Further question: in my original workflow when the loop was over I had Quit Driver node. In the original, the browser would close when done with the loop. Somehow in the updated workflow, whether I add quit driver or not, the web browser does not close. Is it because it is a pulled driver node that we used?
Yes and No! You cannot quit a WebDriver which is started by a Get Pooled WebDriver but here we had also removed the WebDriver from the flow before reaching the loop end (to export data to csv).
Here is the new version which quits the browser as well.
Hi Armin,
I have been testing it on the data and ran into an issue. Not sure why but both rows below are intentionally errors and both go through the same path, only John Smith one fails. Can you help?
922897R Jim Bim 877789080 2019/06/24
922897R John Smith R121396592 2019/06/24
This is because the second example produces 2 error messages and therefore 2 rows is created afterwards and the Click node stops with an error.
Solution:
Check the “Extract first match only” option in the configuration window of the Find Elements (node 88 in the workflow I have provided in my previous reply)
I have updated the last version of the workflow in my previous reply.
With your timely and knowledgeable help, Armin, I was able to do exactly what I wanted to do. Thank you, thank you, thank you!!
I was able to set up the same-ish workflow for another website of similar nature. However, I have a few things that I am struggling with and hoping you can help
The attached workflow is not achieving the following:
not handling the error when TQ number is missing (second row in test table);
writes all variables into the table only for TQ record, not other records;
I have noticed that the website may refresh a lot during the time that I am scraping results, so I am wondering if it can also be done differently (get all [span [3]] values at once and then somehow transpose them into columns? I tried but none of collections, and ungrouping don’t seem to work with webelements (or it must probably be my lack of skills).
At the end of the day I want to achieve: entering main number, entering TQ if required, submit the form and if I hit errors just declare “Error” or if I get results, scrape the results and write them into csv. Same as before but with a differently designed website.
Wow, impressive workflow! And kudos to @armingrudd for his awesome support!
not handling the error when TQ number is missing (second row in test table);
writes all variables into the table only for TQ record, not other records;
If I understood correctly, it wouldn’t make sense to query in case of missing TQ numbers anyways? How about just skipping these rows by filtering them out with a Row Filter node? If I misunderstood things, please let me know.
(get all [span [3]] values at once and then somehow transpose them into columns?
At which location in the workflow does this happen? I couldn’t figure this quickly.
Best,
Philipp
PS: Unrelated to your question, but I noticed you’re using several “Wait” nodes in your workflow and a [x] Wait for … setting in following “Find Elements” nodes. You can probably get rid of the “Wait” nodes – the “Wait for” is more intelligent, as it’ll only wait until the desired element becomes available (whereas “Wait” will always sleep for the specified amount of time).
Re: TQ
The main number may be the end of the story, or it may required a TQ code in which case the website provides the TQ field to be filled in and also validates if the provided TQ is correct. So, if TQ is required you need to go through the additional steps, if TQ is not required, the website will not ask for it and just provide the results. All records are needed.
Re: wait
The website responsiveness is inconsistent so I enhanced the wait time with Wait node. For now, I want the main parts of the flow to work. I will look at playing with Wait for after that. Thank you for your reply!
At Node 123 (3rd node in the scrape results portion) the flow finds each values of the innerhtml separately, thus we have many find/extract pairs. I am wondering if we can replace it with one Find and Extract and then deal with row to columns transpormations?
Currently this is the way of doing it. I know that extracting several values is a bit clumsy, and we have some ideas how to provide a “convenience node” which combines several extraction steps in the future. Stay tuned.
Looking forward to some changes
Do you have any feedback on why the workflow does not write variable for all rows? or how to handle the TQ exceptions and proceed?
“Find Elements” returns an empty table, so all following steps are basically skipped. You’ll need to handle the case of an empty table (i.e. no TQ input requested from the site), and in this case make sure, that you fall back to the previous table (i.e. the input to the highlighted “Find Elements”).
Not really. I am thinking that I am relying on the ‘missing result’ and no exceptions. So, I am assuming the workflow should record the result as missing, not return empty.
I have updated the workflow to handle TQ exception (rather awkwardly judging by the time the workflow hangs around that node before proceeding) but at least it does not halt.
I am still not writing data for non-TQ rows and not sure how to fix it. Please help. Maybe updating the workflow will be easier than explaining it to me, I am fine with that too
I’ve actually just discovered a bug in the Find Elements node
In fact, it should not return an empty table when the Return missing values when nothing is found option and the Wait for X seconds maximum, poll every Y ms are both enabled. Thanks for (even if unwillingly) pointing me to that.
I’ve just fixed this and there’ll be a coming v4.0.1 update by tomorrow. This should make it much easier for you to cover above’s case (and even avoid any branch conditions, if I’m not mistaken)
Hello back!
I installed the new version and ran through the workflow again. I have a feeling that some issues have been cured by the new version, although the workflow fails on the 3rd row of sample data on Column Expression (Node 142) for nullpointer. Since I ran into it before and posted a separate thread, I followed on this this specific item back in that thread.
What is also failing for some reason is the setting date and time for the file so it rights a new file each hour. It used to work on my other flow, but when I did a ‘save as’ and changed file name, the date is still stuck on June 28th and all records are being appended to June 28th. Should I post a separate thread for it?
I’d suggest discussing both issues in the “general” forum area, as they’re not Selenium-specific. Anyways, here’s a quick heads up regarding this one:
What is also failing for some reason is the setting date and time for the file so it rights a new file each hour. It used to work on my other flow, but when I did a ‘save as’ and changed file name, the date is still stuck on June 28th and all records are being appended to June 28th.
You’ll need to make sure, that the corresponding nodes are getting reset when executing the workflows. If you do not reset them, they’ll simply keep the value from the last execution (i.e. the old date).
Hint: You can make use of “dummy” flow variables to reset these nodes before writing the CSV file. Therefore add a flow variable connection from the input node before the CSV Writer to the first node which builds the current date.
Hello Philipp,
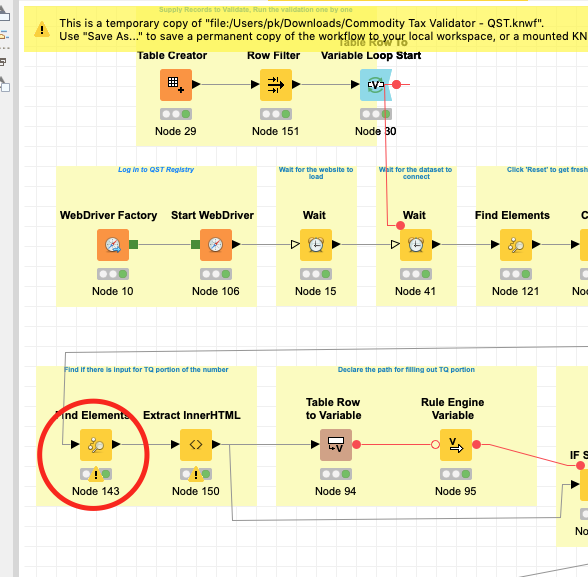
The node ExtractInnerHTML for one of the rows is extracting ‘innerHTML’ and ‘innerHTML(1)’, which throws off the Loop End as it expects 30 columns and now gets 31 columns. I am not even sure where the Loop End node gets 30 or 31 colums as I defined only 9 columns. Can you point me in the right direction? I am not interested in what ‘innerHTML(1)’ brings…The offending record is ‘TQ form - error’ in the input table. The updated workflow is attached.Commodity Tax Validator - QST.knwf (119.9 KB)
Actually, one node should only extract exactly one column. The (1) suggests, that there was a column with that name before, and the new one was renamed due to the naming conflict. So I assume this was generated by a predecessor node? Could you double check this?