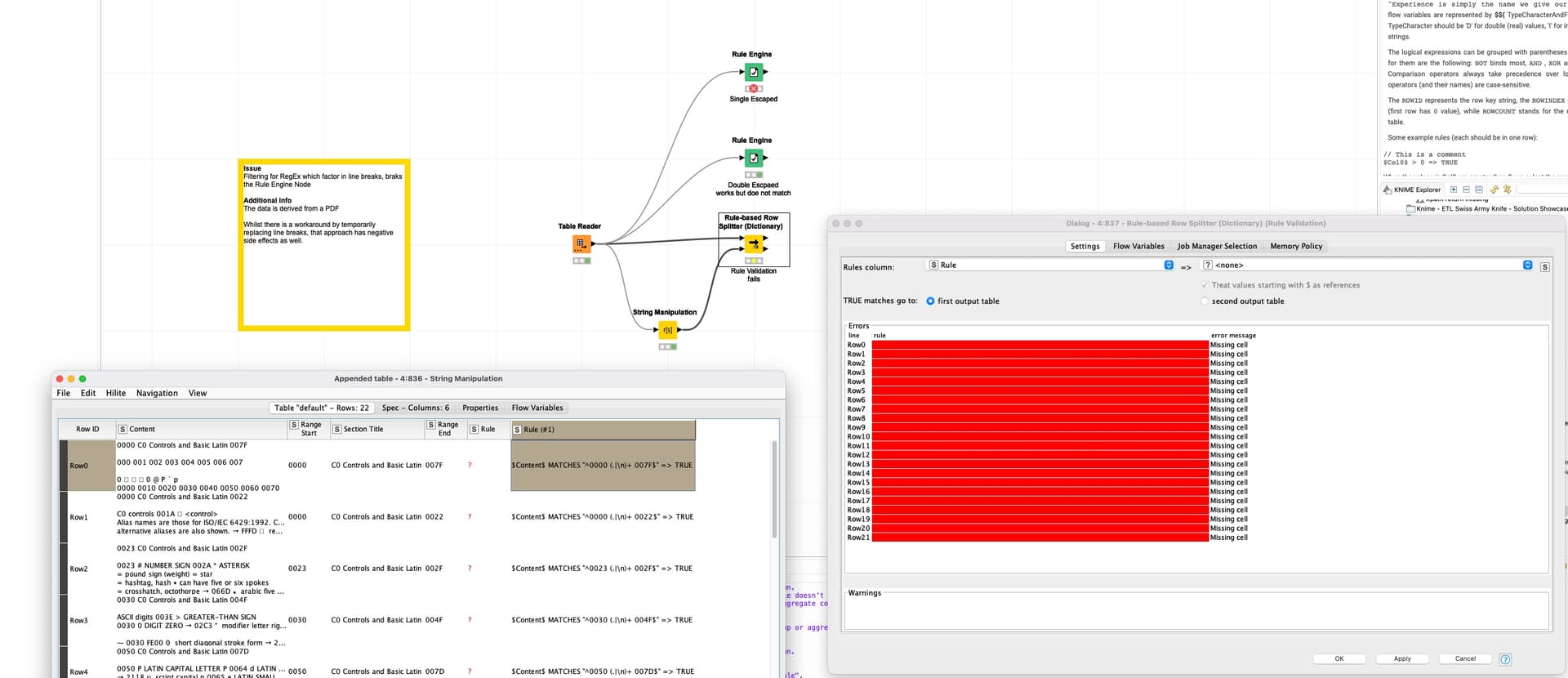
I might have stumbled across an issue in the interpretation of actually escaped (single and double) RegEx line breaks “\n” in all Rule Engine Filter / Splitter Nodes. Maybe even in all as it’s too late to test all scenarios.
Issue
When you have to work with data i.e. extracted from PDF, it often can contain line breaks. Whilst I know about a workaround it’s an unnecessary step and, when working with large data sets, has significant performance implications.
Factoring in line breaks in a rule node like so $Content$ MATCHES "^0000 (.|\n)+ 007F$" => TRUE results in the issues shown in the screenshot below.
This is a general “problem” of regular expression (in Java). By default a regular expression only matches a single line, i.e. you can not match line breaks because they will not be part of the input string. Matching in multiline strings must be explicitly enabled and I’m pretty sure that none of the nodes do this.