Is there support for KNIME Analytics Platform 4.0.0. and Spark Job Server ?
I have upgraded the platform to 4.0 and using Spark 2.3 on the CDH cluster. Tried installing the generic tar available for 3.6 version from the site and it have me errors. Not able to create the Spark 2.3 Context.
I guess the recommendation is to connect from KNIME is using Livy service, however, the way I’m currently using Spark functionality is sending ssh commands with spark-submit (using External SSH Nodes) and I would like to stick to it.
If job server is not possible for Spark 2.3.0, is there a way to send spark-submit commands (with External SSH Nodes) with Livy Service ?
as you already mentioned, we recommend Livy and do not support the Spark Jobserver anymore. In addition I would suggest to update to a more recent KNIME version.
Can you explain what commands are you running or how your setup looks like or add some example workflow? I don’t understand how you get the KNIME Spark nodes and Jobserver working using spark-submit commands via SSH. If you use SSH to tunnel the Jobserver HTTP port, than you can do the same with the Livy HTTP port too.
Hi @sascha.wolke
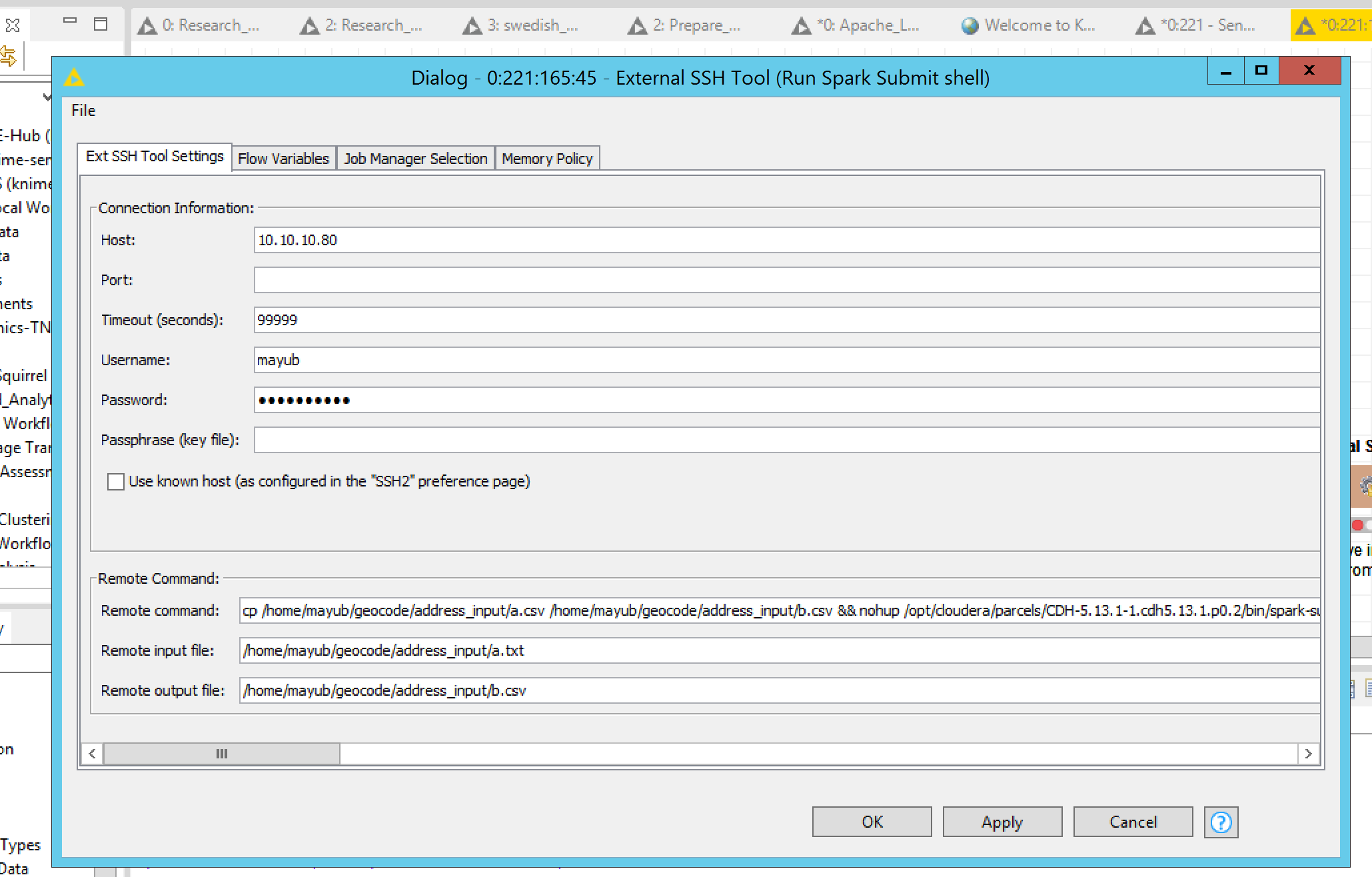
Thanks for your prompt response. Sorry for the confusion, I’m not using any of the Spark Node in my workflow. Just using the External SSH nodes like below:
Chaining SSH commands in the pipeline, 5th External SSH Node runs the spark submit command on the gateway node.
Summary of the above command - basically it’s calling spark-submit with a jar file and passing class arguments to the file along with some custom spark configurations to override them and storing it in a log file.
Let me know if it’s not clear, i’ll try attaching part of the workflow
Would be good to know if there is an equivalent in Livy to do the same.
there is a project called Spark-Jobserver that we used to connect the KNIME Spark nodes and the Spark cluster a long time ago, but we now recommend using Livy.
Looks like you are using Spark, but no Spark-Jobserver There should be no problem to run your SSH/spark-submit commands as you do not use any spark node.
We have a Livy parcel if you like to try the Spark nodes, if not, running spark-submit should work independently of the KNIME version.
Thanks @sascha.wolke. SSH/Spark-Submit works fine for now.
I actually tried the Livy Setup from the Admin Guide you sent. I got NullPointerException using the Livy service along with external jar files. This seems to be a Open Issue https://issues.apache.org/jira/browse/LIVY-636 .
This was one reason why I wanted to see if SparkJobServer and Spark 2.X would work instead. But that’s fine. I think I can work with SSH/spark-submit route for now.

 There should be no problem to run your SSH/spark-submit commands as you do not use any spark node.
There should be no problem to run your SSH/spark-submit commands as you do not use any spark node.