After looking, it’s not clear to me why the size of your tensor shape is smaller after you added new records. As a workaround you can adjust the size of the tensor in the Keras Input Layer from 2400 to 2329 to match, since those numbers are somewhat arbitrary anyway.
Also, I don’t know that going from 40 to 80 input records is enough to produce more accurate results, but I can it can’t hurt to try.
In the future, please post the actual error messages you are seeing in the console, as well as a link to your workflow on the Hub. Otherwise no one else is available to help solve your issue, and may not even be able to decipher the problem you are having. More information is always better than less!
The Keras Network Writer problem is solved by changing the path to a local one on your machine (I used C:\tmp\ just to test it out).
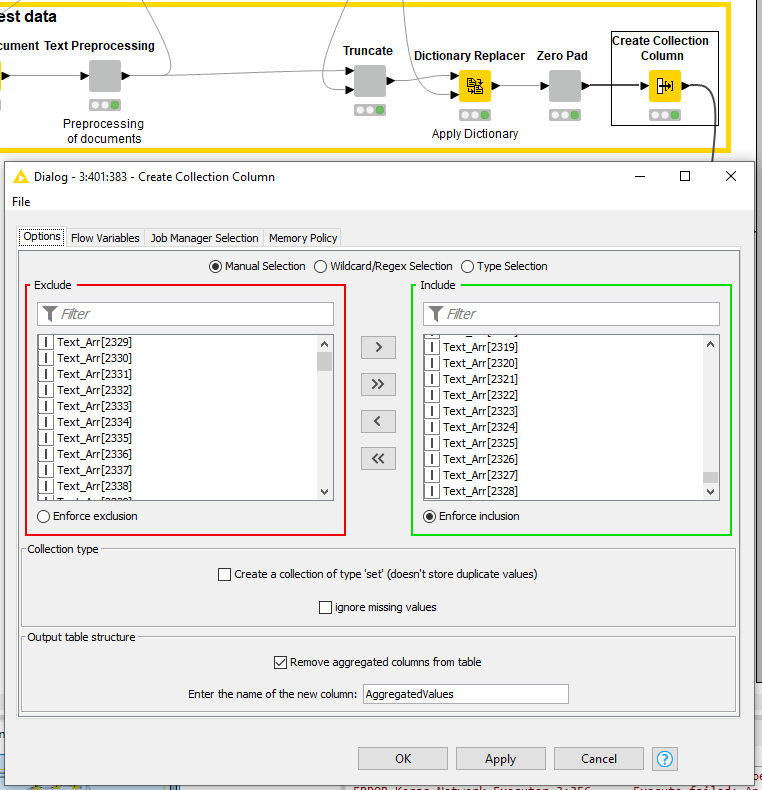
The Executor is failing again because your the dimensions of your trained model [2329] don’t match the shape of the tensor in the test set [2400]. This indicates that something in the test set preprocessing is being handled differently than the training set. I was able to get this to work by removing all the Text_Arr columns after 2328 in the Create Collection Column node but this is a bit of a hack; it would better to understand why the dimensions are changing in the first place, which I still don’t.
This issue is very similar to the dimensionality issues we discussed back in November. In both cases, this is going to require you to dig into the metanodes to make some changes. I can come alongside you to help fix the errors as they pop up, but it would be beneficial if you take time to really dig into each node inside the metanodes and understand what they are doing, with an emphasis on what might be changing when you updated the original input files.
Having said all that, the predictions using this dataset still all have the same probability (0.522), and therefore all the model predictions are for sentiment = 1. My original impression still holds, which is that 80 total rows isn’t enough data to train a deep learning model with.
It might be worthwhile to check and see if you can get reasonable results using (much) simpler ML methods, like a random forest. We have workflows for other classifiers available on the Hub as well.
Thank you for the workaround.
I cannot see how to attach the deployment workflow to the Workflow Writer node, as there are no output ports to connect to.
You are not intended to attach the deployment workflow to the training workflow so that they exist all together in a single workflow. See my post #49 above. They are supposed to be be run independently from one another:
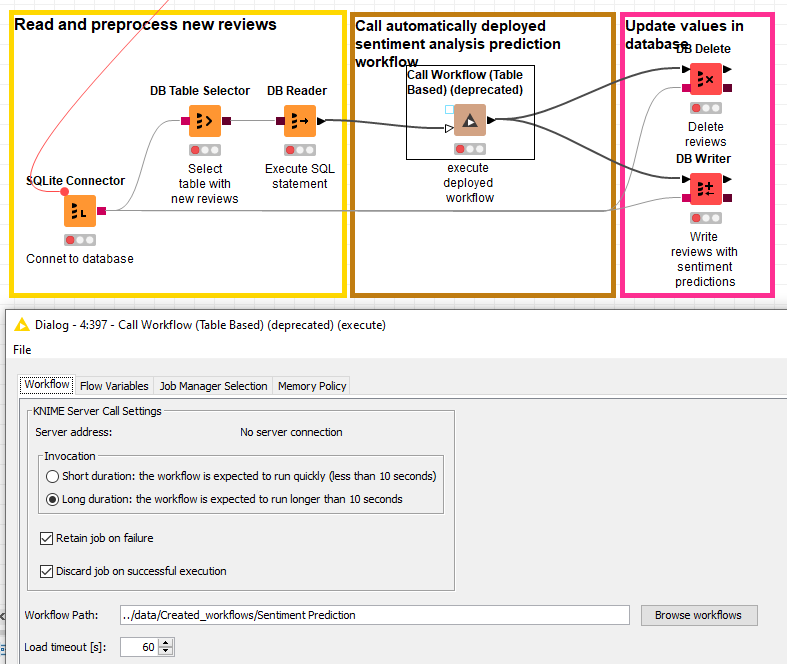
The training workflow takes your data and trains a model for predicting sentiment. It writes out a sub workflow to ../data/Created_workflows for this purpose.
The deployment workflow reads in new data and calls the sub workflow created above to make predictions, using the Call Workflow (Table Based) node, and subsequently writes those predictions to a database.
I have tried to connect a new database for sentiment analysis based on an Excel spreadsheet file, to the deployment workflow, rather than a Knime table format and this does not work.
What do I need to change so that the deployment workflow will read the Excel spreadsheet?
Replace the Table Reader with an Excel Reader pointing to your file.
If all you want is to see predictions on the new data and don’t care about reading/writing to a DB, you can get rid of all the other nodes having to do with DB operations and just connect an Excel Reader to the Call Workflow (Table Based) node.
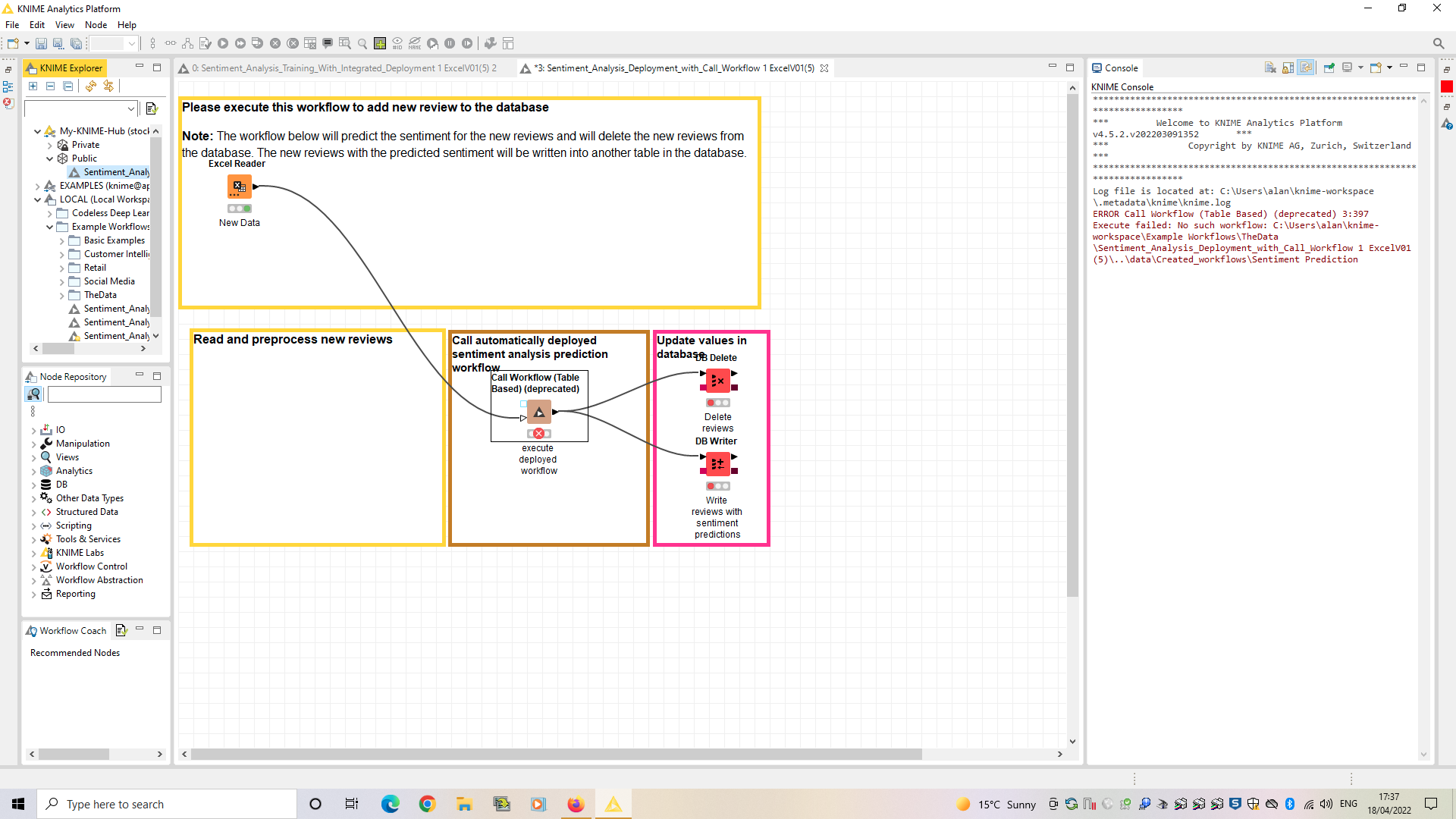
I have pointed my workflow at the deployment workflow, by selecting it from the list presented in the configuration window but it does not work. Please see error message below:
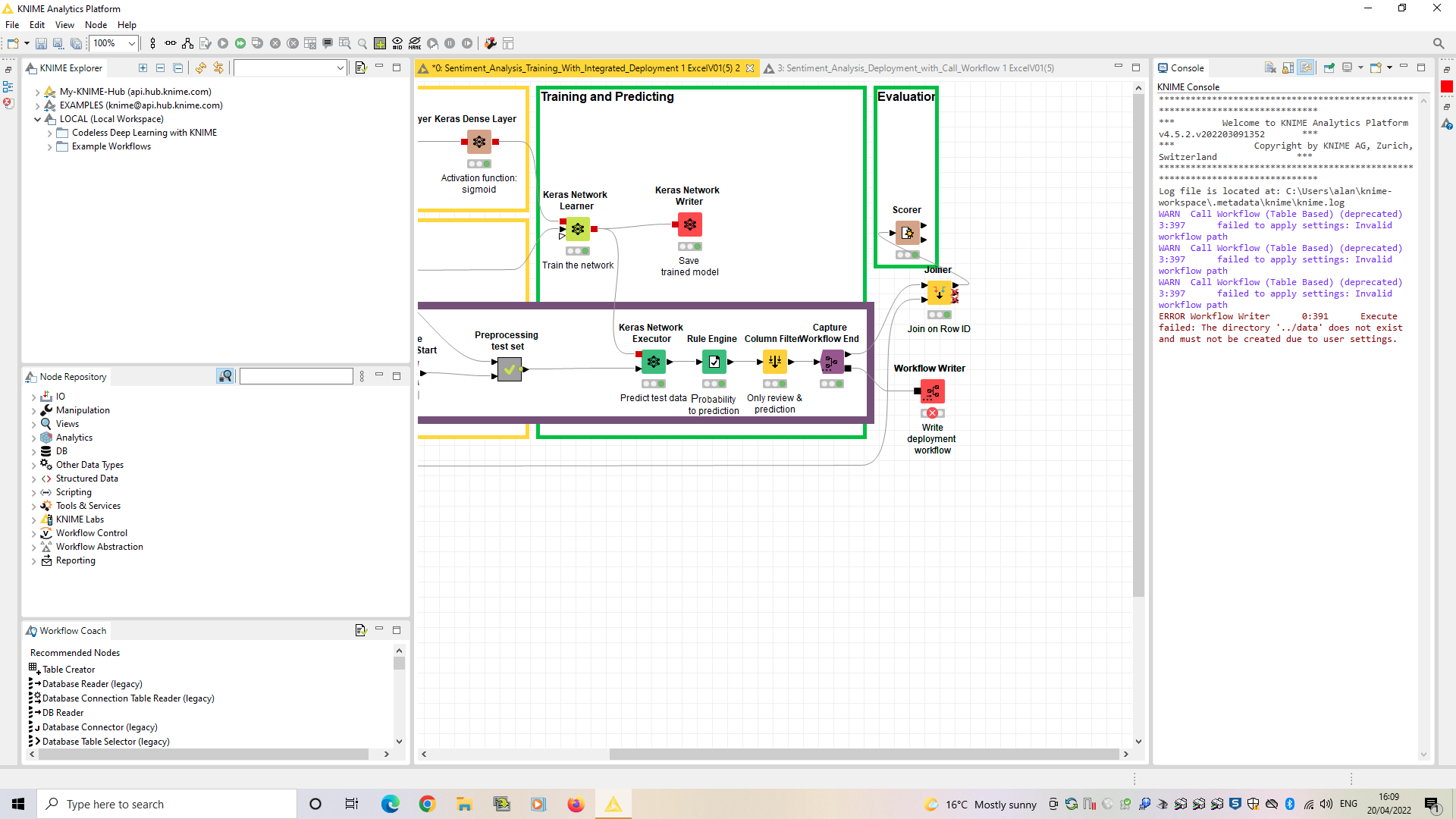
The error pretty much tells the story here: the Call Workflow node can’t find the workflow it is trying to call at the path given. You need to make sure that the Workflow Writer in your other workflow, and the Call Workflow node here, are referencing the same path on your system.
Please carefully check the node options based on the error message. From the node description:
Create missing folders
Select if the folders of the selected output location should be created if they do not already exist. If this option is unchecked, the node will fail if a folder does not exist.
Most likely you need to set that option in the node, but it’s hard to tell from screenshots alone. As I’ve mentioned before, you should upload your actual workflow to assist with the troubleshooting process.