Maybe I am watching this naively, but is my understanding that a curve passing trough n+1 points, can be interpolated by a polynomial of nth degree maximum, which means that if I wanna make a regression of the nth degree, I need n+1 (independent) rows in my database.
So, I am using the Polynomial regression learner node and would expect that with n+1 rows, I can set the value “Maximum polynomial degree” up to the value of n ( “extract table dimensions” + “math formula” with n=numRows-1).
Instead, the node gives an error everytime the rows are less than n+2.
e.g with 5 rows and Maximum polynomial degree set to 4, it returns the error “not enough data (5 rows) for this many predictors (5 predictors)” ??
Just a clarification question: is my understanding correct that your dataset consists of 5 rows, you are including 1 independent variable, and have the polynomial degree set to 5?
Also note that using a the maximum degree will often overfit the data.
We can see these from a specific way and a more generic one.
Specific - Wanna perform a 3 degree polinomial regression. Here my dataset in is variable: sometimes is 4 rows, sometimes is 10, other times is 30 rows, etc… After few loop cicles, a datasebase with 4 rows came.
So there was 4 rows and polynomial degree set to 3. In the dataset there were a column Y (dependant) and a X (independent) one.
I was paceful that would work, but instead it stopped with error message "not enough data (4 rows) for this many predictors (4 predictors)”.
During another loop cycle with just 5 rows, it instead worked flawlessy.
Generic - for my understanding, if I have, e.g., 5 data points (X,Y) I can mathematically (paper and pen!) perform a polynomial regression of maximum 4th degree. With 4 data points, max is 3; with 10 data points, max is 9; and so on with n+1 data points, max is n-th degree (gap of 1).
Using this node instead, you need n+1 data points to achieve max n-1-th degree (gap of 2). This quite looks like a bug to me…
sorry for the late answer, I totally missed you reply.
Actually, that doesn’t really matter. It presents the same bug (I am quite confident in calling it by name now…) whathever data I input.
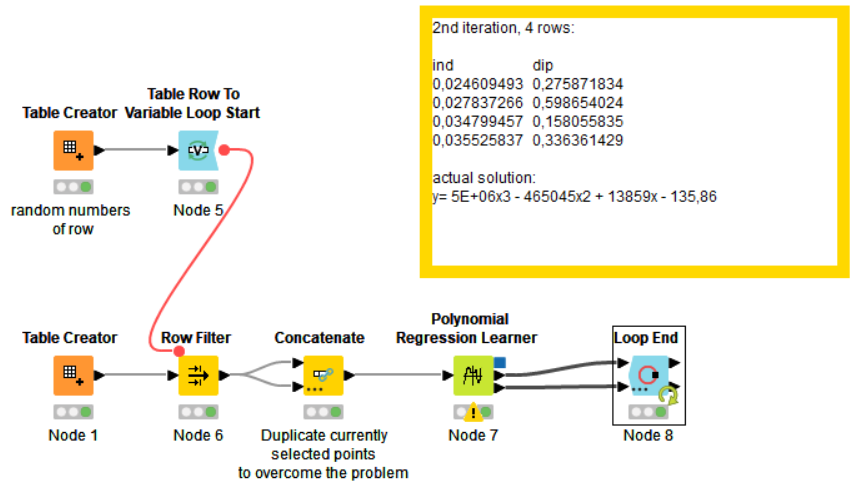
As title of example, I reproduced the situation in this microflow, where all the numbers are litterally taken at random:
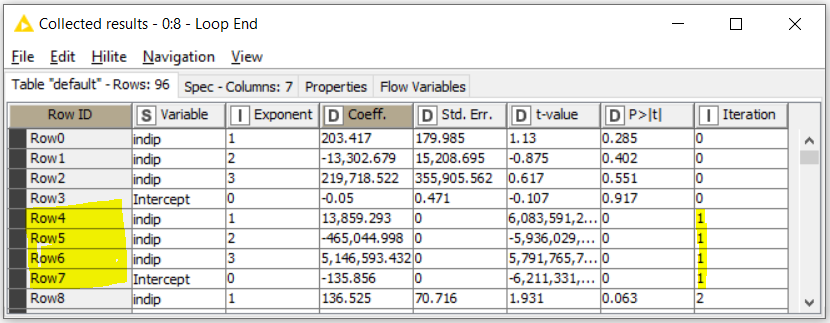
The first iteration provides the node with 6 rows, and no problem here; but the second iteration has 4 rows…the required max degree is set to 3, so it should work (in the note I wrote the actual solution, calculated by excel); except, when you run the loop step by step you can see it is not doing his job.
No problem at all and thanks for your reply. I was asking for a -failing data example- because it really helps sometimes to spot where things fail instead of just guessing. I’ll have a look and come back to you asap with a possible answer.
I believe the reason why the -Polynomial Regression Learner- node needs -one extra point- is because the node is not just calculating the regression coefficients of a polynomial equation of order (n-1) with n points. In fact, it is also calculating statistics on -training errors-. The only way of calculating this is by having an extra point and not only doing a single polynomial model but several by computing a Leaving-One-Out scheme and building statistics on the leaving-one-out points.
Hence the need of an extra point. Without the need of calculating statistics, the extra point is not needed, otherwise it is I’m afraid.
I do not see how to bypass this problem apart from using another algorithm that does not compute statistics.
Edit from initial post:
I way of proving what I said before is to duplicate your points so that the algorithm always has at least one example of all the points even if statistics are calculated by LOO. If I do that, you can see below that the node correctly calculates your coefficients for the 2nd iteration which used to fail before:
Duplicating in this way your points maybe a trick to bypass the problem and lure the -Polynomial Regression Learner- node if you are happy with it. The only impact this may have is that the resolution of the polynomial system of equations get slightly bias by the presence of point duplicates but the impact should be marginal and not higher than the impact already the LOO scheme has on the polynomial matrix resolution.
Hope this clarifies the issue. Otherwise please reach out again.