m also not quite sure what is supposed to happen in the edge case where row1, row2 AND row3 all match.
Attached is a workflow that demonstrates using the lag column node. As with the previous flow, it creates a “signature” column to be used to ease comparison of multiple columns, by combining all of the columns of interest for use in the comparison. It then lags this column forward, and backward (by temporarily reversing the order of the rows to achieve this). This means that on each row there are then two additional columns containing the “signature” from the rows either side.
A rule engine then looks to see if the “signature” from the rows either side of the current row match the current row, and if they do it sets the “Cleared?” column to “Yes”. If not, it leaves the “Cleared?” column as it was.
I’ve modified the sample data to enable testing.
Set value on row comparison - adjacent rows.knwf (20.1 KB)

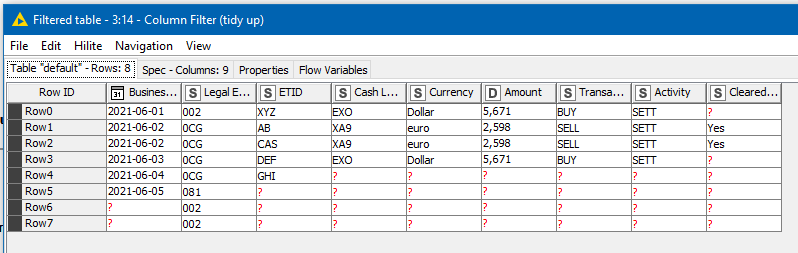
I hope that helps move things in the right direction, but feel free to ask further questions if you need more assistance.
A quick aside. People here on the forum are more than willing to assist with problems and help provide solutions, but whilst I’m sure that for you your task is urgent, please keep in mind that most people on the forum are here when and if they have time, and they may well have their own jobs to do and things that are equally urgent to them. Thanks. 
4 Likes
Hi @takbb ,
Actually i had a dead line of the project was feb 4th and also i am new to knime this is the first task.
i tried your solution it didn’t worked that column combining
conditions**:1)Same ETID, Currency, Cash Location, Amount, **
---------------->Activity :SETT and REIN
---------------->Transaction Sub type is same for all activity(BUY/SELL)
**2)Same ETID, Currency, Cash Location, Amount, **
---------------->Activity :SETT and SETT with Is ContraFlag = Y
---------------->Transaction Sub type is same for all activity(BUY/SELL)
**3)1)Same ETID, Currency, Cash Location, Amount, **
---------------->Activity :PART and REIN
---------------->Transaction Sub type is same for all activity(BUY/SELL)
**4)1)Same ETID, Currency, Amount, **
---------------->Activity :ACTV and CXLD
---------------->Transaction Sub type is same for all activity(BUY/SELL)
the above are the conditions
Based on the above conditions i need to check the row comparioson and output was the column: Cleared(Yes/No)? if my data set passes with any of the condition then it will be YES
if not output remains SAME(NO)
Hello @Abhiram,
I think that @takbb 's workflow is a really smart solution for your challenge. A simple modification can work for the missed “No” labels.
You can try adding them by editing the Rule Engine rules in row 8:
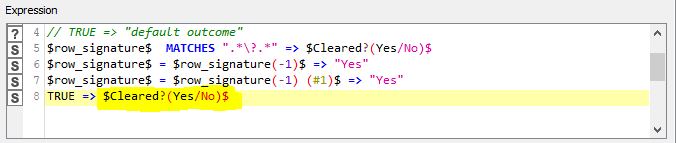
Try to replace the row with the following Rule
TRUE => "No"
BR
1 Like
Hi @gonhaddock thanks,
but in my task there are certain conditions are there i already given those conditions on my previous post
i need to use all those conditions (6)
The workflow provided shows how to compare by rows including some conditions. I think now, is time for you to work out the conditions and the sequence to apply them.
In the shared workflow you can select the columns to compare … have a look and try to set up the ones needed on every step. You may need to apply some type of sorting before.
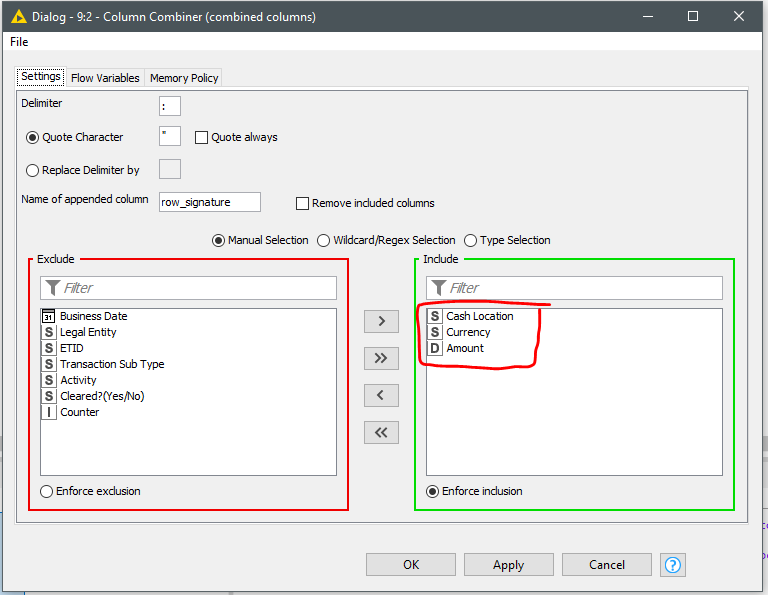
Image: Current selected columns in the shared workflow
BR
1 Like
Hi @Abhiram, I attempted to clarify your conditions for you to confirm. In my post above I stated what I believed you were asking, based on the “Main condition” in your screenshot, and that only mentions setting to “Yes”. In the absence of any other information, the safest option is to leave Cleared as it was.
[edit: my bad, I now realise I missed “Transaction subtype” from my conditions (column G in your main conditions), and therefore in the workflow]
I’m not surprised that this workflow doesn’t meet all your requirements, as it is to provide a general idea to assist you in solving your problem rather than a complete solution. Some of the conditions that you say it doesn’t resolve had not been previously stated, and you also didn’t previously mention the Is ContraFlag column…
I’m also now questioning what conditions apply to the “Activity” column? Are you saying for example that on one row it would be “SETT” and on the other it would be “REIN” for it to be a matching condition? If that’s the case, I think you need to explicitly state that this is what you mean. I’m still not sure, and you didn’t previously mention it as far as I can tell.
You are now saying there are 6 different conditions, but in your last post you appear to show 4. Maybe I’m not understanding how you are expressing these conditions.
I think it would help people to help you if you clearly state ALL of the conditions, and do not assume that people know your problem-domain, or your data. It would also be better if you were to upload a spreadsheet containing some sample data (it needs to be representative of your data set, with examples matching all of your conditions, but should not contain sensitive data, so change some values etc if necessary). Otherwise you are asking quite a lot of people on the forum to give up their free time to create your test data.
My thanks to @gonhaddock for providing additional input and ideas, and as is mentioned, you do need to try to take these ideas and adapt them to your needs. This may, for example involve repeating the same same sequence of nodes several times to handle each of your different conditions. Maybe? That might not scale with a huge number of conditions but it might work in your case. I haven’t tried it, but it would be one possible idea to explore.
Further to @gonhaddock’s earlier note re the Rule Engine, if you wish to put the “No” in the cleared column, then as mentioned the last line should be modified, but the first line of the rule also needs to have the outcome set to “No”, as this is the line identifying that some data in one of the “key” columns is missing.
$row_signature$ MATCHES ".*\?.*" => "No"
Also, if you wish to include tests in a Rule Wizard for specific literal values too (e.g. testing your “Activity” column), you could code it as something like this:
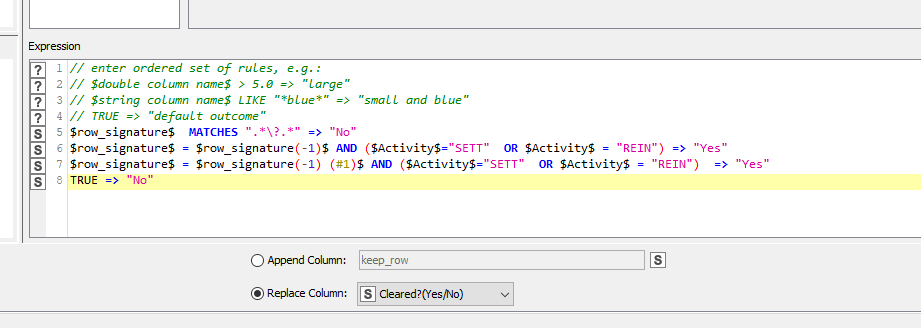
$row_signature$ MATCHES ".*\?.*" => "No"
$row_signature$ = $row_signature(-1)$ AND ($Activity$="SETT" OR $Activity$ = "REIN") => "Yes"
$row_signature$ = $row_signature(-1) (#1)$ AND ($Activity$="SETT" OR $Activity$ = "REIN") => "Yes"
TRUE => "No"
Hope that helps.
3 Likes
Hi Takbb,
Thanks for your help.
Apologies for not mentioned the full details on my previous posts. I tried the way u given the workflow and i used my ideas but i didn’t meet the solution. and also i cannot able to send the origial spread sheet, apologies for that too. that’s why i send some sample spread sheet where both looks same.
you had asked me regarding the Activity column? example in that activity column consists 100 rows where some rows might be PART or SETT or REIN or ACTV or CXLD i mean it may continusly from 1 to 20 rows value was SETT or 1 row it might be SETT and other it might be REIN.
See you had given me the intermediate solution like your idea thanks for that.
by using those conditions the output need to be come like
examples:
for the above specified conditions
condition1:
1)etid – column 2)currency – column 3)CASH LOC 4)AMOUNT 5)Activity 6)Transaction SUBTYpe
rows:
a)kjsdfhdskjfh a)AUD a)AUS a)230 a)SETT or a)REIN a)BUY or a)SELL
b)kjsdfhdskjfh b)AUD b)AUS b)230 b)REIN b)SETT b)BUY b)SELL
if the date of the above two rows then it might be condition 1 was exists the output:
Cleared(Yes/No)
a)Yes the (2 rows)
b)Yes
condition 2:
1)etid – column 2)currency – column 3)CASH LOC 4)AMOUNT 5)Activity 6)Transaction SUBTYpe
7)IS contra flag:
rows:
a)kjsdfhdskjfh a)AUD a)AUS a)230 a)SETT a)BUY or a)SELL a)Y
b)kjsdfhdskjfh b)AUD b)AUS b)230 b)SETT b)BUY b)SELL b)Y
if the data was like the above then it might be satisfies for the condition 2 met then output column:
CLeared?
a)Yes
b)Yes
Condition 3:
1)etid – column 2)currency – column 3)CASH LOC 4)AMOUNT 5)Activity 6)Transaction SUBTYpe
rows:
a)kjsdfhdskjfh a)AUD a)AUS a)230 a)PART or a)REIN a)BUY or a)SELL
b)kjsdfhdskjfh b)AUD b)AUS b)230 b)REIN b)PART b)BUY b)SELL
if the data was same as above it satisfies the 3 rd condition
then output column (Cleared):
a)Yes
b)Yes
condition 4:
1)etid – column 2)currency – column 3)CASH LOC 4)AMOUNT 5)Activity 6)Transaction SUBTYpe
rows:
a)kjsdfhdskjfh a)AUD a)Jap a)230 a)ACTV or a)CXLD a)BUY or a)SELL
b)kjsdfhdskjfh b)AUD b)AUS b)230 b)CXLD b)ACTV b)BUY b)SELL
where for the 4th condition cashlocation was not equal like cashlocation_A ! = cashlocation_B
if it like that the data so it satisfies the 4th condition then output was:
a)Yes
b)YES
Hi @Abhiram,
Part of the problem here is the way you have written the conditions has not made this easy to follow, and you also haven’t made it easy by saying there are six conditions but still only listing four of them. My thanks though to @Bruno29a who pointed out that you had posted the same question here, where you have actually listed in a different format what I assume to be the six conditions. Please don’t open two threads on the forum asking the same question, as this leads to confusion and a waste of time for people.
May I make a suggestion, that it would be clearer if you lay out conditions like this in a table format, rather than as a series of sentences. That way it makes it easier to see similarities (and differences!) between the conditions.
As an example, here is a table containing what I believe your conditions to be:
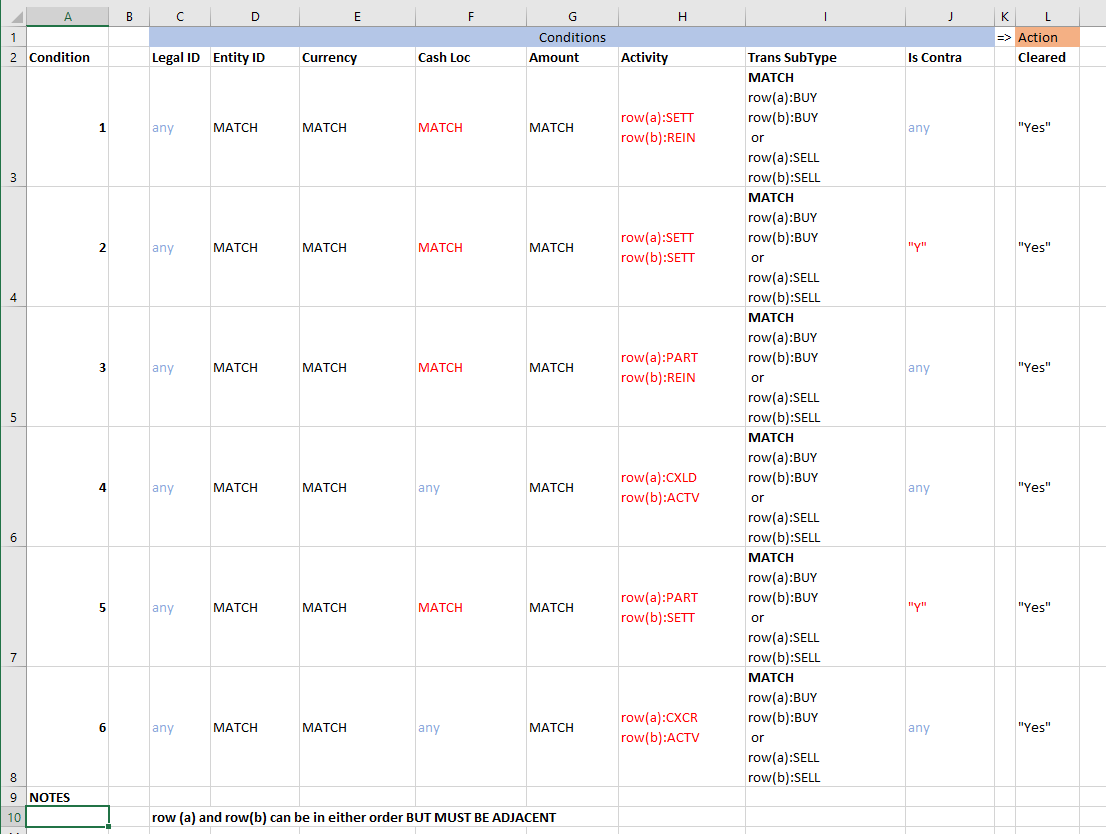
The items in Red or the parts of the conditions that are not common. From jthis, we can see that there are certain rules that must apply to ALL rows for them to be considered “cleared” and other specific rules that we will need to handle.
Based on these rules (and I know I may still have misinterpreted!), I have changed the approach to doing the workflow. You need to effectively lag multiple columns both forward and backward, and this could be achieved as with the previous flow using a series of Lag Column nodes, but instead I have decided to lag multiple columns by a series of three “Counter Generation” nodes, with start points of 0 (current row), -1 (previous row) and 1 (next row). These provide the “row numbers” that can then be joined to current row using two Joiner nodes. By keeping only the “columns of interest”, we have then effectively lagged multiple columns.
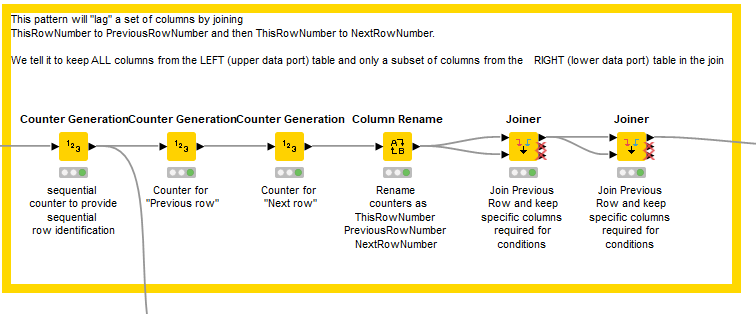
After this, a Rule based row filter can handle ALL of the rules that are common to ALL of your conditions (those in black in the table), and a Rule Engine can mop up the specific cases (those in red).
Out of that Rule Engine will pop the “Cleared” value for the rows of interest, which we can then join back to the full data set using the “row counter” that we created near the beginning. After some tidy up work to remove the now-superfluous columns we created, you get the result you are looking for (I hope).
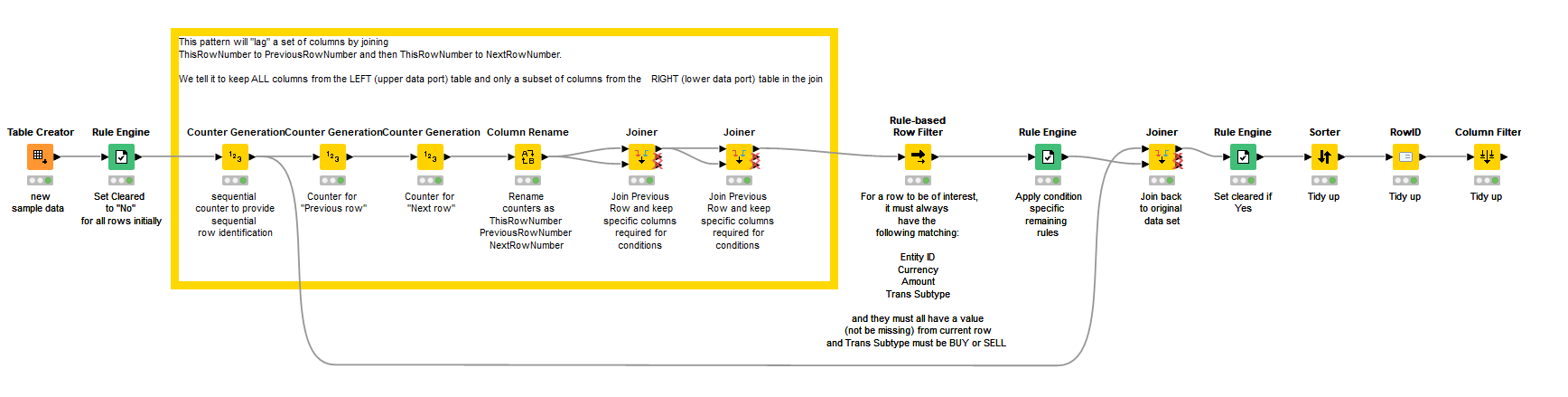
This will of course need testing. I haven’t tested it except in my one sample case. Testing is very important as I may have introduced errors in my typing of the rules, or may have forgotten something!. I spotted one error which I corrected just prior to posting this, and this was just in the case of my very small sample data, so there could be well be other mistakes.
Now I realise that you cannot provide your sample data because it may be sensitive, but with questions such as this, where you have a number of conditions, you really do need to be willing to provide sample test data, because otherwise what you are saying to people here on the forum is that you have a question, but you don’t have the time to provide sample data (in the form of a file upload, not just a screen image that we’d need to then type-up for ourselves), but that you think that the people helping you DO have the time to do it for you! That doesn’t really come across well.
Anyway, I hope that the attached is of assistance. I probably have very little further time today. If there are errors in it, then hopefully you will be able to work out what needs changing. By all means ask questions about it or how it works. There may well be shortcuts to some of what I’ve done, and there will certainly be alternative (and possibly better) ways too. Others may wish to comment on it, and assist you too should you still have problems. I hope you have a good day! 
Set value on lagged row multi-column-conditions with adjacent rows.knwf (40.6 KB)
[Edit: I’ve re-uploaded workflow with correction to joiners to keep matching AND unmatched left-joins, otherwise we lose first and last rows!]
3 Likes
Hi @takbb
Apologies for the mistakes i had done,
it’s working for one case , i am trying to do the rest cases need to be worked.
—> actually from conditions part alone some slight error was there, while i testing and also i observed
based on that Activities only getting error
error means every time only one case only it is choosing
thank u so much for the help.
i am also working on those conditions part
The approach was super thanks for that.
your help means a Lot to me.
but that conditions where we are using rule engine there only need to develop some more because it passing only one condition