Looks like it’s this one: Sentiment Analysis with Integrated Deployment - Training – KNIME Hub
I’ll check it out.
Looks like it’s this one: Sentiment Analysis with Integrated Deployment - Training – KNIME Hub
I’ll check it out.
I think I found the problem. It turns out that this workflow is hardcoded in a couple of other places to reduce the words to 80.
Inside the Zero Pad component there is a Column Filter node. The additional columns need to be moved into the green include box:
Something similar needs to happen in the Create Collection Column node that occurs immediately afterward.
Now having said all that, you need to set a cutoff (say 2400) for your number of words per document and make sure all the other relevant nodes we’ve discussed here correspond to that value. As it is, none of your documents have 3000 words (the max is 2456) so that setting was too large for the Keras Input Layer anyway.
When I make the above changes I’m able to start training with Keras. Note that your training set size is pretty small, so you will probably want to make some changes to the batch size in the Keras learner. If you have more data for training, you should use it - deep learning approaches often require large datasets to produce useful predictions.
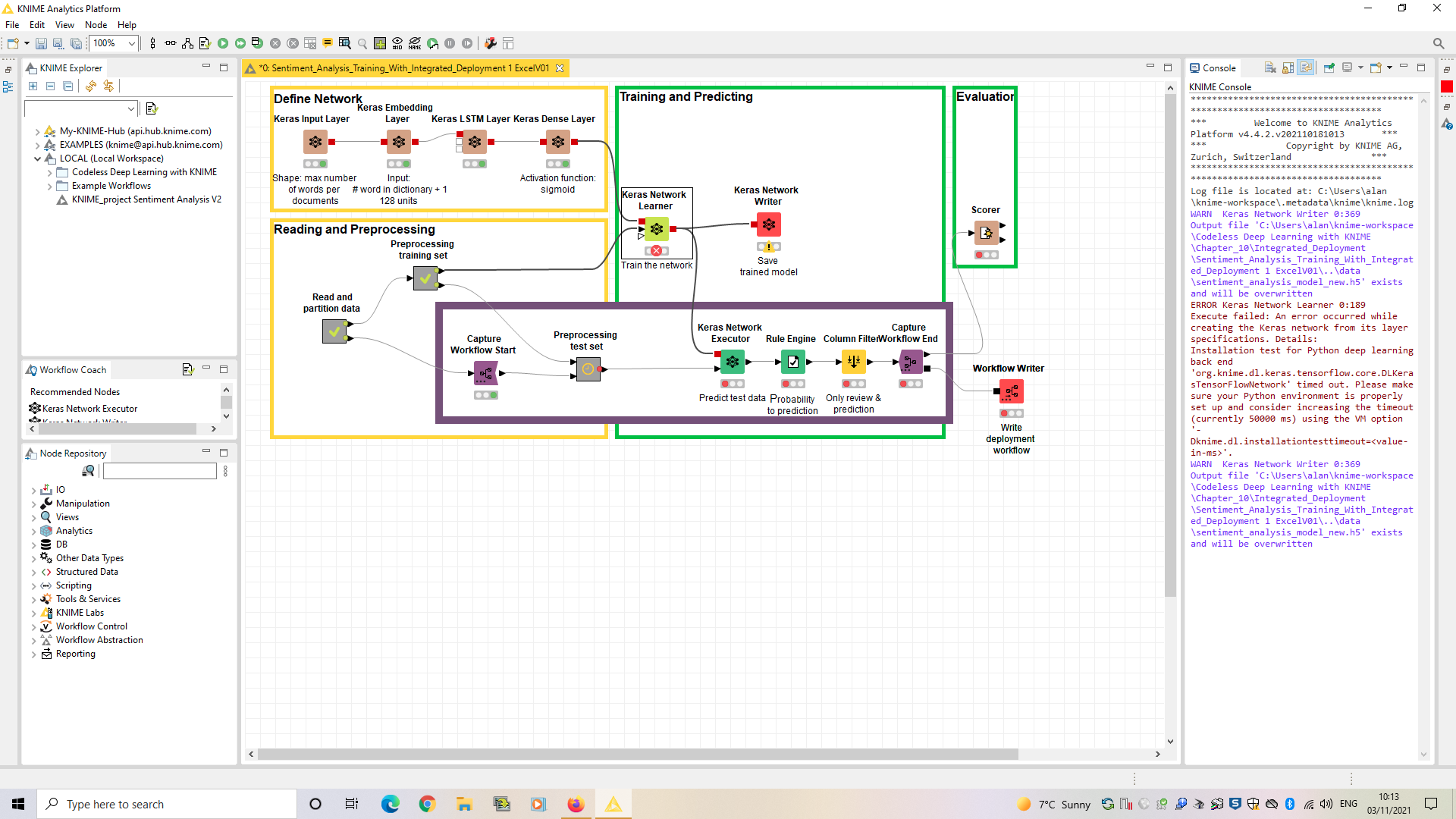
The execution seemed to go further this time, but still hit an error, screen shot below:
Looks like your image wasn’t uploaded - at any rate, I can’t see it.
Looks like the same error you had before. Can you check your timeout settings to make sure they are still being applied?
Thank you Scott.
I increased the timeout and it solved the issue with the Keras Network Learner node.
Unfortunately another issue occurred with the Keras Network Executor node and I cannot see how to change the shape size from 80 to 2400.
Please help.
Something is wrong with your screenshot again. It would probably be better for you to upload the workflow itself anyway, as screenshots are of limited use.
Did you already make the changes I suggested above to fix the dimensions of your incoming data?
I made the changes you suggested to fix the dimensions of incoming data. This seems to be an issue with the Keras Network Executor node and I cannot find the place to fix:
That link is to your local repo. If you could upload to the Hub again as before, that should work.
I have uploaded the work flow to the hub. Please let me know if you can see it.
I can see it.
Long story short, you have to make the same changes I described above for the “Preprocessing Training Set” metanode in the “Preprocessing Test Set” metanode as well. When I do that for your workflow, the Keras Network Executor is able to run OK.
I have made the same changes to the “Preprocessing Training Set” metanode and the “Preprocessing Test Set” metanode which changed the shape size as recommended but I cannot get the Keras Network Executor to execute fully.
The error showing in the KNIME Console is - “The input shape does not match the tensor shape. [2405] vs [2400]”
I have looked everywhere in the workflow but cannot find the cause.
Please help.
Hi @stockdaa - upload your latest version to the Hub and I’ll take a look at it.
I have uploaded the workflow, latest version.
I have uploaded the workflow to the hub. Please let me know if you can see it.
I can, yes. Sorry for being away from the thread for a few days - I’ll take a look.
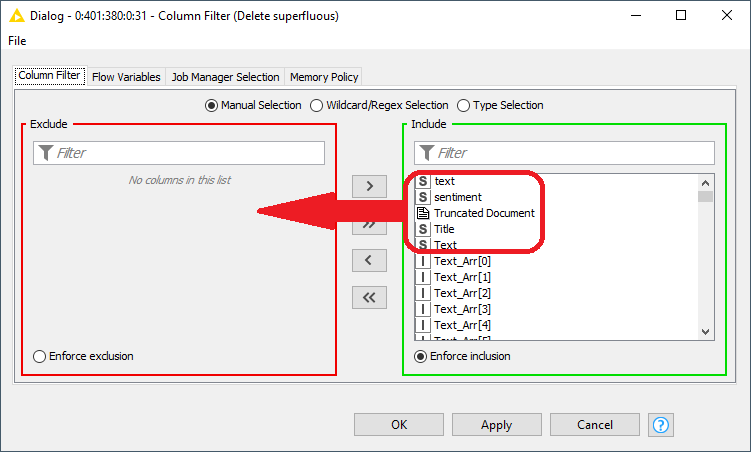
So, in the Column Filter nodes inside the Zero Pad components (which in turn are present in both the preprocessing metanodes), you have something going on like this:
Basically, you have too many columns coming out of this node, which is why the error message is complaining about 2405. Another way to fix this would be to use the Wildcard/RegEx Selection option of that dialog to include only records that match Text_Arr*.
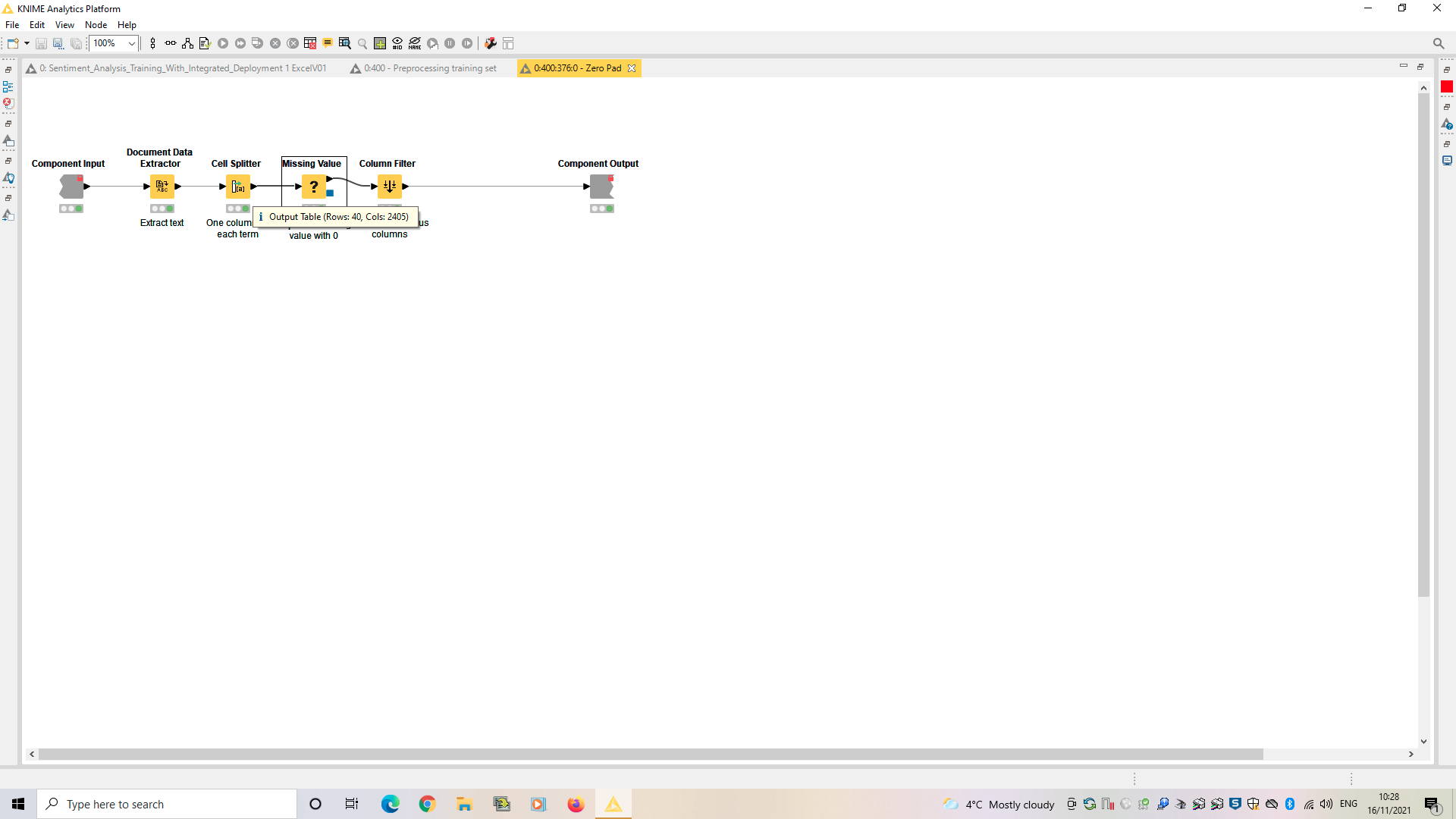
An easy way to check the dimensionality of your dataset and track down where a problem like this might be is to mouse over the output ports of various nodes and components until you find the suspicious number, like this:
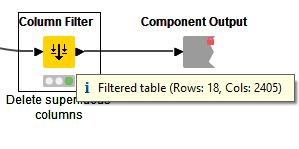
Hope this helps - let me know if you have further questions.
I just started checking the dimensionality of the output ports and found a mismatch in the cell splitter node, but I cannot see how to change it:
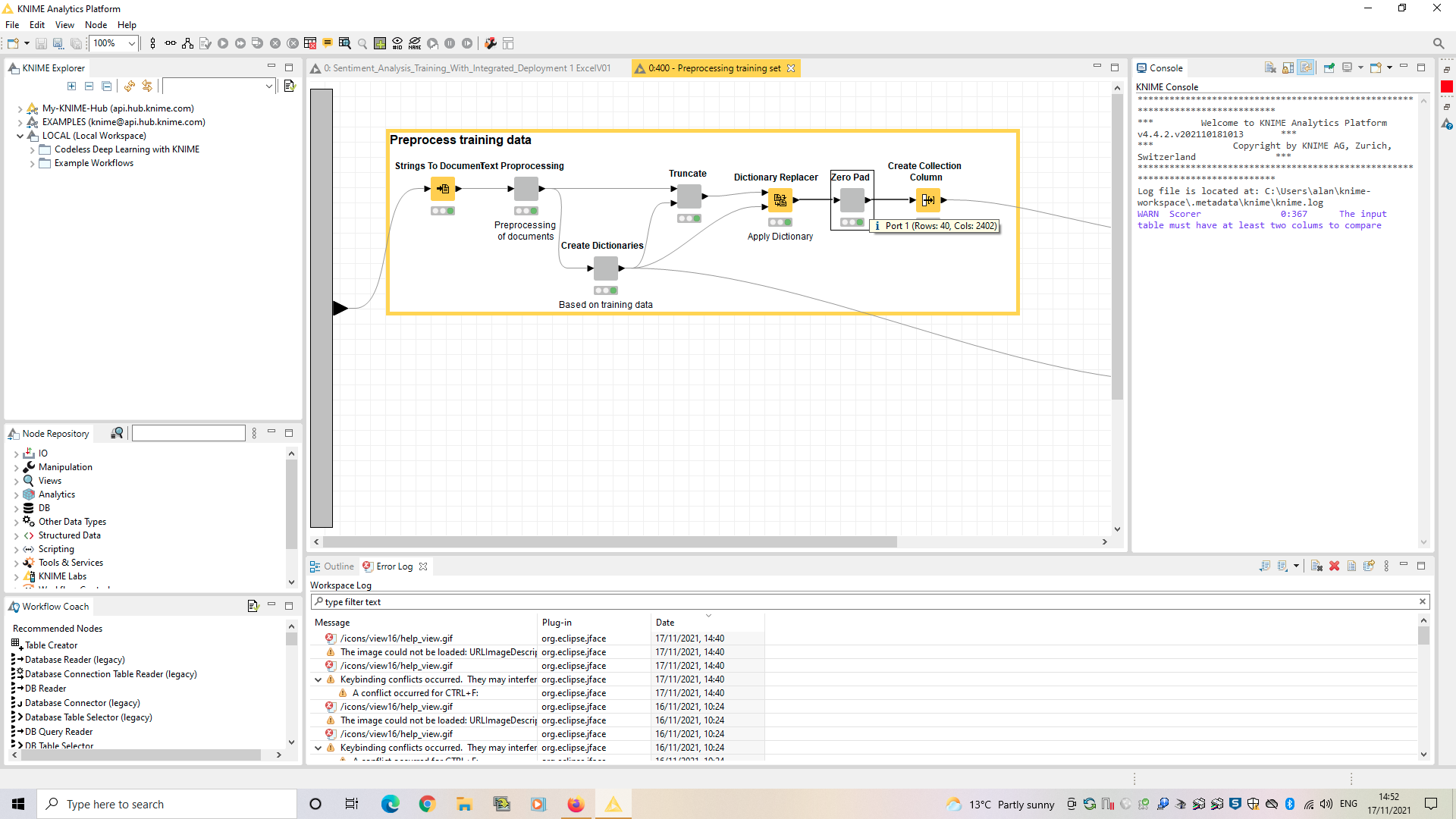
In the Preprocessing Training data section of the workflow, the number of columns changes from 3 to 4 for no apparent reason, between the Strings to Document Text node and the Preprocessing node.
In the Zero Pad node the number of columns jumps to 2402
The shape size was set at 2400 at the start of the workflow.