Is there a way to use a scorer node to show the accuracy of the unsupervised learning approach without using the category to class node when working with unlabeled data?
I suppose it’s possible to use Comprehend in this way, I just don’t understand why you would want to. If you train a model in KNIME based on tweets labeled by Comprehend, you are building a model based on results of a model. Why not just Comprehend only?
On your question about labeling using Java Snippets, I’d have to see the example you’re talking about, but It sound fairly simplistic.
2 Likes
By definition, when using the unsupervised approach, you don’t have the ground truth for your data. As a result, the Scorer doesn’t having anything to work with, because it compares ground truth (in this case, sentiment labels) with model predictions to create the summary statistics.
If you are determined to calculate accuracy metrics, you may have to dedicate some time to manually labeling a subset of the tweets yourself. Sometimes that’s unavoidable.
3 Likes
Thanks again for the clarification. Could you help me regarding a problem in my workflow. I don’t understand why terms like “afghanistandisast” are not showing up correctly and is tagged with positive sentiment. I also have terms like “http” and square symbols which are included in the BOW. I have tried to use Regex filter, but without any luck. Almost each tweet is tagged with positive sentiment, which should be the opposite since most of the tweets are negative.
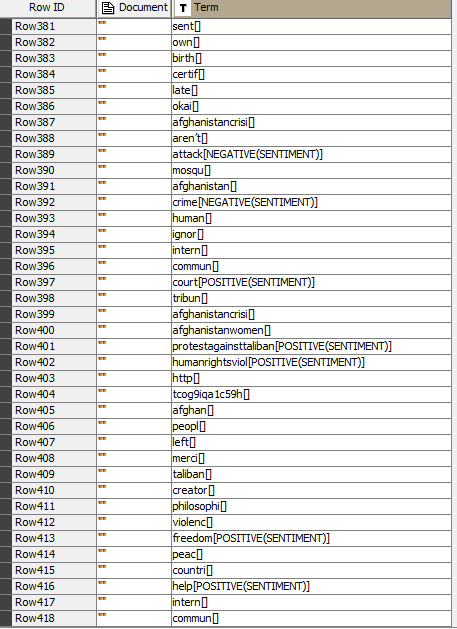
Can you post the latest version of your workflow? It’s difficult to diagnose what might be going on based on the screenshot of a table.
Hi again, I’m sending my workflow. I simply don’t know why urls, non-english strings, emojis are present in the BOW even after using RegEx and also some white square symbols. And why some terms are tagged incorrectly. I think I tried dozens of regex formulas but nothing seems to work. Could you please help me with this issue? Text Processing.knwf (2.8 MB)
Hi @Huseyin -
I’m not a RegEx expert, but the reason things might not be working as you expect is because you’re doing a lot of your filtering last in the series of nodes. For example, this might cause your RegEx to fail if it’s looking for http:// since it won’t find the slashes, because they were already removed by the Punctuation Erasure node. So a simple thing you could try would be to move your filtering nodes ahead in your workflow.
Apart from that, if you want to remove hashtags, I think that would require a separate RegEx. If you want to remove emojis you could try this component from @takbb prior to converting your tweets to documents: String Emoji Filter. I’m not sure why you would expect non-english strings to be removed, since as far as I can tell your workflow doesn’t do that.
It might also be worth stepping back and looking at this from a “10,000 foot view” - if your main consideration is sentiment classification on unlabeled data, then a lot of the extra mess you have (non-english words, URLs, etc) aren’t usually going to affect the results much, since you would primarily be counting words of a particular sentiment type anyway.
2 Likes
Yes, using RegEx earlier in the workflow gave better filtering results. And in fact that some URLs and non-english words are present should not make so much difference to achieve my goal for sentiment analysis. Thanks for your patience! I’m very grateful for your help and support.
BR,
Huseyin
1 Like
Is there way to increase the accuracy of the Naive Bayes classifier or any other classifier for imbalanced data? My accuracy with Decision Tree is 62% and 60% with SVM i, but 1.2% with NB classifier. Even though SVM and DT accuracies are not so good either, it’s somehow acceptable. I’m doing multi-class classification btw. This is my NB workflowNaive Bayes Classifier.knwf (2.8 MB)
I wouldn’t worry about using NB here at all, honestly.
To deal with class imbalance, check out this thread (and the threads linked within it) that give you several options:
1 Like
I tried using SMOTE on the training set, but got a bit worse accuracy with the XGBoost Classifier, but maybe my problem is caused by too small dataset? I also have a problem with the snowball stemmer, since some of the words are not stemmed correctly. Also is there an alternative ROC curve for multi-class classification?Sentiment Analysis.knwf (3.1 MB)
This topic was automatically closed 90 days after the last reply. New replies are no longer allowed.