Why are you ignoring the workflow I posted? It works.
All my workflow does is extract the 10 rows after your keyword. You need to feed the data to it.
Okay so if I have the data in an excel sheet where would I insert the excel node
Using your workflow would be a lot of work due to the amount of files I have. I have to run my workflow extract all the data and then run your workflow to exclude all the data but the 10 rows under the keyword. I need help figuring out a way to just use one workflow. Sorry for the confusion but the picture I sent where I showed an example of the sheet with all the lines and the keyword 500402 on line 25. That excel sheet is my result after trying to extract the name and address from the picture of the pdf medical bill I have sent. This is why I asked if I could get help just creating a regex expression that I can put to where it only exports the 10 rows under the keyword with my current workflow. I wish I had a test pdf I could send but I do not .
You can do it all in one workflow. Put all of your preprocessing in front of my component. I don’t know why you think regex will be easier. You’ll still face the same issues. You can put the whole workflow inside a loop and read all the files and process them sequentially.
1 Like
So I put your workflow aka table creator and component node. In front of my workflow but I couldn’t seem to connect them. My workflow consists of tika, row filter,column filter, cell splitter,ungroup, row filter and then excel writer. Can you please assist me on how I will connect your two nodes into my workflow? Thanks in advance!
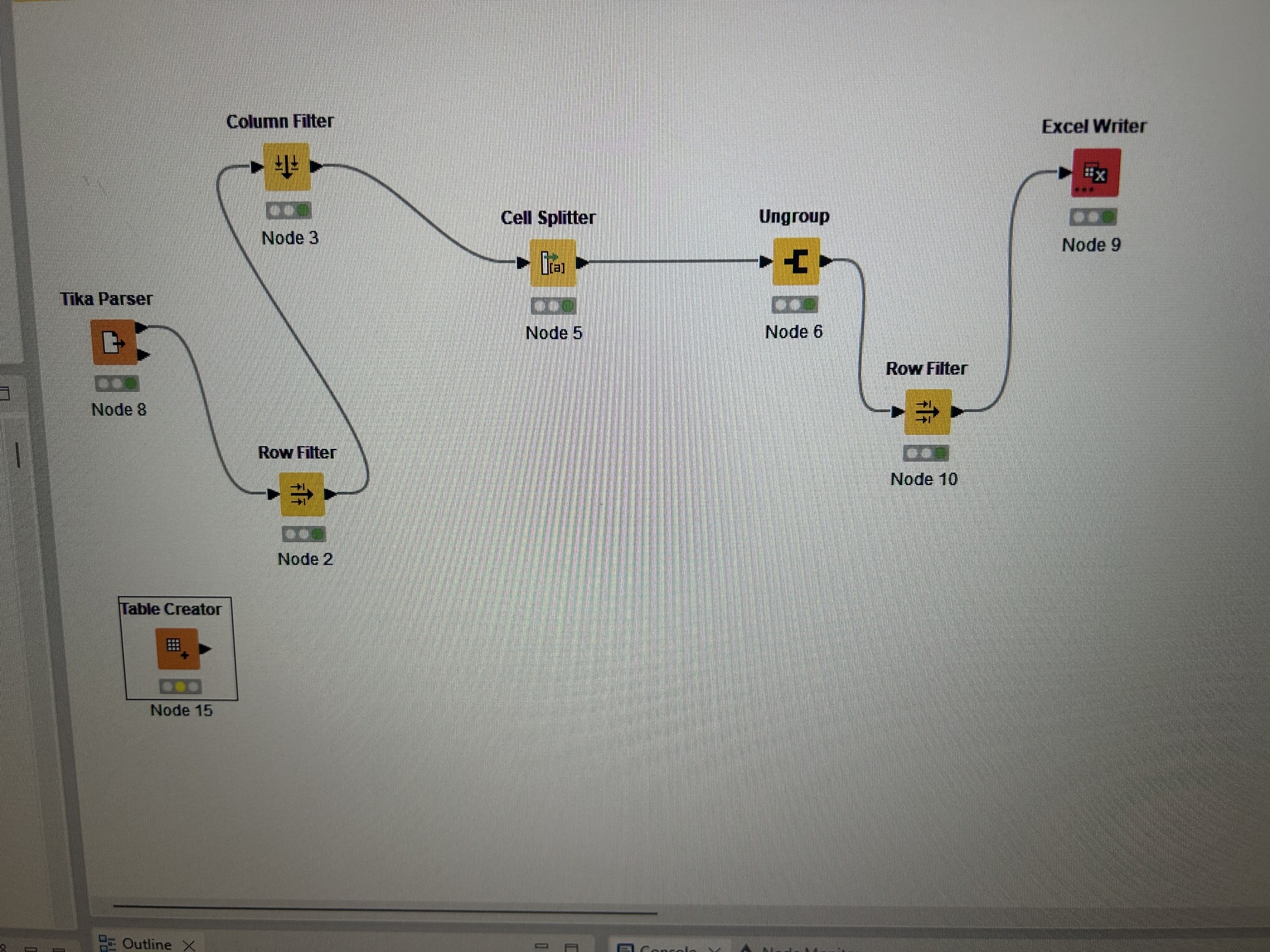
How many pdfs do you have in the folder the Tika Parser is pointed to? You don’t need my Table Creator node. Only used it to create some example data since I don’t have any of yours. If you have a list of Excel files that you’ve created you can point the List Files/Folders node in the attached workflow to it. It will loop through them and create a unified output file.
Multiple. I’m currently trying to do two files. But eventually I’m going to want to do a Bach of 10 or 20 at a time. And there’s multiple pages in the file
It appears from the screenshot of your workflow that you’re writing all the output into a single Excel file. Is that correct?
Yes that is correct. It all will go into one excel file.
You need to write separate Excel files for each pdf. I don’t think there’s any way to reasonably parse a file with multiple input pdfs. Maybe someone smarter than me can help. Its really hard to help you if you won’t (can’t) share some data and your workflow.
1 Like
I’m not sure how to share the workflow but I will try and figure it out tomorrow. Thank you again
Make sure to include some pdfs. You can create a “data” folder inside your workflow and store them there.
Just ignore the extra nodes i have but that is my current workflow, i tried to use extra row filter nodes to filter out the data i dont need, but so far it is not so helpfull.
Hi @NabilEnn , I think you’ve shared your workflow into your private space on the hub. You need to share it to the public folder within your hub space for other people to be able to see it.
1 Like
I shared it to public now. Please let me know if it still doesn’t show up. Thank you.
1 Like
You didn’t include any data. The Tika Parser node points to a local drive. You’ve executed your workflow so the data is available downstream but the workflow can’t be reset without losing the data.
I just reset the work flow.