Hi @Abhiram , that came as a bit more of a challenge! 
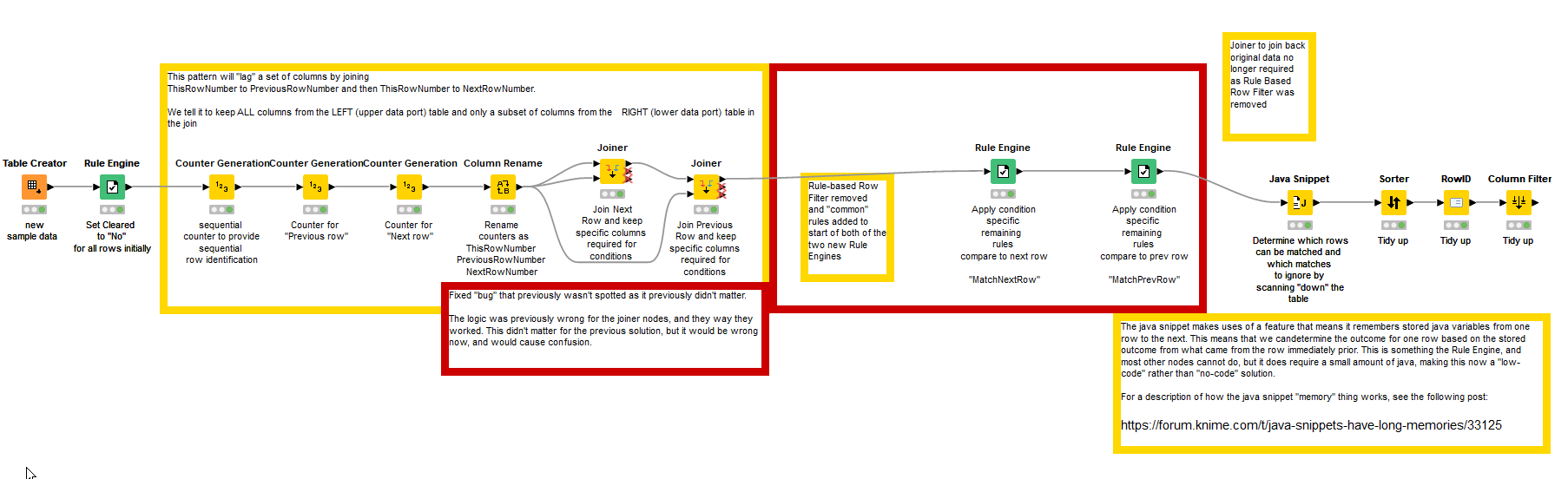
This had me scratching my head and I couldn’t see any easy way of doing this using the standard (non-scripting) nodes.
What I came up with was that having determined whether there was a match to previous or next row, a subsequent processor would have to go down the list of matches and decide which were now allowed, and which weren’t. To perform this process, I had to use a java snippet. There is a feature of the java snippet that allows us to retain some “state” between rows, so we can base actions on what we did during the processing of the row immediately prior to the current row. For further info and examples on that specific feature see the following post
But for that to work, I had to now have two Rule Engines, one for deciding if there was a match to previous row, and the other separately deciding if there was a match to next row. It also meant that the Rule Based Row Filter had to be removed, as the Java Snippet needed to work on the whole data set, and not just on the subset of rows if it were to work properly.
So the Rule Based Row Filter had to be removed, and the rules from there added (with slight modification) to each of the two new Rule Engines.
The upside was that a re-joining of the data set was no longer required.
I discovered a bug that made no difference previously, in the two joiners used for “lagging” the rows. The join columns were round the wrong way so the “previous” row columns were wrongly named (next) and the “next” row columns were being named (previous). This didn’t matter before, but it was wrong and would be very confusing with the two rule engines and the new java snippet referring to “next” and “previous”…
So unfortunately that small additional feature caused quite a dramatic change to the workflow design. It has to be said that row-comparisons isn’t KNIMES strongest point, and I would argue that it is quite common to want to compare rows, especially prior and next rows. It would be nice to have some kind of multi-row Rule Engine, some way of supporting such use cases.
Anyway, here is a new version of the workflow. It would be nice if it were to just “slot in” in place of the previous one, but I suspect you’ll either have to edit it, or else use a column renamer node to rename your input columns to match this workflow, and then rename them back again at the other end…
Set value on lagged row multi-column-conditions with adjacent rows (b).knwf (42.9 KB)
As before, this needs testing again if you are going to make use of it for real work! Hope that helps.