First of all, I must mention that I am a beginner in KNIME and now have been
working to find text processing solutions. However, I have come up with
another issue today. I was trying to build two tag clouds for positive and
negative review each. Using row splitter, I had split the reviews and based
on TF the clouds were supposed to be drawn. However, One tag cloud for either
only positive or only negative can be drawn perfectly. When attempted to draw
a tag cloud based on the filtered out terms: It shows both Negative and
Positive terms. Instead, of a tag cloud with the filtered out terms from the
excluded sentiment from row filter. Please suggest.
Hi,
Is it possible for you to provide your workflow with a sample data?

Hi Armingrudd,
Thank you for your interest in this work. I am sending you the workflow and the data set for this analysis. I was trying to perform SENTIMENTAL ANALYSIS on travel reviews. The aim was to find terms associated with POSITIVE & NEGATIVE sentiments respectively and also to draw TAG CLOUDS for each SENTIMENT. The issue arrived when it was found that although under SENTIMENT column the sentiments are easily segregated as NEGATIVE & POSITIVE. But while looking under TERM column, it can be seen that many terms has both NEGATIVE & POSITIVE sentiment associated with them. This creates problem in finding the terms which are NEGATIVE and to draw tag clouds of only NEGATIVE terms.
I hope to learn more from you.
Regards
DeepKNIME discussion.knwf (1.2 MB)
MayfairCasino.xlsx (37.6 KB)
Hi @deepjg -
I think I found the problem. In your Dictionary Tagger nodes, you should check the option for Exact Match. This will avoid the problem where certain words (for example, “average” and “charm”) were assigned both positive and negative sentiments simultaneously.
Also, just for aesthetic reasons, you might try using the newer Tag Cloud (JavaScript) nodes. They produce a prettier word cloud, and have the benefit of being combined with other JavaScript visualizations interactively if you choose.
2 Likes
In addition to @ScottF’s suggestion, I have a different suggestion.
The exact match will reduce the tagged terms to half (234 unique terms won’t be tagged) in this case so if you prefer to stay with the previous config and in the same time you need to avoid double tags, then I suggest to remove the terms with both positive and negative tags since there are a few of them (43 unique tagged terms will be removed).
Here is the modified workflow in which I did what I have suggested:
KNIME discussion.knwf (2.4 MB)

1 Like
I think he would probably want exact match in this case. Otherwise you end up with words that get tagged, even when those words aren’t in the positive and negative corpus files he’s reading in. For example, I can’t think of a reason why “casino”, “Friday”, and “entry” should be tagged as negative words, but without the exact match option enabled, they are.
2 Likes

Just another question from my side to learn from you @ScottF.
Does it make sense to filter out those general terms first and then use the Dictionary Tagger without the exact match?
Thanks a ton for your valuable suggestion and time. It indeed has solved my problem. Thank you once again.
Regards
Deep
2 Likes
Hi ScottF,
Your solution has actually helped me to filter out many unnecessary words. I am very thankful to you for your valuable suggestions. It indeed has reduced a lot of positive words from the cloud of negative words. But, I could still find two positive terms in the negative cloud. I am sending you the image of the cloud with this reply. Please find the same.
Regards,
Deep
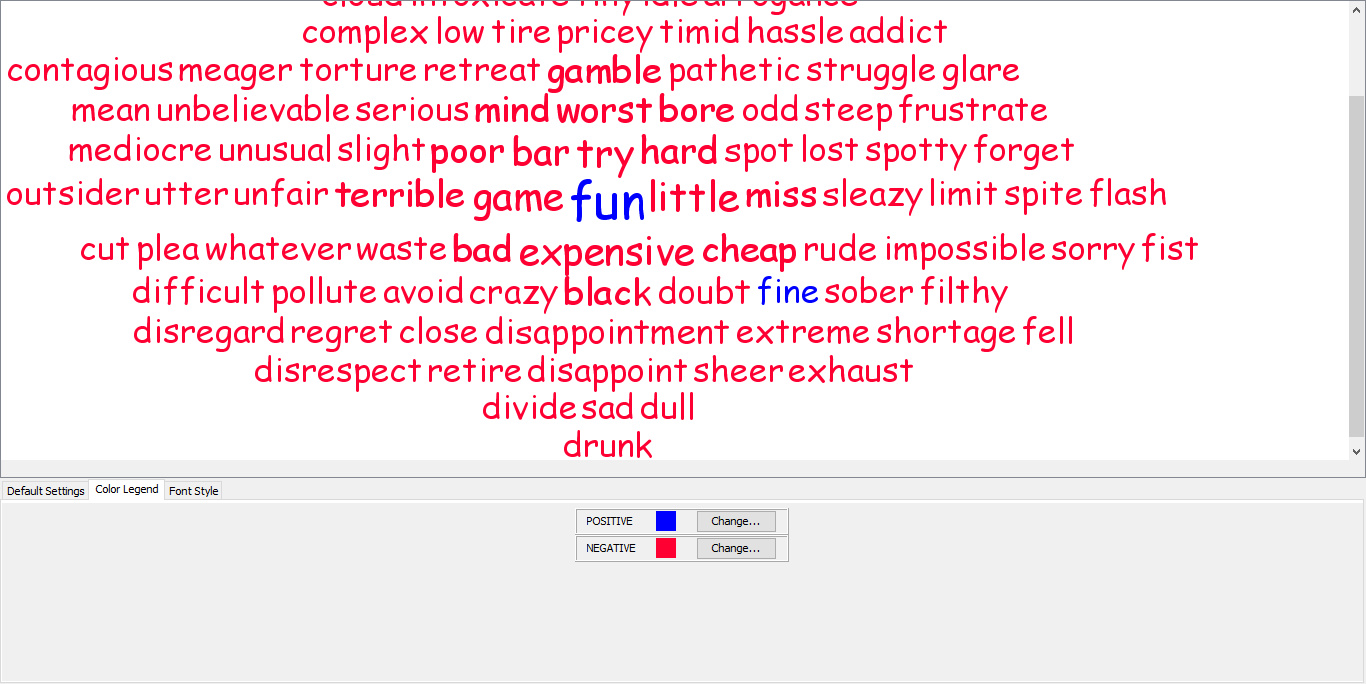
Hi @deepjg -
This is because - for whatever reason - the terms “fine” and “fun” show up in both the positive and negative dictionaries. As a result, they get double-tagged. I think I would manually remove those from the negative dictionary in your case.
I was curious to see how many words show up in both dictionaries, so I just did a quick join. It turns out there aren’t very many such words, but you found two of them:
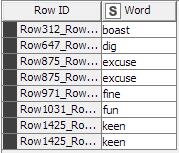
Anyway, I hope that explains things.
1 Like
@armingrudd It’s a good question!
I think I would stick with exact match here, since leaving in terms identified without the exact match seems to produce some consistently strange tagging results.
Honestly, I need to understand better how the tagging node works without exact matching enabled. I thought at first it might be picking up substrings of words (which would definitely be bad in this case) but now I’m not so sure. I should ask some of our text mining experts what the intention is here.
2 Likes
This topic was automatically closed 7 days after the last reply. New replies are no longer allowed.